Downloaded 24 times








![Commands: TS.INCRBY / TS.DECRBY
● Add a new sample:
TS.INCRBY KEY VALUE [RESET TIME_SECONDS]
● Usage:
$ TS.INCRBY active_machine 3
$ TS.DECRBY active_machine 1
$ TS.INCRBY active_users 1 RESET 5
● Caveats:
○ The timestamp that are used are based on the redis host clock](https://image.slidesharecdn.com/dannimoiseyev-180529222332/85/RedisConf18-Redis-as-a-time-series-DB-9-320.jpg)
![Command: TS.RANGE
● Range query over a specific key
TS.RANGE KEY [START TIMESTAMP] [END TIMESTAMP] [AGGREGATION TIME_BUCKET]
○ Aggregations are one of: avg, max, min, count, sum.
● Example:
$ TS.RANGE temperature 1519820907 1519830907
● Example - Aggregate to average of 5 mins (300 seconds):
$ TS.RANGE temperature 1519820907 1519830907 avg 300](https://image.slidesharecdn.com/dannimoiseyev-180529222332/85/RedisConf18-Redis-as-a-time-series-DB-10-320.jpg)
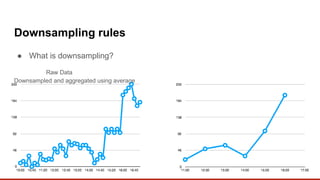



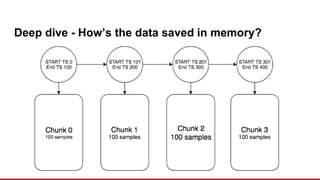




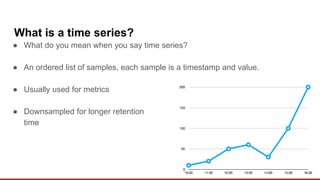
Redis can be used as a time-series database by storing time-stamped data samples in Sorted Sets. A Redis module called redis-timeseries was created to optimize Redis for time-series use cases. It uses a custom data structure and provides commands for ingesting and querying time-series data. Key features include downsampling, retention policies, and fast ingestion and querying of time-series data.



![[NDC21] <쿠키런: 킹덤> 서버 아키텍처 뜯어먹기! - 천만 왕국을 지탱하는 다섯가지 핵심 기술](https://cdn.slidesharecdn.com/ss_thumbnails/finalndc21-210619185557-thumbnail.jpg?width=640&height=640&fit=bounds)















![Nagios core vs. nagios xi presentation power point.pptx [diperbaiki]](https://cdn.slidesharecdn.com/ss_thumbnails/nagioscorevs-160911025342-thumbnail.jpg?width=640&height=640&fit=bounds)



























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)







