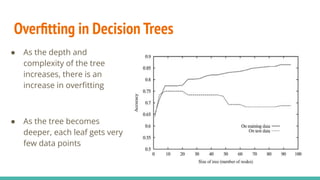
This document discusses decision trees and random forests for classification problems. It provides an overview of how decision trees are trained and make predictions, and how overfitting can be addressed through early stopping techniques. It then introduces random forests, which average the predictions of an ensemble of decision trees to improve accuracy and reduce overfitting compared to a single decision tree. Random forests introduce additional randomness through bagging, where each tree is trained on a random sample of data points and features. This ensemble approach often results in test error reductions even with hundreds or thousands of decision trees.
























![[Women in Data Science Meetup ATX] Decision Trees](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontrees-161118165341-thumbnail.jpg?width=640&height=640&fit=bounds)




































