Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
QlikPresalesJapan
PPTX, PDF
3,100 views
Qlik Replicateでのタスクの定義と管理
Qlik Replicateを基礎から学ぶ勉強会#2「Qlik Replicateでのタスクの定義と管理」
Data & Analytics
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Downloaded 36 times
1
/ 30
2
/ 30
3
/ 30
4
/ 30
5
/ 30
6
/ 30
7
/ 30
8
/ 30
9
/ 30
10
/ 30
11
/ 30
12
/ 30
Most read
13
/ 30
14
/ 30
15
/ 30
16
/ 30
17
/ 30
18
/ 30
Most read
19
/ 30
20
/ 30
21
/ 30
22
/ 30
23
/ 30
24
/ 30
25
/ 30
26
/ 30
Most read
27
/ 30
28
/ 30
29
/ 30
30
/ 30
More Related Content
PPTX
Qlik Replicateでのテーブル設定詳細(変換・フィルターなど)
by
QlikPresalesJapan
PPTX
Qlik Replicate のインストール
by
QlikPresalesJapan
PPTX
Qlik Replicateでのレプリケーション・タスクの監視と制御
by
QlikPresalesJapan
PPTX
Oracleのソース・ターゲットエンドポイントとしての利用
by
QlikPresalesJapan
PPTX
Qlik Replicateでのタスク設定の詳細
by
QlikPresalesJapan
PPTX
Qlik ReplicateでのLog Streamの利用
by
QlikPresalesJapan
PPTX
Qlik Replicate コンソールの利用方法
by
QlikPresalesJapan
PPTX
Qlik Replicateのタスク実行時の操作
by
QlikPresalesJapan
Qlik Replicateでのテーブル設定詳細(変換・フィルターなど)
by
QlikPresalesJapan
Qlik Replicate のインストール
by
QlikPresalesJapan
Qlik Replicateでのレプリケーション・タスクの監視と制御
by
QlikPresalesJapan
Oracleのソース・ターゲットエンドポイントとしての利用
by
QlikPresalesJapan
Qlik Replicateでのタスク設定の詳細
by
QlikPresalesJapan
Qlik ReplicateでのLog Streamの利用
by
QlikPresalesJapan
Qlik Replicate コンソールの利用方法
by
QlikPresalesJapan
Qlik Replicateのタスク実行時の操作
by
QlikPresalesJapan
What's hot
PPTX
Qlik composeを利用したDWH構築の流れ
by
QlikPresalesJapan
PPTX
Qlik TECH TALK 20210706 SAPデータ分析を加速するQlikのアクセレレーターパッケージご紹介
by
QlikPresalesJapan
PPTX
Microsoft SQL Serverのソース・ターゲットエンドポイントとしての利用
by
QlikPresalesJapan
PPTX
Qlik Replicate - Change Tables(変更テーブル)のご説明
by
QlikPresalesJapan
PPTX
Qlik Replicateでのエンドポイント設定の概要
by
QlikPresalesJapan
PDF
TECHTALK_20241105_生成AIを使用したQlik Answersのご紹介資料
by
QlikPresalesJapan
PPTX
Qlik Replicate - Replicate Logger
by
QlikPresalesJapan
PPTX
Qlik ReplicateでApache Kafkaをターゲットとして使用する
by
QlikPresalesJapan
PPTX
Qlik Senseを使ったSAP ECCとSAP S4 HANAのデータ分析
by
QlikPresalesJapan
PPTX
Qlik Replicate - Control Tableの詳細
by
QlikPresalesJapan
PDF
【より深く知ろう】活用最先端!データベースとアプリケーション開発をシンプルに、高速化するテクニック
by
オラクルエンジニア通信
PPTX
Azure Synapse Analyticsのターゲットエンドポイントとしての利用
by
QlikPresalesJapan
PPTX
リアルタイムにデータを配信・変換・統合:Qlik Cloudデータ統合のご紹介
by
QlikPresalesJapan
PPTX
Qlik Replicate - IBM DB2 for LUWを ソースおよびターゲットエンドポイントとして使用する
by
QlikPresalesJapan
PPTX
詳説 Qlik Sense GeoOperations – Qlik Sense SaaSで地理データを計算する
by
QlikPresalesJapan
PPTX
Qlik Replicateのファイルチャネルの利用
