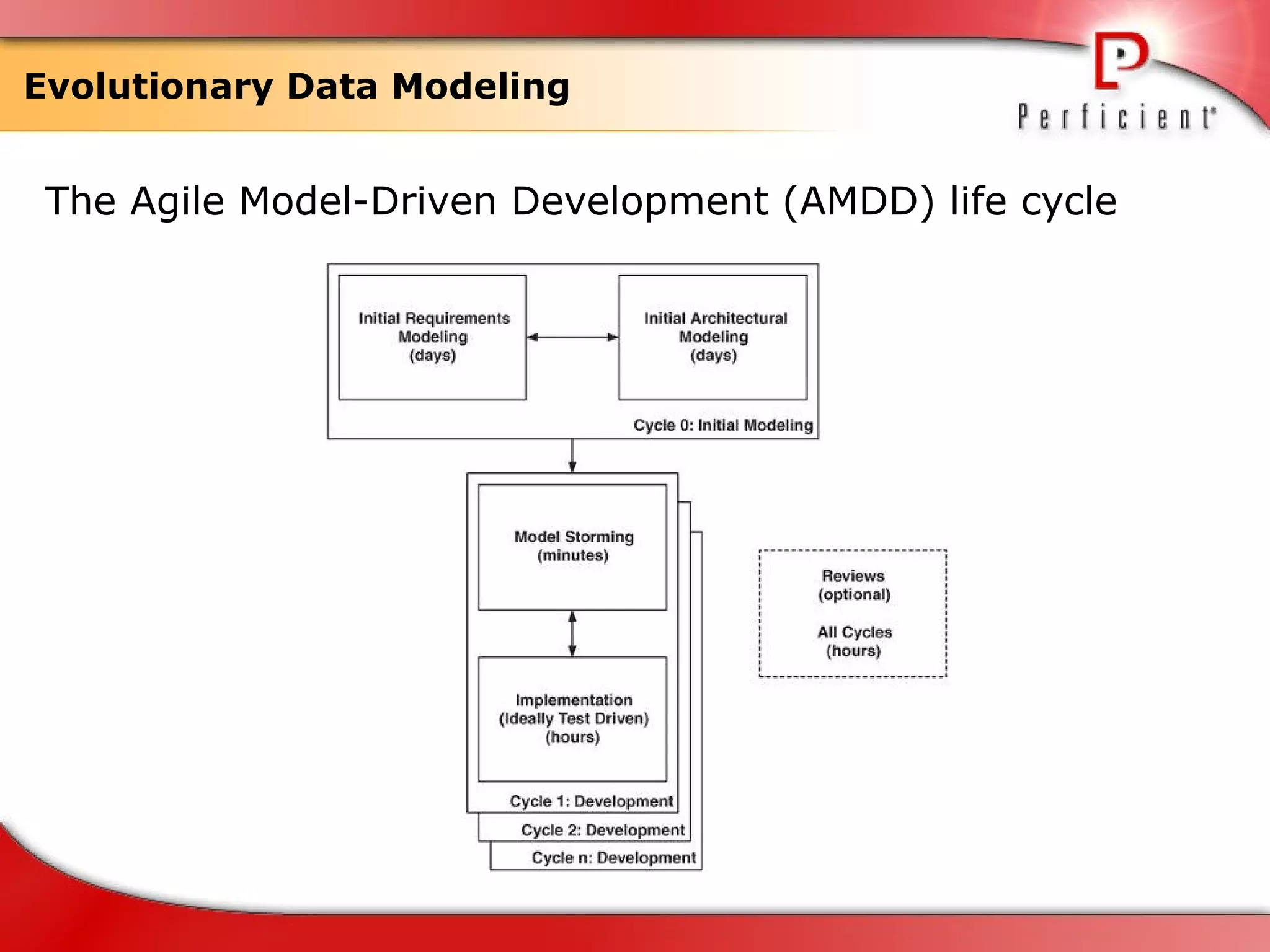
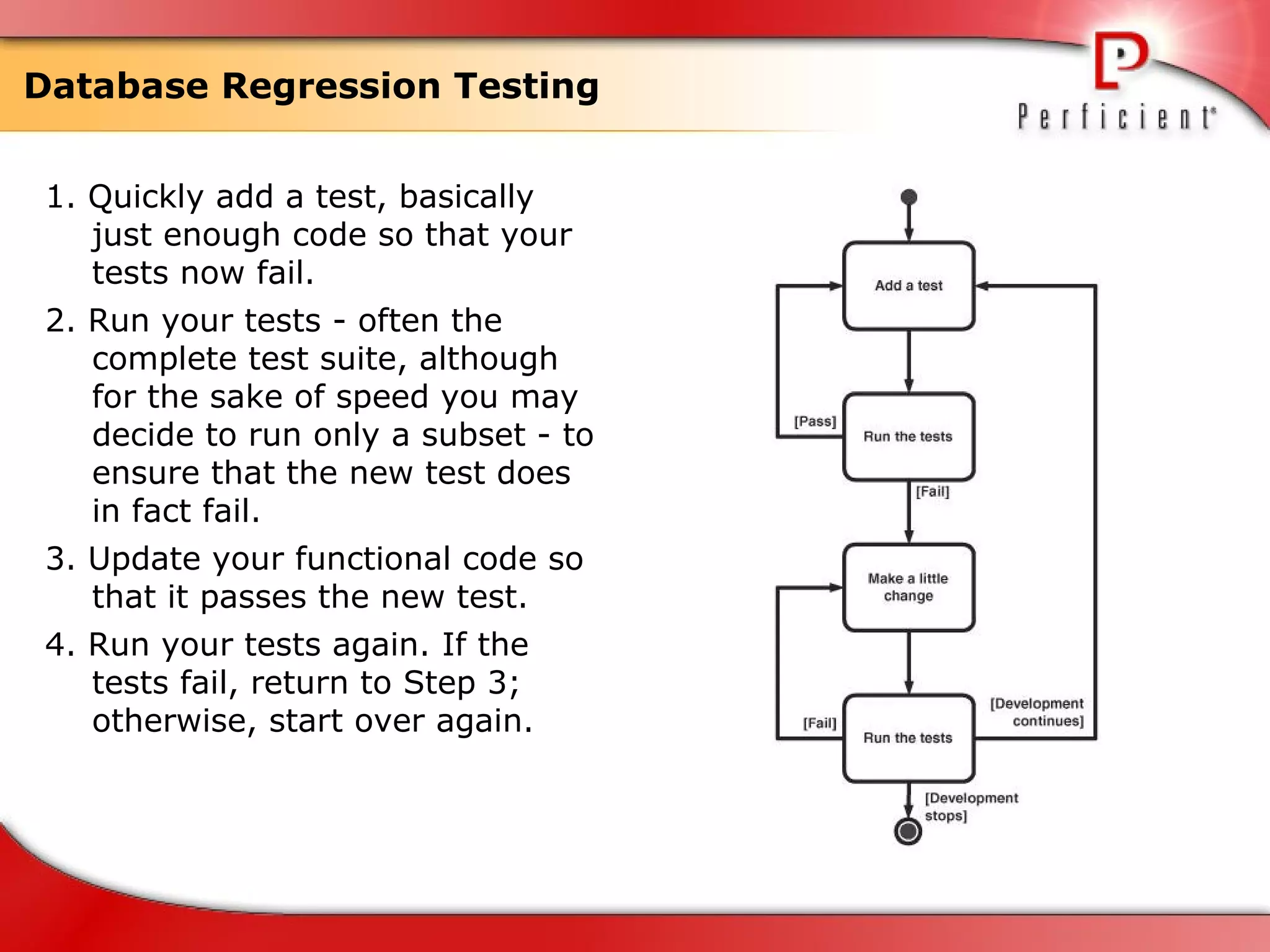
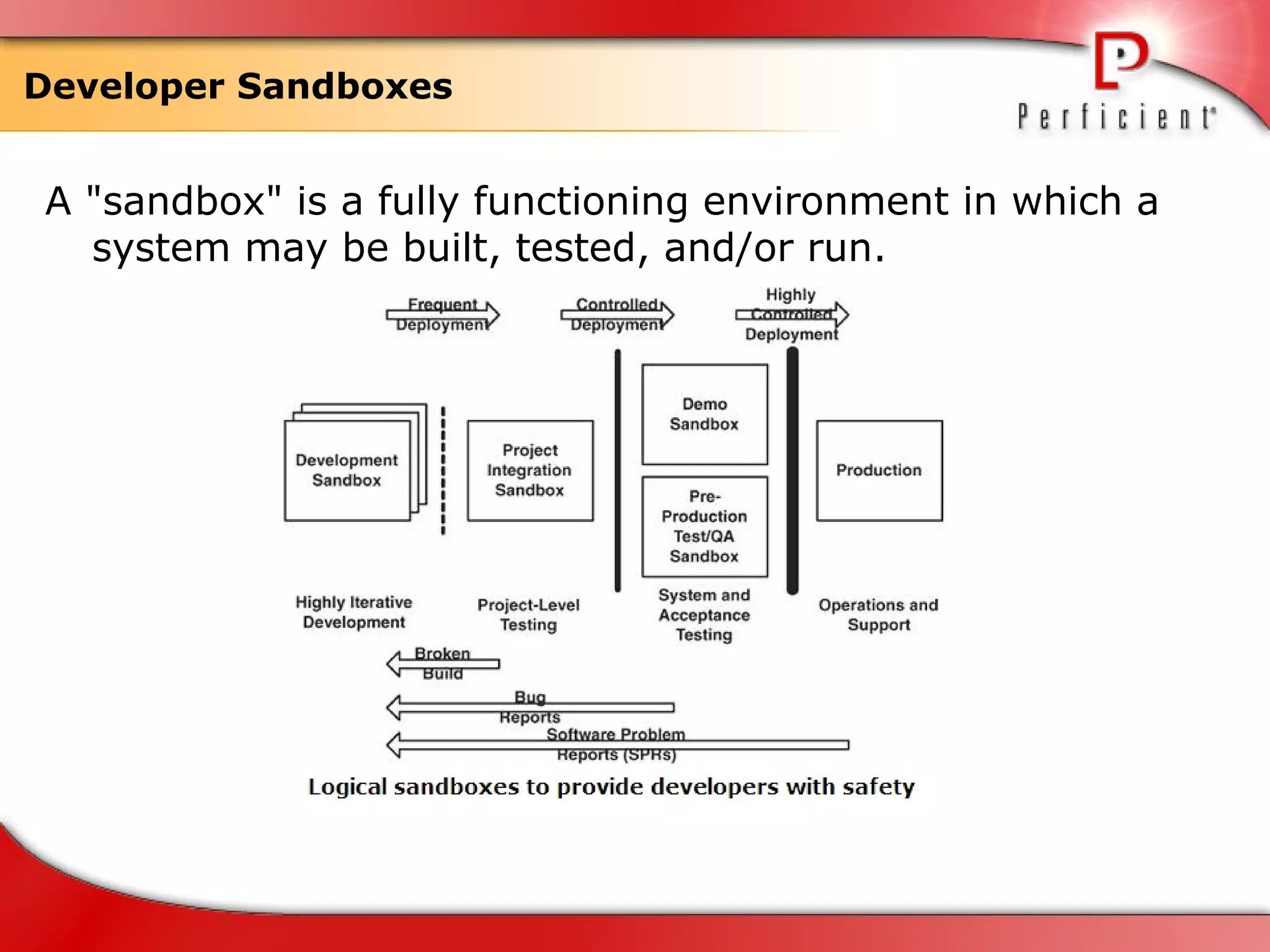
