








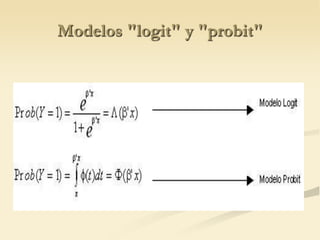
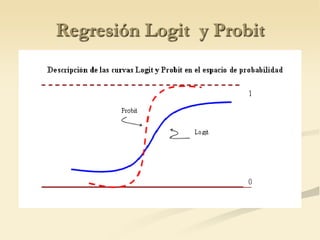








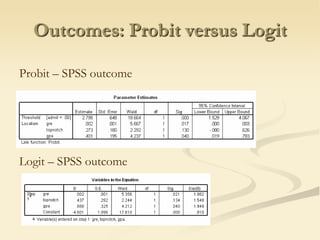
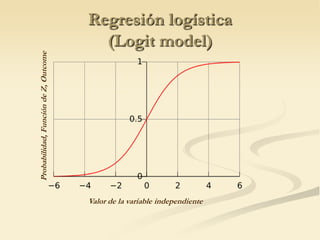



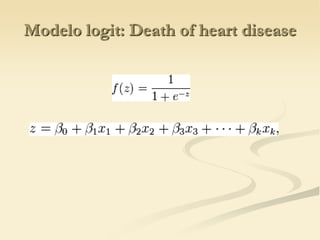


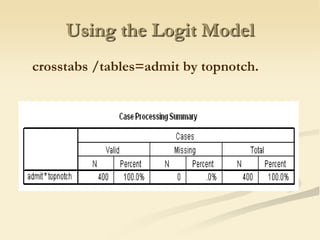
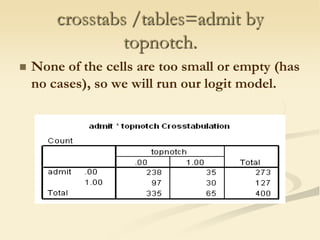

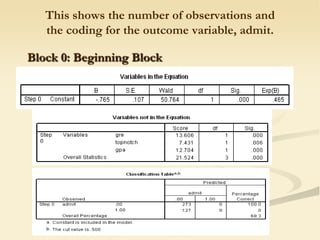


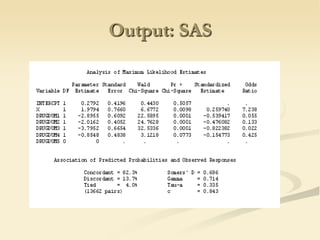

The document discusses logistic regression models for binary outcome variables. It provides examples of logistic regression analyses to predict the probability of heart disease, election wins, and graduate school admission. The key differences between logit and probit models are explained, where the logit model transforms the dependent variable using the logit function and probit uses the inverse of the standard normal cumulative distribution. The outputs of logistic regression analyses in SPSS and SAS are also reviewed.





















































![ONFH[AVN HIP] -TRIPLE REGIME -A NOVAL SURGICAL CONCEPT .pptx](https://cdn.slidesharecdn.com/ss_thumbnails/onfhavnhip2026koaconcalicutdrgokuldevdrmashraf-260210064517-213ec005-thumbnail.jpg?width=640&height=640&fit=bounds)










![PERI-PROSTHETIC FRACTURE NAIL-PLATE CONSTRUCT [NPC].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/drarunkumardrmohamedashrafperiprostheticfrasturenail-plateconstructnpc-260209164459-7e9d15a1-thumbnail.jpg?width=640&height=640&fit=bounds)