by
QlikPresalesJapan
PPTX
Qlik Application Automation ~ テンプレートで素早く自動化フローを作成
by
QlikPresalesJapan
PPTX
Qlik composeのご紹介
by
QlikPresalesJapan
PPTX
Qlik Cloudデータ統合:Data Gateway - Data Movementのセットアップ
by
QlikPresalesJapan
PPTX
Qlik ReplicateにおけるExpression Builderの利用方法
by
QlikPresalesJapan
Qlik composeを利用したDWH構築の流れ
by
QlikPresalesJapan
Qlik TECH TALK 20210706 SAPデータ分析を加速するQlikのアクセレレーターパッケージご紹介
by
QlikPresalesJapan
Microsoft SQL Serverのソース・ターゲットエンドポイントとしての利用
by
QlikPresalesJapan
Qlik Replicate - Change Tables(変更テーブル)のご説明
by
QlikPresalesJapan
Qlik Replicateでのエンドポイント設定の概要
by
QlikPresalesJapan
TECHTALK_20241105_生成AIを使用したQlik Answersのご紹介資料
by
QlikPresalesJapan
Qlik Replicate - Replicate Logger
by
QlikPresalesJapan
Qlik ReplicateでApache Kafkaをターゲットとして使用する
by
QlikPresalesJapan
Qlik Senseを使ったSAP ECCとSAP S4 HANAのデータ分析
by
QlikPresalesJapan
Qlik Replicate - Control Tableの詳細
by
QlikPresalesJapan
【より深く知ろう】活用最先端!データベースとアプリケーション開発をシンプルに、高速化するテクニック
by
オラクルエンジニア通信
Azure Synapse Analyticsのターゲットエンドポイントとしての利用
by
QlikPresalesJapan
リアルタイムにデータを配信・変換・統合:Qlik Cloudデータ統合のご紹介
by
QlikPresalesJapan
Qlik Replicate - IBM DB2 for LUWを ソースおよびターゲットエンドポイントとして使用する
by
QlikPresalesJapan
詳説 Qlik Sense GeoOperations – Qlik Sense SaaSで地理データを計算する
by
QlikPresalesJapan
Qlik Replicateのファイルチャネルの利用
by
QlikPresalesJapan
Qlik Application Automation ~ テンプレートで素早く自動化フローを作成
by
QlikPresalesJapan
Qlik composeのご紹介
by
QlikPresalesJapan
Qlik Cloudデータ統合:Data Gateway - Data Movementのセットアップ
by
QlikPresalesJapan
Qlik ReplicateにおけるExpression Builderの利用方法
by
QlikPresalesJapan
Similar to Qlik Replicateでのタスクの定義と管理
PPTX
SAP Application(DB)のソースエンドポイントとしての利用
by
QlikPresalesJapan
PPTX
Qlik Replicate - 双方向レプリケーション(Bidirectional Replication)の利用
by
QlikPresalesJapan
PPTX
双方向レプリケーションの(Bidirectional Replication)の利用方法
by
QlikPresalesJapan
PDF
45分で理解する SQL Serverでできることできないこと
by
Insight Technology, Inc.
PPTX
SAP Applicationのソース・エンドポイントとしての利用
by
QlikPresalesJapan
KEY
オリジナルからデータ・ポンプに移植するツボ
by
真吾 吉田
PPTX
Microsoft Azure ADLSのターゲットエンドポイントとしての利用
by
QlikPresalesJapan
PPT
今年こそ始めたい!SQL超入門 MIRACLE Linux Meetup版 0620
by
Toru Miyahara
PDF
RWC2012(ワコムアイティ&テクノプロジェクト)
by
Techno Project Co., Ltd.
PDF
[INSIGHT OUT 2011] C12 50分で理解する SQL Serverでできることできないこと(uchiyama)
by
Insight Technology, Inc.
PPTX
ファイルのソース・ターゲットエンドポイントとしての利用
by
QlikPresalesJapan
PDF
iOS/Androidにも対応した SQL Anywhere 12の魅力
by
nisobe58
PDF
[db tech showcase Tokyo 2018] #dbts2018 #C17 『OracleからPostgreSQLへ移行する際のポイントとレ...
by
Insight Technology, Inc.
