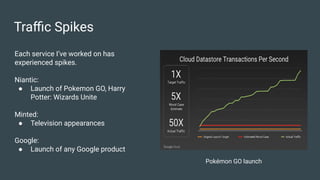
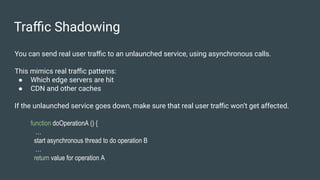
Niniane Wang discusses key strategies for optimizing the scalability of technology systems based on her extensive experience in engineering at companies like Niantic and Google. The document outlines effective load testing methodologies, handling unexpected traffic patterns, managing third-party dependencies, and making critical architectural decisions to prevent bottlenecks. It emphasizes the importance of proactive planning, aligning vendor incentives through SLAs, and knowing when to re-architect components for better performance.