Download to read offline



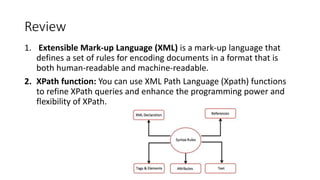




















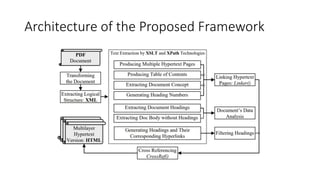






This document summarizes a research paper about reengineering PDF documents containing complex software specifications into multilayer hypertext interfaces. The paper proposes extracting the logical structure and text from PDFs, transforming them into XML, and generating multiple interconnected HTML pages. It describes techniques for extracting figures, tables, lists and concepts to produce navigable outputs that improve on original PDFs and HTML conversions. The framework is evaluated on its usability and architecture with the goal of future work expanding its capabilities to other document formats.


















































