PDF
SQL Azure のシームレスな管理
by
junichi anno
PDF
04 Qlik Cloud データ統合 しっかり学ぶ勉強会 #4 データレプリケーションタスクの作成
by
QlikPresalesJapan
PDF
xDB Replication ブローシャー
by
Yuji Fujita
PPTX
Global Rule(変換・フィルターなど)の詳細
by
QlikPresalesJapan
PDF
DBP-009_クラウドで実現するスケーラブルなデータ ウェアハウス Azure SQL Data Warehouse 解説
by
decode2016
PPTX
Microsoft Azure SQLデータベースのターゲットエンドポイントとしての利用
by
QlikPresalesJapan
PDF
Tokyo Rubykaigi 01 t-wada
by
Takuto Wada
SAP Application(DB)のソースエンドポイントとしての利用
by
QlikPresalesJapan
Qlik Replicate - 双方向レプリケーション(Bidirectional Replication)の利用
by
QlikPresalesJapan
双方向レプリケーションの(Bidirectional Replication)の利用方法
by
QlikPresalesJapan
45分で理解する SQL Serverでできることできないこと
by
Insight Technology, Inc.
SAP Applicationのソース・エンドポイントとしての利用
by
QlikPresalesJapan
オリジナルからデータ・ポンプに移植するツボ
by
真吾 吉田
Microsoft Azure ADLSのターゲットエンドポイントとしての利用
by
QlikPresalesJapan
今年こそ始めたい!SQL超入門 MIRACLE Linux Meetup版 0620
by
Toru Miyahara
RWC2012(ワコムアイティ&テクノプロジェクト)
by
Techno Project Co., Ltd.
[INSIGHT OUT 2011] C12 50分で理解する SQL Serverでできることできないこと(uchiyama)
by
Insight Technology, Inc.
ファイルのソース・ターゲットエンドポイントとしての利用
by
QlikPresalesJapan
iOS/Androidにも対応した SQL Anywhere 12の魅力
by
nisobe58
[db tech showcase Tokyo 2018] #dbts2018 #C17 『OracleからPostgreSQLへ移行する際のポイントとレ...
by
Insight Technology, Inc.
SQL Azure のシームレスな管理
by
junichi anno
04 Qlik Cloud データ統合 しっかり学ぶ勉強会 #4 データレプリケーションタスクの作成
by
QlikPresalesJapan
xDB Replication ブローシャー
by
Yuji Fujita
Global Rule(変換・フィルターなど)の詳細
by
QlikPresalesJapan
DBP-009_クラウドで実現するスケーラブルなデータ ウェアハウス Azure SQL Data Warehouse 解説
by
decode2016
Microsoft Azure SQLデータベースのターゲットエンドポイントとしての利用
by
QlikPresalesJapan
Tokyo Rubykaigi 01 t-wada
by
Takuto Wada
More from QlikPresalesJapan
PPTX
20250819 Qlik Tips AI assistants (SQLアシスタントとデータモデルリレーションシップ)
by
QlikPresalesJapan
PPTX
カンタン! Apache IcebergをDockerで試す ~MinIO + Iceberg REST Catalog + Trino(CLI, JDB...