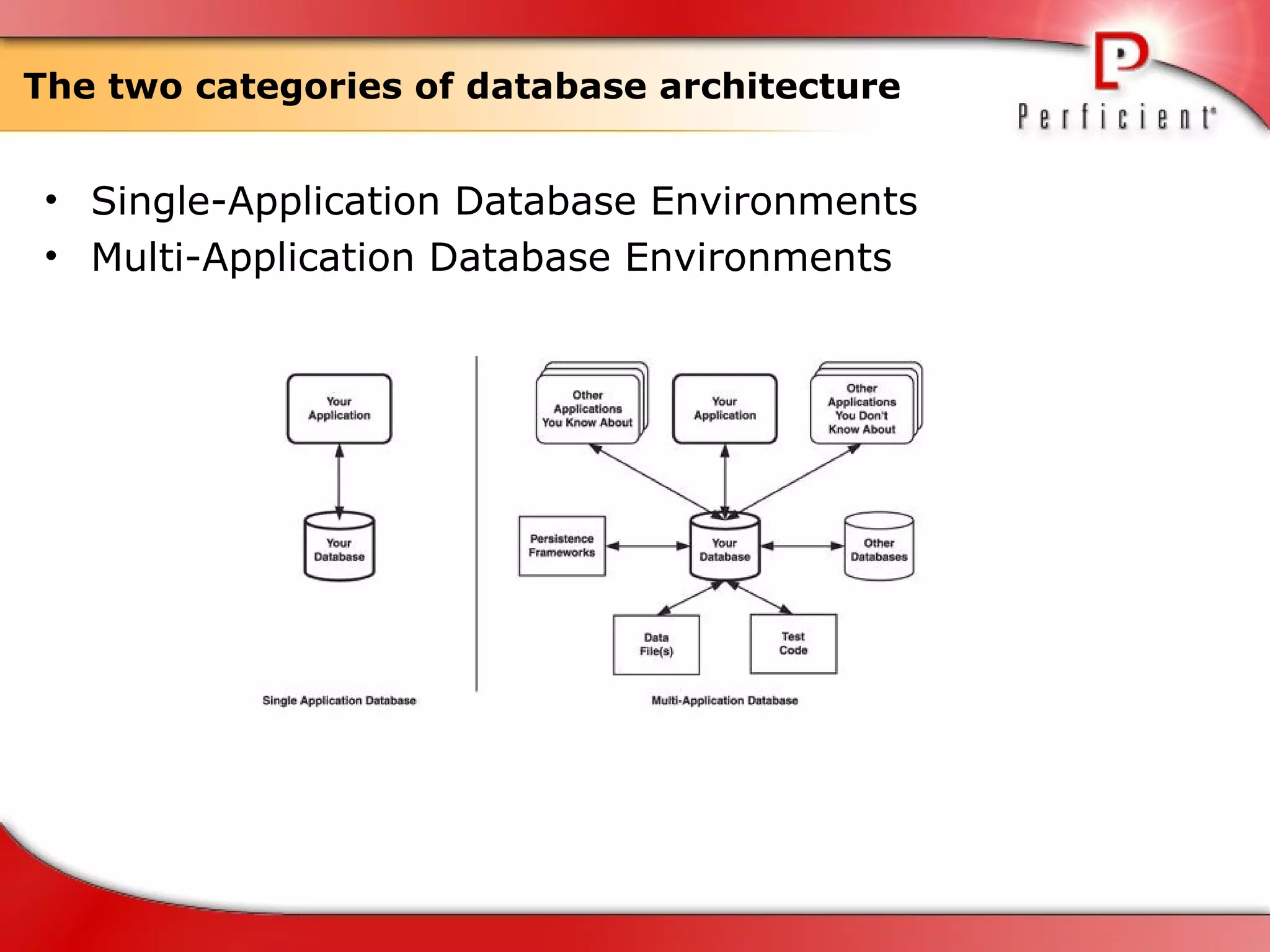
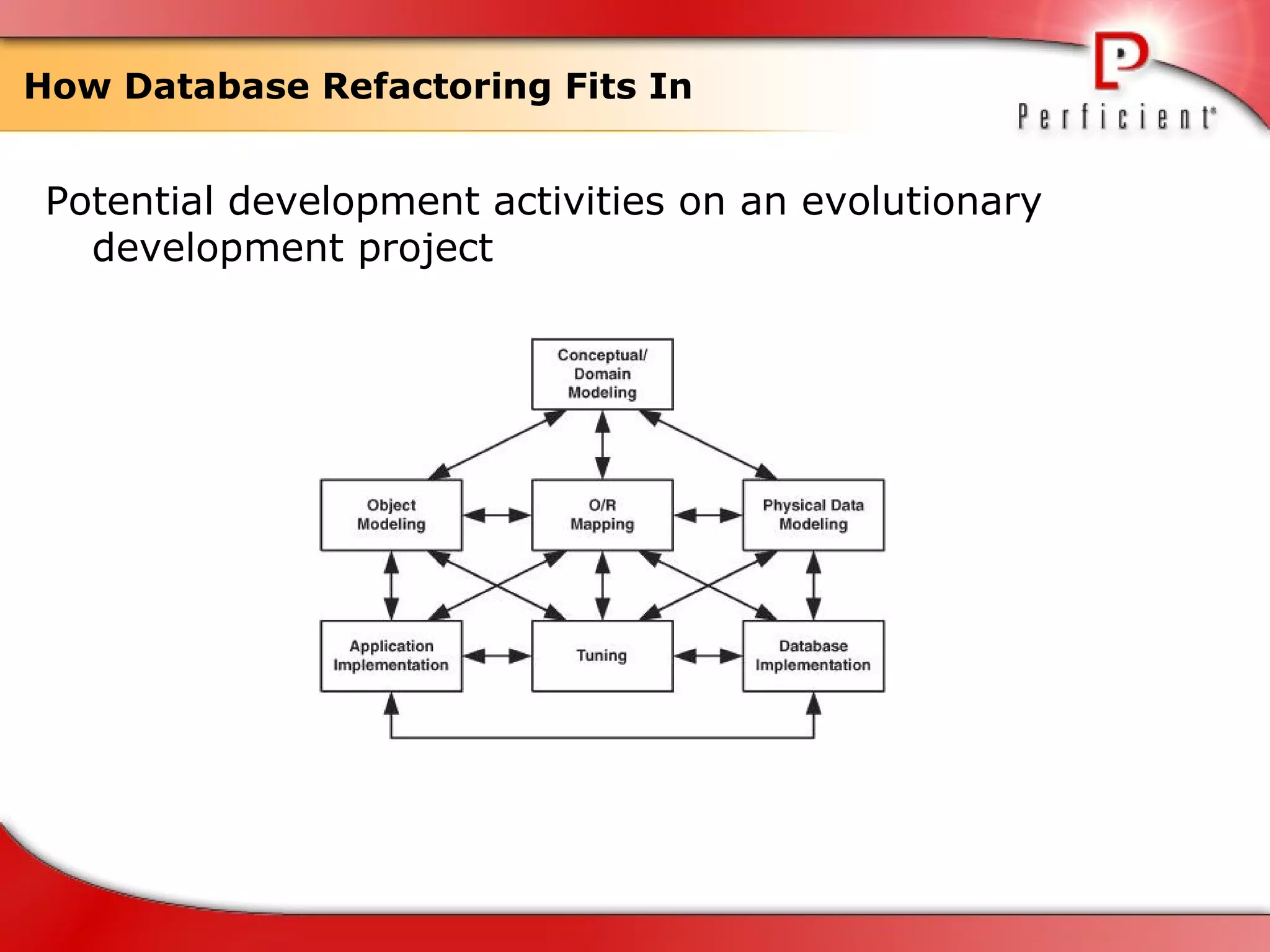
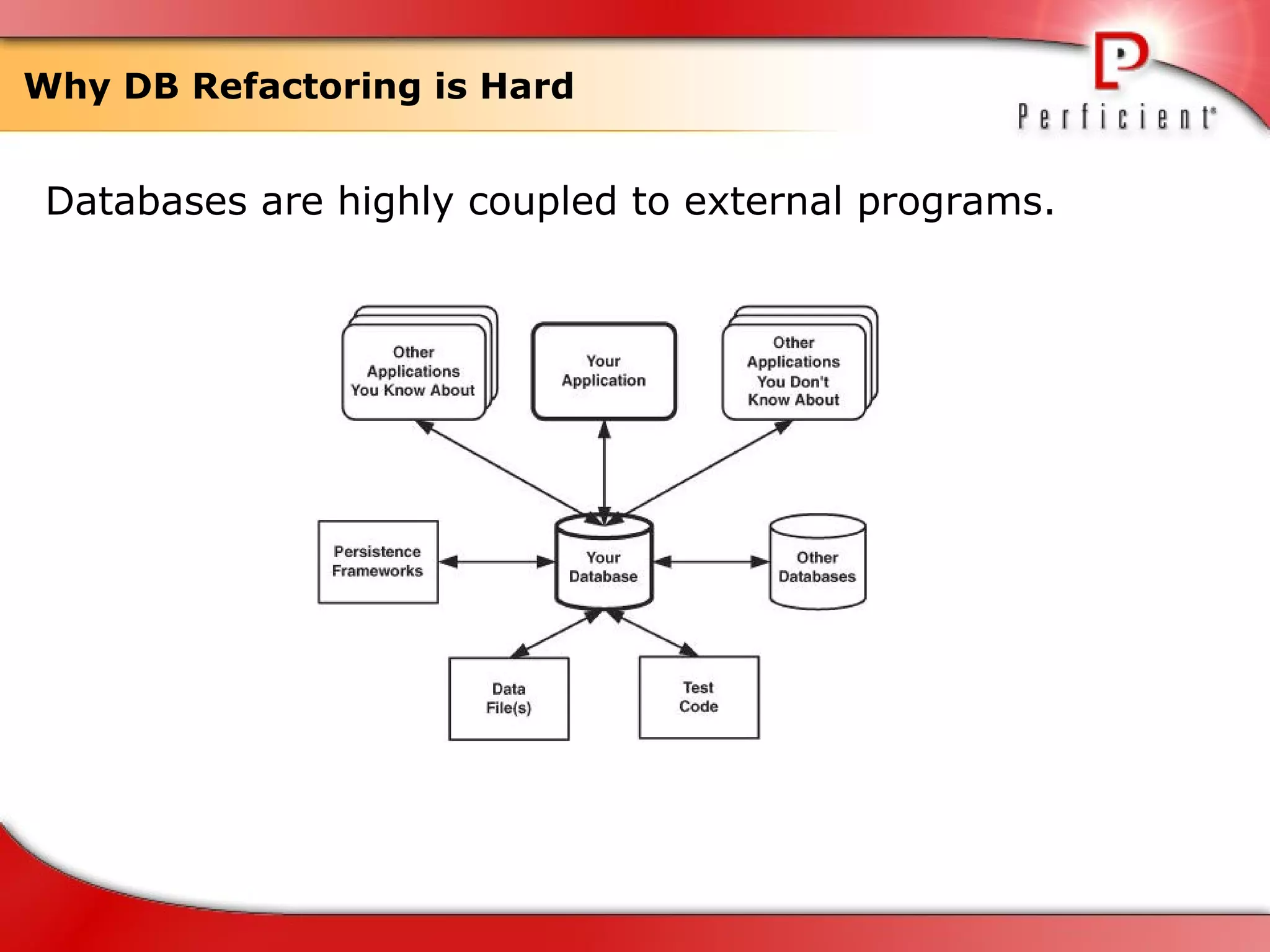
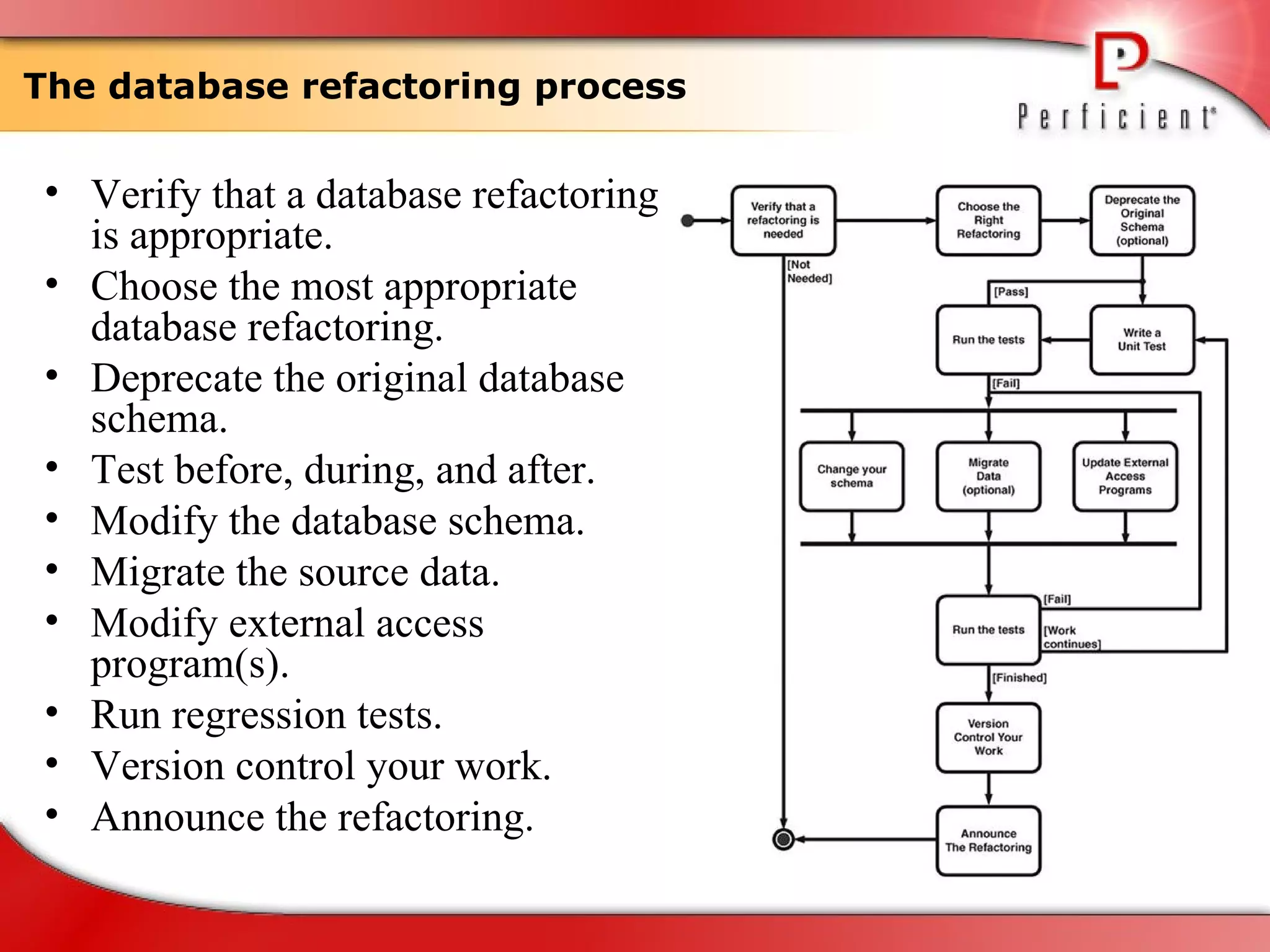
