22
Functions / 関数
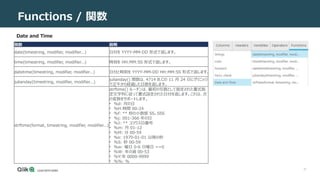
式を作成するために使用できるSQLite 関数について説明します。式ビルダは、関数は次のカテゴリに分けられます。
• Strings
• LOB
• Numeric
• NULL check
• Date and Time
• Operation
• Data enrichment
• Other
• Hash
• User defined
23.
23
Functions / 関数
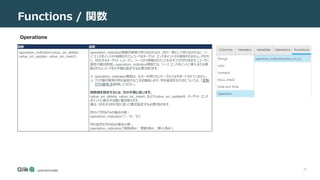
関数説明
lower(x)
下限(x)関数は、文字列 x のコピーを返し、すべての文字を小文字に変換します。デフォルトの組み込みの lower() 関数は、
ASCII 文字に対してのみ機能します。
ltrim(x,y)
ltrim(x,y) 関数は、y に現れるすべての文字を x の左側から削除することによって、文字列を返します。y に値がない場合、
ltrim(x) は x の左側からスペースを削除します。
replace(x,y,z) replace(x,y,z) 関数は、文字列 x に含まれる文字列 y が出現するたびに文字列 z を置換して形成された文字列を返します。
rtrim(x,y)
rtrim(x,y) 関数は、x の右側から y に現れるすべての文字を削除することによって形成された文字列を返します。y に値がない
場合、rtrim(x) は x の右側からスペースを削除します。
substr(x,y,z)
substr(x,y,z) 関数は、y 番目の文字で始まり、z 文字長の入力文字列 x の部分文字列を返します。z を省略すると、
substr(x,y) は y 番目から始まる文字列 x の末尾までのすべての文字を返します。x の左端文字は 1 です。y が負の場合、
部分文字列の最初の文字は、左ではなく右から数えて見つかります。z が負の場合は、y 番目の文字の前にある abs(z) 文字
が戻されます。x が文字列の場合、文字インデックスは実際の UTF-8 文字を参照します。x が BLOB の場合、インデックスはバ
イトを参照します。
trim(x,y)
trim(x,y) 関数は、x の両側から y に現れるすべての文字を削除して、文字列を返します。y に値がない場合、trim(x) は x
の両側からスペースを削除します。
replaceChars(X,Y,Z) replaceChars(X,Y,Z)関数は、文字列X内の文字列 Y (置換される文字) に存在する文字を同じ位置にあるZ (置換文字)
に置き換えます。これは、パスやファイル名から無効な文字を削除する場合に特に便利です。
文字列Z (置換文字) に、文字列Xの対応する位置を持つ文字が含まれていない場合、文字列Zの最初の文字に置き換えられ
ます。
文字列Xに文字列Zに存在しない文字が含まれている場合、元の文字は変更されません。
したがって、たとえば、replaceChars(「abcde」、「abcd」、「123」)を指定すると、1231eが返されます。
Strings




![4
Expression Builderの概要
Expression Builderの4つの主要部分を示す例を示します。フィルタ、変換、またはグローバル変換のどちらの式を作成するかによって利用できるオプションが異なる場合があります。
• Elements Pane(左側): このペインには、式に追加できる要素が含まれています。
Metadata: グローバル変換を使用する場合にのみ使用可能
Input: 変換またはフィルターを使用する場合にのみ使用可能
Header: グローバル変換の場合、このタブは[Add Column]を選択した
場合にのみ使用できます。
Variables: 変数
Operators: 演算子
Functions: 関数
• Build Expressionパネル:
作成する式を入力します。列や演算子などの要素をボックスに移動します。この
ボックスには、式の全部または一部を入力することもできます。
• Parse Expressionパネル:
式を作成した後、[Parse Expression] をクリックして式のパラメーターを一
覧表示します。その後、各パラメータに値または引数を入力できます。
パネルの上部にはOperatorツールバーがあります。このツールバーには、最も一
般的な演算子が含まれています。
• Test Expressionパネル:
このパネルには、式の各パラメーターに値を指定した後に実行できるテストの結
