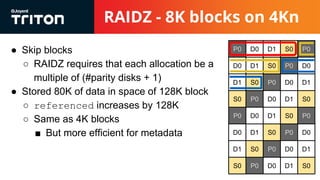
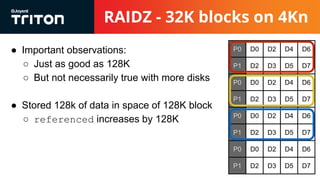
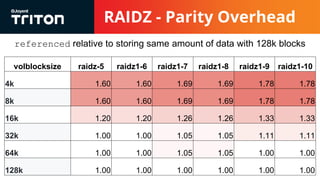
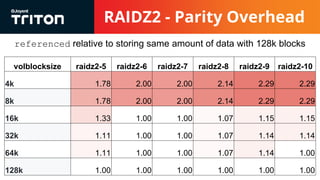
The document discusses the challenges and considerations of the ZFS filesystem, particularly in relation to raidz storage configurations, block allocation, and the impact of advanced format drives. It highlights issues like I/O inflation that occur due to varying block sizes and the miscalculation of refreservation, which affects storage quotas and leads to write failures. Future improvements are suggested, including refinement of volume and dataset configuration to optimize storage efficiency and performance.