Downloaded 132 times


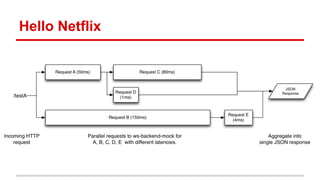



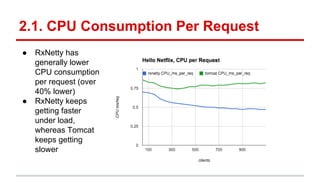
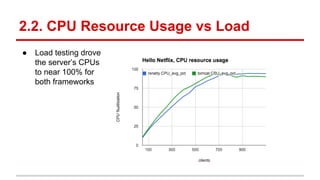
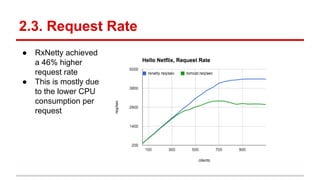
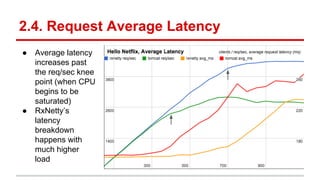
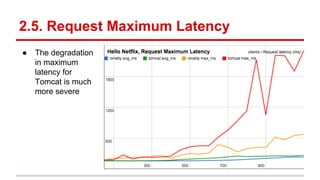





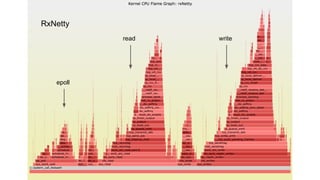


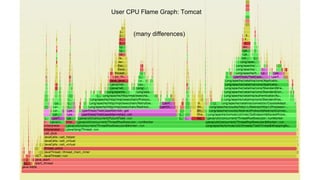


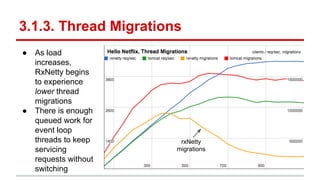
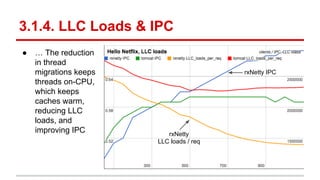
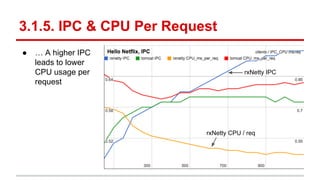





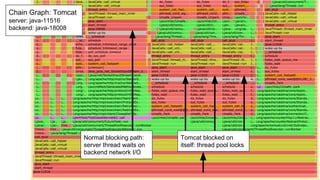


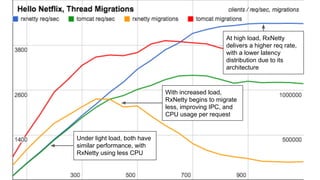

The document compares the performance of RxNetty and Tomcat based on the 'Hello Netflix' benchmark, demonstrating that RxNetty generally outperforms Tomcat in terms of CPU consumption per request, request rate, and latency under load. Specifically, RxNetty shows over 40% lower CPU consumption, a 46% higher request rate, and better latency distribution as load increases, while Tomcat experiences significant degradation in performance with high load. The improved performance of RxNetty is attributed to its event loop architecture, which reduces thread migrations and GC overhead.





















































