果が表示されます。](https://image.slidesharecdn.com/123usingtheexpressionbuilder-211014072326/85/Qlik-Replicate-Expression-Builder-4-320.jpg)
![6
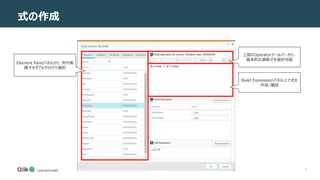
式の作成 – Operatorツールバー
Operatorツールバー
• [Operator] ツールバーは、[Build Expression] ボックスの上にあります。この関数には最も一般的な演算子が含まれているため、式に簡単に追加できます。
• 加算、減算、乗算、除算、割合、等しくない、等しい、連結、AND、OR の演算子を使用できます。
[オペレータ]ツールバーを使用するには:
1. [Build Expression] ボックスで、演算子を追加する場所をクリックします。
2. 追加する演算子をクリックします。式に追加されます。](https://image.slidesharecdn.com/123usingtheexpressionbuilder-211014072326/85/Qlik-Replicate-Expression-Builder-6-320.jpg)
![7
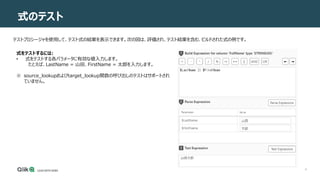
式の解析
式を解析して、そのパラメーターを決定し、式が有効かどうかを判断できます。
式を解析するには
1. [Parse Expression]をクリックします。
式が有効でない場合は、[Expression Builder] ウィンドウの下部に
赤でエラー メッセージが書き込まれます。
式が有効な場合は、パラメーターが[Parse Expression] セクション
に表示されます。](https://image.slidesharecdn.com/123usingtheexpressionbuilder-211014072326/85/Qlik-Replicate-Expression-Builder-7-320.jpg)


![13
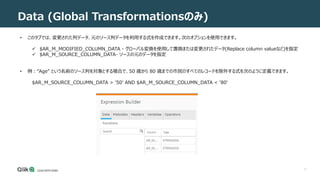
Metadata (Global Transformationsのみ)
[Metadata] タブには、式で使用できる変数が含まれています。
名前にMODIFIEDを持つ変数は、グローバル変換を使用して置換または変更されたメタデータを指定するために使用
MODIFIEDを使用しない変数名は、ソース データベースで定義されている元のメタデータを指定するために使用
• AR_M_MODIFIED_SCHEMA - 変更されたソース スキーマ名。
• AR_M_MODIFIED_TABLE_NAME - 変更されたソース テーブル名。
• AR_M_MODIFIED_COLUMN_NAME - ソース テーブル内の変更された列名。
• AR_M_MODIFIED_DATATYPE_NAME - ソース テーブル内の列の変更されたデータ型。
• AR_M_MODIFIED_DATATYPE_LENGTH - ソース テーブル内の列の変更されたデータ型の長さ。
• AR_M_MODIFIED_DATATYPE_PRECISION - ソース テーブル内の列の変更されたデータ型の精度。
• AR_M_MODIFIED_DATATYPE_SCALE - ソース テーブル内の列の変更されたデータ型のスケール。
• AR_M_SOURCE_SCHEMA - ソース スキーマの名前。
• AR_M_SOURCE_TABLE_NAME - ソース テーブルの名前。
• AR_M_SOURCE_COLUMN_NAME - ソース テーブルの列の名前。
• AR_M_SOURCE_DATATYPE_NAME - ソース テーブル内の列のデータ型。
• AR_M_SOURCE_DATATYPE_LENGTH - ソース テーブル内の列のデータ型の長さ。
• AR_M_SOURCE_DATATYPE_PRECISION - ソース テーブル内の列のデータ型の精度。
• AR_M_SOURCE_DATATYPE_SCALE - ソース テーブル内の列のデータ型のスケール。](https://image.slidesharecdn.com/123usingtheexpressionbuilder-211014072326/85/Qlik-Replicate-Expression-Builder-13-320.jpg)
![14
Header
• 変換を定義するときに、ヘッダーを含む式を作成することで、どのヘッダーをレプリケートするかを決定できます。(デフォルトでは、ソーステーブルのヘッダーは
ターゲットにレプリケートされません。)