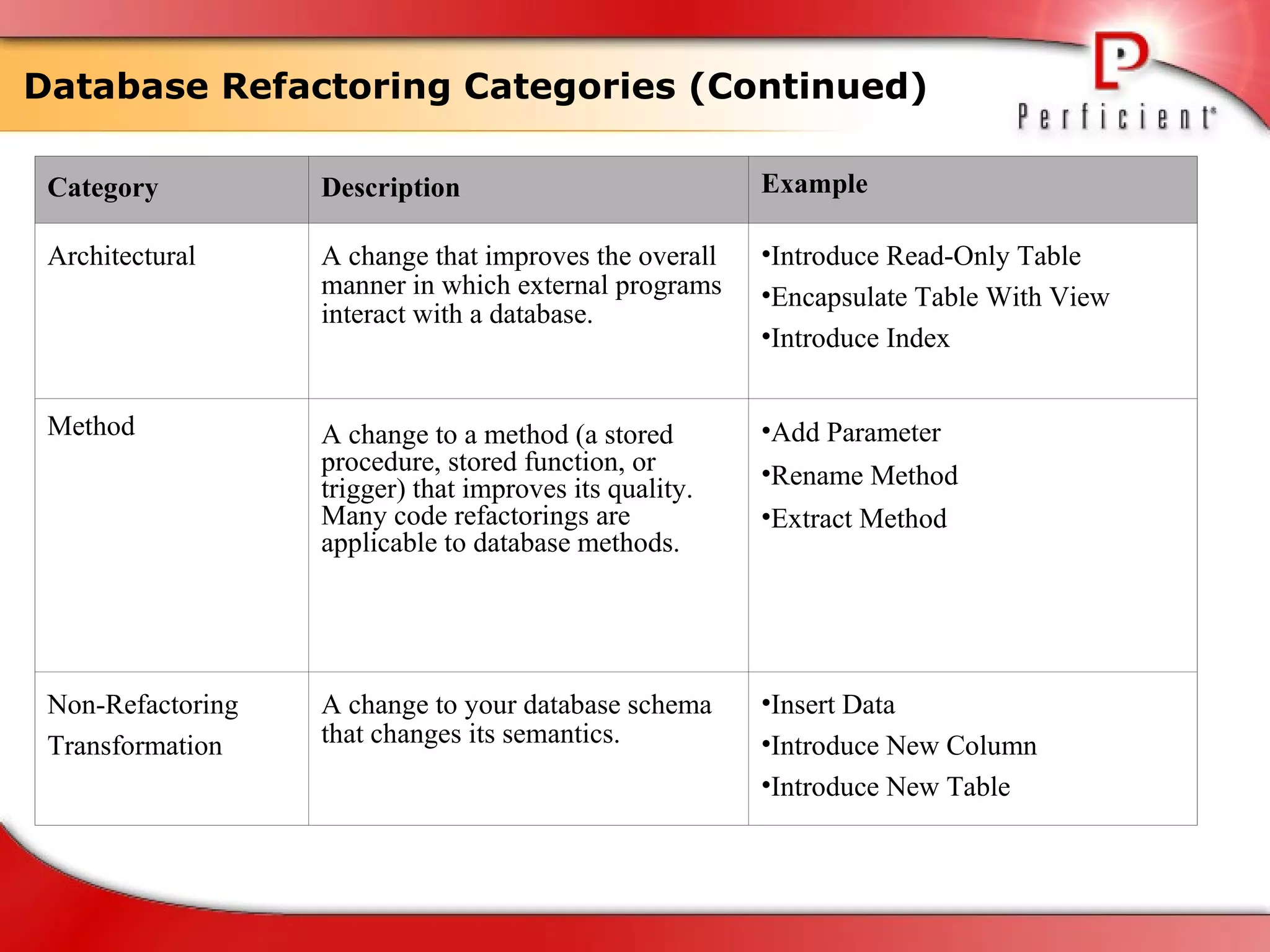
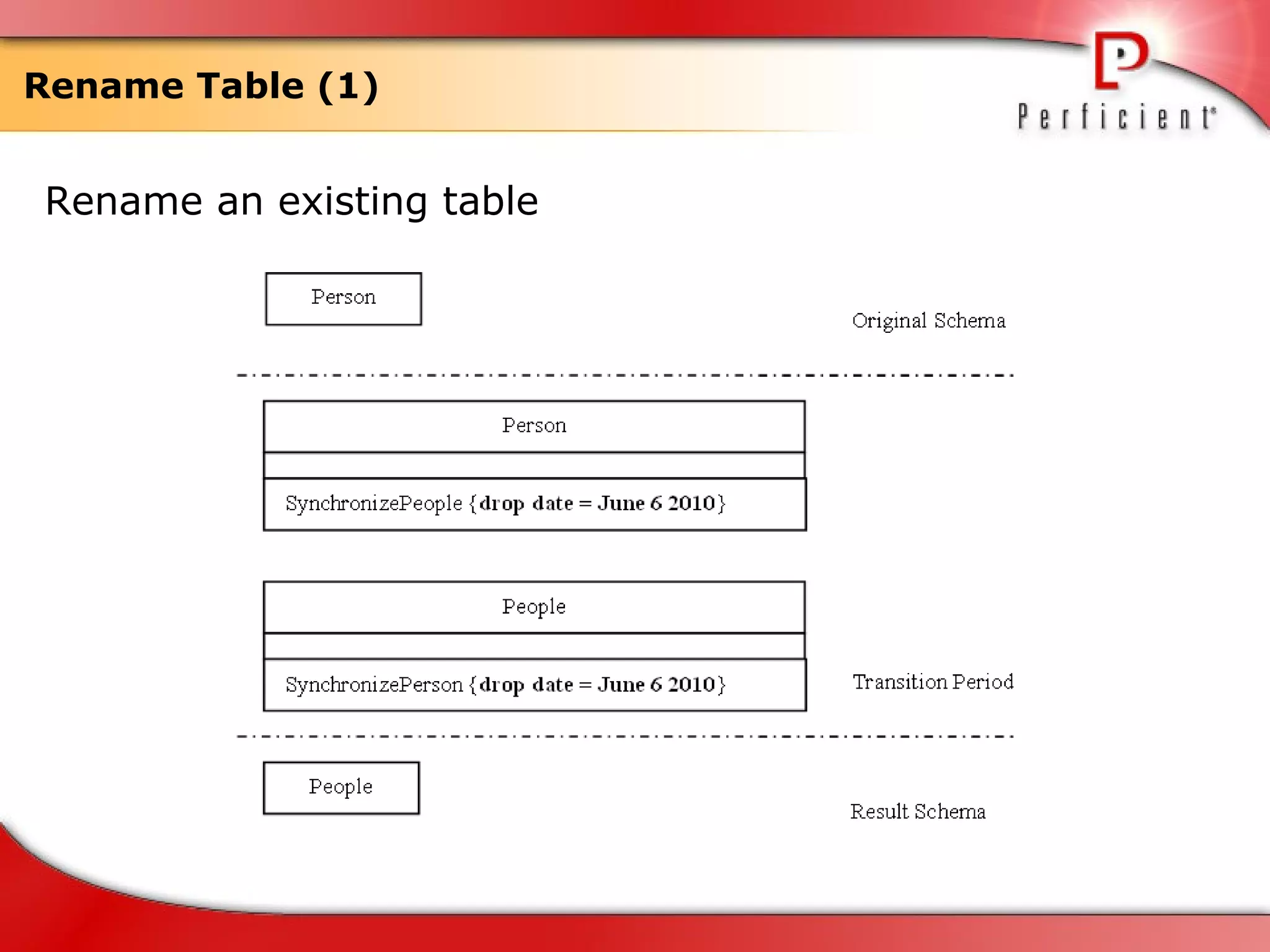
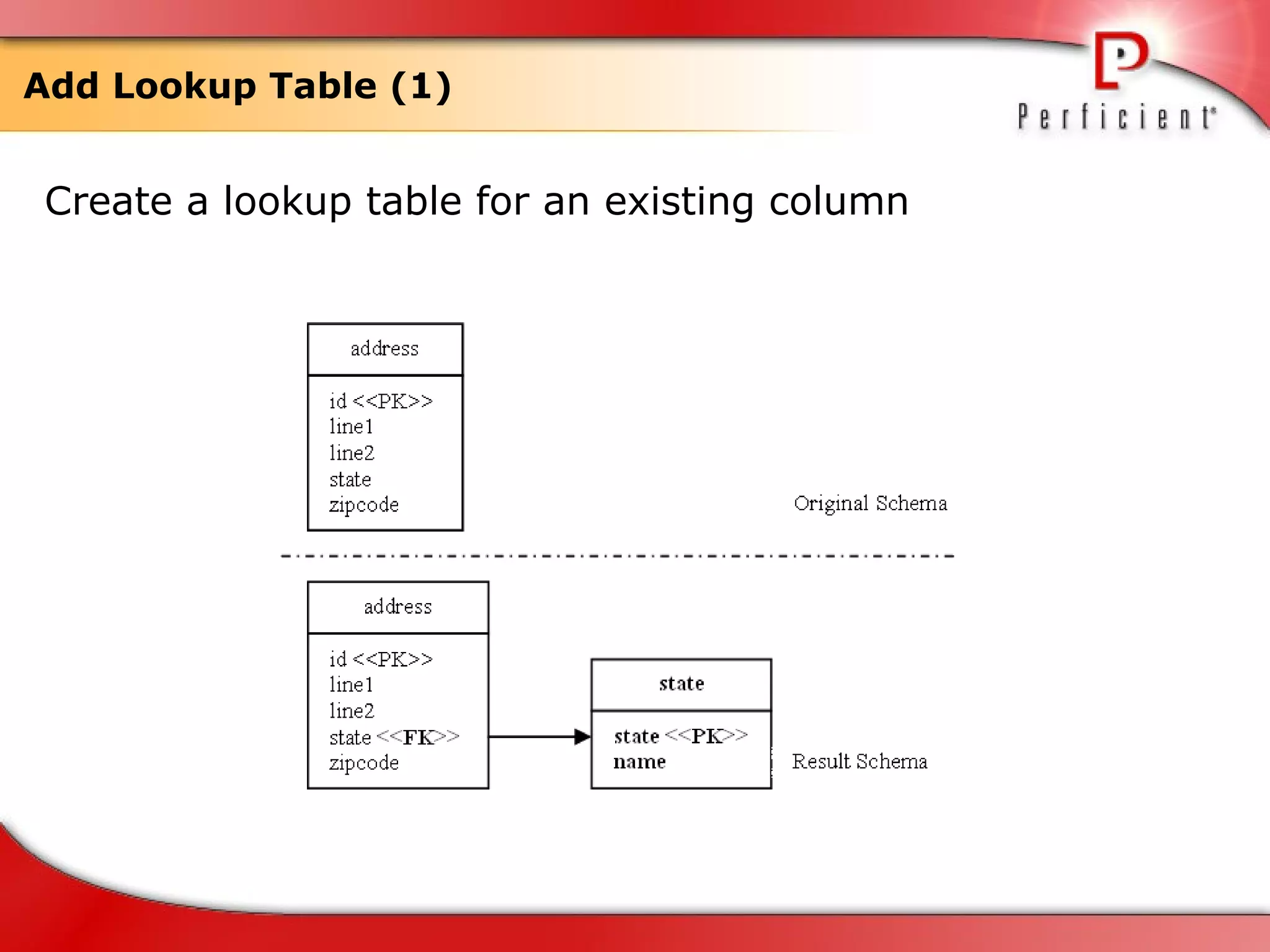