• ヘッダー値を使用してフィルターを作成できます。ヘッダー フィルターは、変更処理中に適用されます。
※ Headerタブは、フィルターと変換に使用できます。グローバル変換で使用できるのは、[Add Column] を選択した場合だけです。
※ ヘッダー列は、明示的に指定されていない限り、すべてのエンドポイントでサポートされます。](https://image.slidesharecdn.com/123usingtheexpressionbuilder-211014072326/85/Qlik-Replicate-Expression-Builder-14-320.jpg)


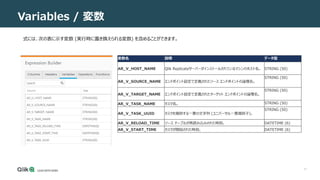



![32
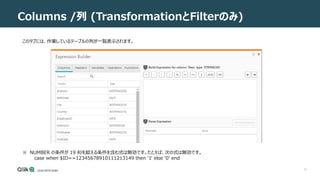
Functions / 関数
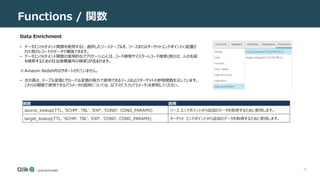
DEPARTMENT_NAME列を追加するには、次の手順を実行する必要があります。
1. 新しいタスクを作成し、レプリケーションの対象としてHR.JOB_HISTORYテーブルを選択します。
2. HR. JOB_HISTORYテーブルに[New Columns]変換を適用します。
3. Expression Builderを開き、[Function] タブから[Data Enrichment] を選択します。
4. source_lookup関数を選択し、次のように構成します (ソース エンドポイントのネイティブ構文を使用)。
ルックアップテーブルが Oracle にある場合は、次の手順を実行します。
source_lookup(10000,'HR','DEPARTMENTS','DEPARTMENT_NAME','DEPARTMENT_ID=:1',$DEPARTMENT_ID)
ルックアップテーブルが SQL Server に存在する場合は、次の手順を実行します。
source_lookup(10000,'HR','DEPARTMENTS','[DEPARTMENT_NAME]’, [DEPARTMENT]=?',$DEPARTMENT_ID)
• 10000は TTL パラメータです。
• HRはスキーマ名です。
• 'DEPARTMENTSはテーブル名です。
• DEPARTMENT_NAMEは式です。
• DEPARTMENT_ID=:1 (またはマイクロソフト SQL Server 上の? )が条件です。
• $DEPARTMENT_IDは条件パラメータです。
5. タスクを実行します。](https://image.slidesharecdn.com/123usingtheexpressionbuilder-211014072326/85/Qlik-Replicate-Expression-Builder-32-320.jpg)
![33
Functions / 関数
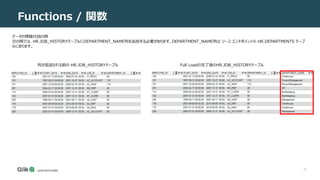
関数 説明
length(x) 文字列値 x の場合、length(x) 関数は、先頭の NULL 文字の前の x の前の
文字数 (バイトではない) を返します。
x が NULL の場合、長さ(x) は NULL です。x が数値の場合、length(X) は
X の文字列表現の長さを返します。
like(x,y,z) like() 関数は、"Y LIKE X [ESCAPE Z]"式を実装するために使用されます。
ESCAPE (z) 句はオプションです。z 節がある場合は、like() 関数が 3 つの引数
を指定して呼び出されます。それ以外の場合は、2 つの引数を指定して呼び出され
ます。
typeof(x) typeof(x) 関数は、式 xのデータ型を示す文字列を返します。
Other Functions](https://image.slidesharecdn.com/123usingtheexpressionbuilder-211014072326/85/Qlik-Replicate-Expression-Builder-33-320.jpg)
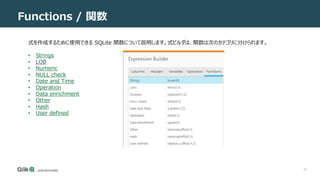
![34
Functions / 関数
Hash
• Hash 関数は、入力された列のハッシュ値を生成し (SHA-256 アルゴリズムを使用して) 生成し、生成されたハッシュ値の 16 進値を返します。
• 式で関数を使用するには、hash_sha256(x)関数を[Build Expression] ウィンドウに追加し、"x" を目的のソース列名に置き換えます。
• この関数は、特に機密情報をマスキングする場合に便利です。たとえば、以下の式では、従業員の電子メール アドレスを難読化するために Hash 関数が使用されています。](https://image.slidesharecdn.com/123usingtheexpressionbuilder-211014072326/85/Qlik-Replicate-Expression-Builder-34-320.jpg)

![38
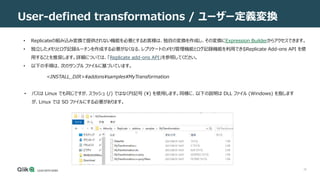
ユーザー定義変換の作成
3. <INSTALL_DIR>¥addonsの下にあるaddons_def.json.sampleファイルにライブラリを登録します。
• nameは DLL の論理名です (任意の名前を指定できます)。lib_pathパラメータを使用して DLL パスを指定しない場合 (下記参照)、DLL
ファイルは<INSTALL_DIR>¥addons¥<addon_name>に存在する必要があります。Linux では、<addon_name>フォルダは
手動で作成する必要があり、デフォルトのアドオン名 (MyTransformation) か、新しい名前 (変更した場合) にする必要があります。
• typeは、DLL を読み込むタイミングを指定するオプションのパラメーターです。現在サポートされている値はSTARTUPだけです。
• lib_pathは、DLL の完全パスです (例:C:¥Transforms¥MyManipulator.dll)。これは、DLL が
<INSTALL_DIR>¥addons¥<addon_name>に存在しない場合にのみ必要です (上記のnameパラメーターの説明に記載)。
• init_functionは、DLL の生成に使用される C ファイルに表示される関数名です。
4. ファイルをaddons_def.jsonという名前で保存します。
{
"addons": [{
"name": "MyTransformation",
"type": "STARTUP",
//"lib_path": "C:Program FilesAttunity ReplicateaddonssamplesMyTransformationMyTransformation.dll",
//"lib_path": "/opt/attunity/replicate/addons/samples/MyTransformation/MyTransformation.so",
"init_function": "my_transformation_init_func"
}]
}](https://image.slidesharecdn.com/123usingtheexpressionbuilder-211014072326/85/Qlik-Replicate-Expression-Builder-38-320.jpg)
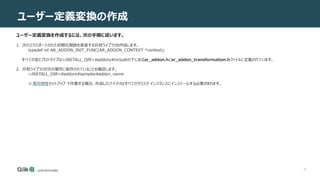
![39
ユーザー定義変換の作成
5. 次の例のように、addon 初期化関数 (ステップ 1 で説明) に新しい関数を登録します。
USER_DEFINED_TRANSFORMATION_DEF *transdef = GET_AR_AO_TRANSFORMATION_DEF();
transdef->displayName = "prefix_with(X, Y)";
transdef->functionName = "prefix_with";
transdef->description = "prefix_with adds the prefix <Y_> to a given string X";
transdef->func = trans_prefix_with;
transdef->nArgs = 2;
AR_AO_REGISRATION->register_user_defined_transformation(transdef);
6. Qlik Replicateサーバーサービスを再起動します。
新しい “prefix_with” 関数は、Expression Builderの[Functions->User Defined] の下で使用できるようになります。](https://image.slidesharecdn.com/123usingtheexpressionbuilder-211014072326/85/Qlik-Replicate-Expression-Builder-39-320.jpg)




































