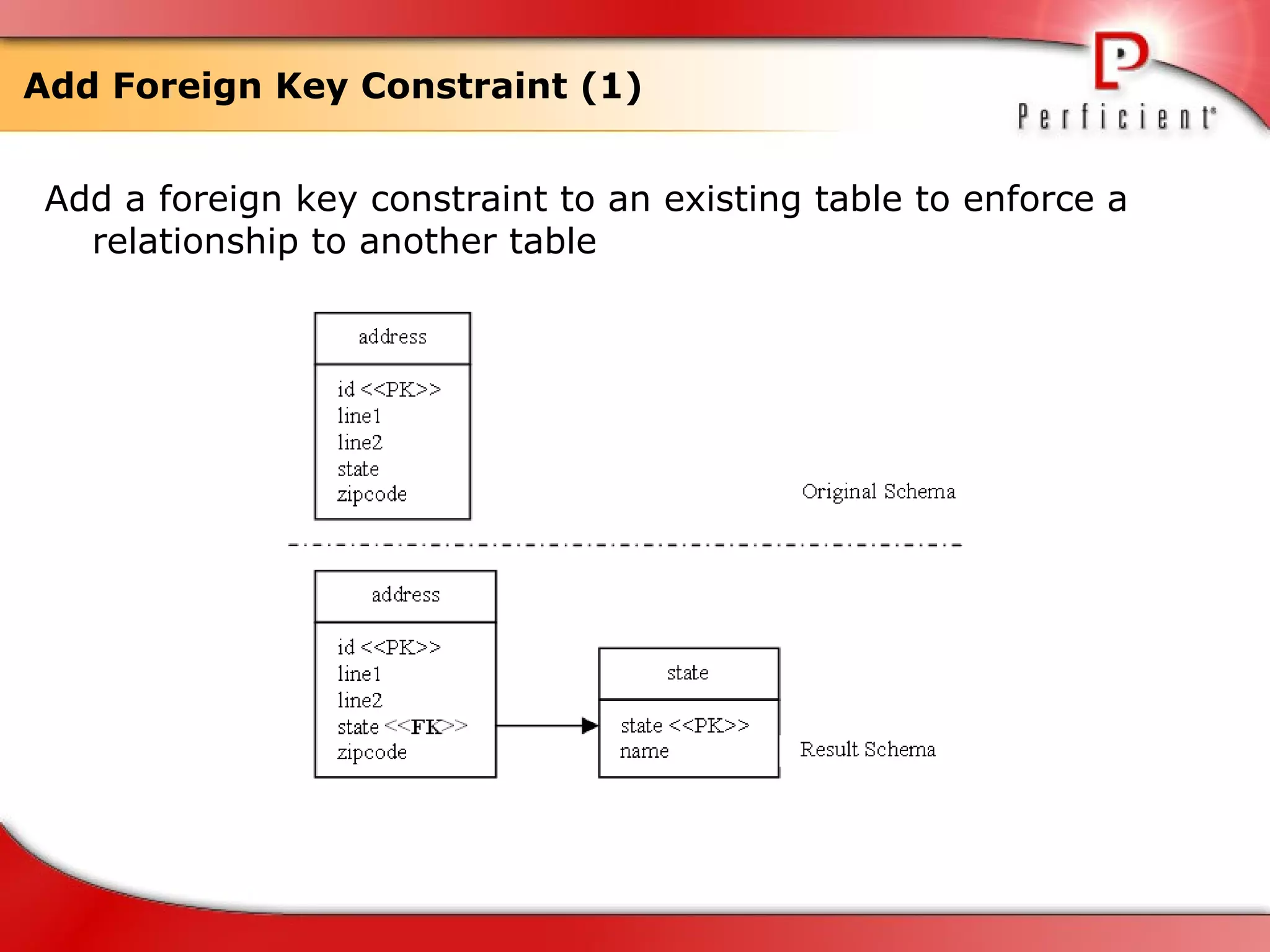
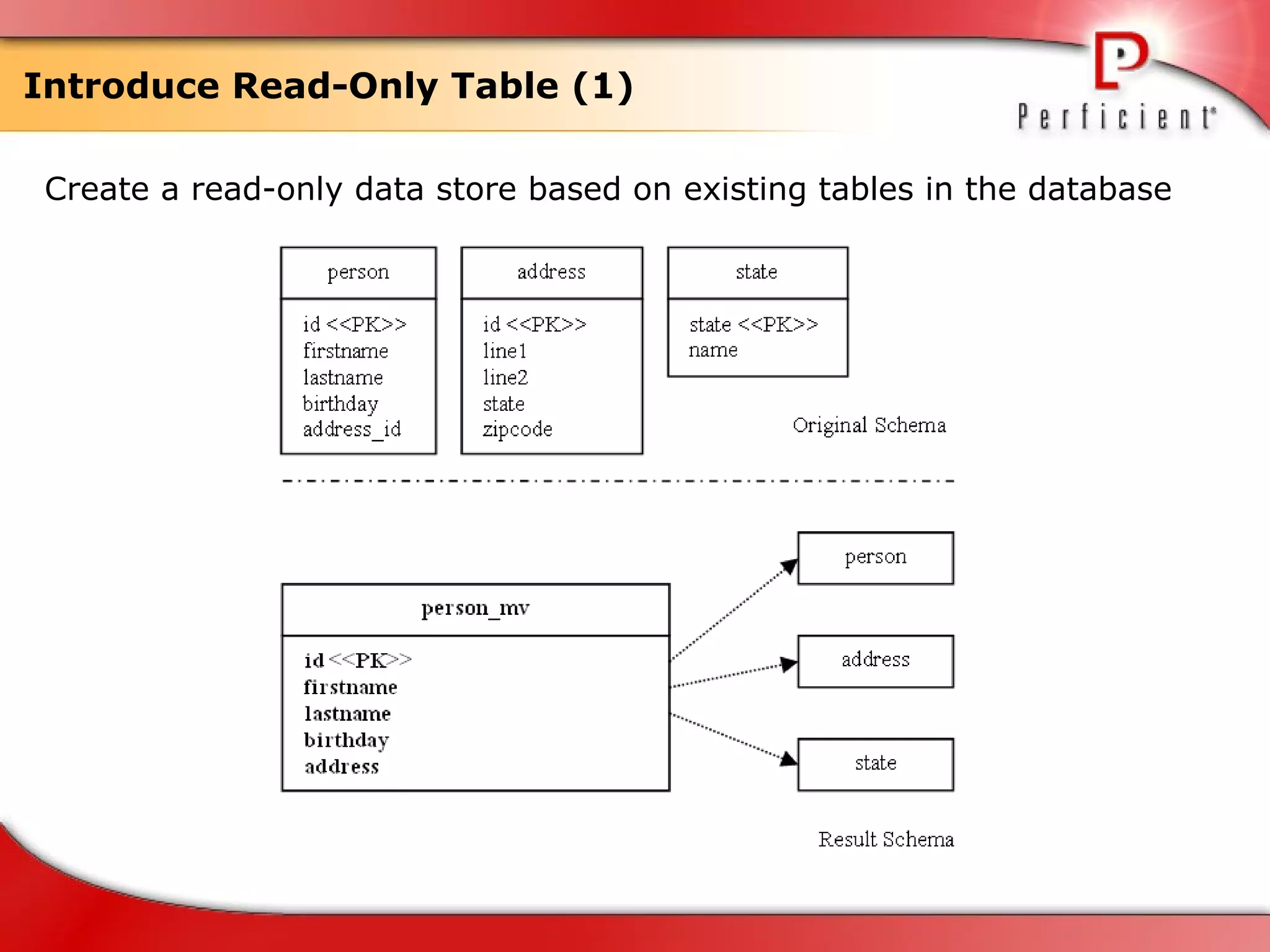
The document discusses database refactoring strategies and patterns. It describes evolutionary database development and the process of database refactoring. Common database refactoring patterns include structural changes like renaming columns or tables, improving data quality, and ensuring referential integrity. The strategies recommend implementing changes through small, incremental steps with testing and version control.

![Refactoring Database Perficient China Lancelot Zhu [email_address]](https://image.slidesharecdn.com/refactoringdatabase-100701213037-phpapp02/75/Refactoring-database-2-2048.jpg)