by
QlikPresalesJapan
PDF
20251216_Qlik TECH TALK セミナー Talend Dynamic Engine 実践セミナー 柔軟な実行基盤でデータ統合を加速する.pdf
by
QlikPresalesJapan
PPTX
Talend StudioでRoute(Apache Camel)を試す ~ファイルやメッセージキューなどを利用したESBによる連携~
by
QlikPresalesJapan
PDF
【Qlik TECH TALK】What’s New in Qlik 2025年11月リリース最新機能の紹介
by
QlikPresalesJapan
PPTX
Qlik Talend Cloud による RAG パイプライン(検索拡張生成パイプライン - ナレッジマートによるベクトル化とストア連携の紹介 -.pptx
by
QlikPresalesJapan
PPTX
Qlik TECH TALK セミナー:What's New In Qlik ~ 2025年8月リリース最新機能のご紹介 ~
by
QlikPresalesJapan
PPTX
Qlik Open Lakehouse 一般提供開始 Apache Iceberg を活用した モダンデータアーキテクチャ入門セミナー.pptx
by
QlikPresalesJapan
PPTX
Qlik Predictによる多変量時系列予測:複雑な要因を織り込んだビジネス予測を実践
by
QlikPresalesJapan
PPTX
Qlik Trust Score の計算方法について。Qlikが提供するデータの信頼性スコア「Trust Score」に焦点を当てます。
by
QlikPresalesJapan
PDF
分析アプリでの直接データ操作とリアルタイム情報共有を実現!Write Tableのご紹介
by
QlikPresalesJapan
PPTX
Qlik Talend Cloud Migration Toolkits ~Talend Cloud への移行準備と移行方法 ~
by
QlikPresalesJapan
PPTX
【Qlik TECH TALK】What’s New in Qlik 2025年9月リリース最新機能の紹介
by
QlikPresalesJapan
PDF
オンプレからクラウドへの移行が簡単になりました! Qlik Analytics Move to Cloud Toolのご紹介
by
QlikPresalesJapan
PPTX
Qlik TECH TALK セミナー:What's New In Qlik ~ 2025年10月リリース最新機能のご紹介 ~
by
QlikPresalesJapan
PPTX
Qlik TECH TALK セミナー:テーブルレシピ徹底活用術!~ Excel 感覚で スマートにデータ準備 ~
by
QlikPresalesJapan
PDF
20250916_QlikTips_Consumption_for_Analytics_QCAのキャパシティ容量の仕様に関する解説
by
QlikPresalesJapan
PPTX
【Qlik 医療データ活用勉強会】Qlikデータソン医療関連アプリの紹介、DPC分析ツールキットの提供
by
QlikPresalesJapan
PPTX
【Qlik 医療データ活用勉強会】 第53回 20251126 医療の質可視化アプリの公開
by
QlikPresalesJapan
PPTX
【Qlik 医療データ活用勉強会】医療の質分析(経皮的冠動脈形成術施行後の予後の測定)
by
QlikPresalesJapan
20250819 Qlik Tips AI assistants (SQLアシスタントとデータモデルリレーションシップ)
by
QlikPresalesJapan
カンタン! Apache IcebergをDockerで試す ~MinIO + Iceberg REST Catalog + Trino(CLI, JDB...
by
QlikPresalesJapan
20251216_Qlik TECH TALK セミナー Talend Dynamic Engine 実践セミナー 柔軟な実行基盤でデータ統合を加速する.pdf
by
QlikPresalesJapan
Talend StudioでRoute(Apache Camel)を試す ~ファイルやメッセージキューなどを利用したESBによる連携~
by
QlikPresalesJapan
【Qlik TECH TALK】What’s New in Qlik 2025年11月リリース最新機能の紹介
by
QlikPresalesJapan
Qlik Talend Cloud による RAG パイプライン(検索拡張生成パイプライン - ナレッジマートによるベクトル化とストア連携の紹介 -.pptx
by
QlikPresalesJapan
Qlik TECH TALK セミナー:What's New In Qlik ~ 2025年8月リリース最新機能のご紹介 ~
by
QlikPresalesJapan
Qlik Open Lakehouse 一般提供開始 Apache Iceberg を活用した モダンデータアーキテクチャ入門セミナー.pptx
by
QlikPresalesJapan
Qlik Predictによる多変量時系列予測:複雑な要因を織り込んだビジネス予測を実践
by
QlikPresalesJapan
Qlik Trust Score の計算方法について。Qlikが提供するデータの信頼性スコア「Trust Score」に焦点を当てます。
by
QlikPresalesJapan
分析アプリでの直接データ操作とリアルタイム情報共有を実現!Write Tableのご紹介
by
QlikPresalesJapan
Qlik Talend Cloud Migration Toolkits ~Talend Cloud への移行準備と移行方法 ~
by
QlikPresalesJapan
【Qlik TECH TALK】What’s New in Qlik 2025年9月リリース最新機能の紹介
by
QlikPresalesJapan
オンプレからクラウドへの移行が簡単になりました! Qlik Analytics Move to Cloud Toolのご紹介
by
QlikPresalesJapan
Qlik TECH TALK セミナー:What's New In Qlik ~ 2025年10月リリース最新機能のご紹介 ~
by
QlikPresalesJapan
Qlik TECH TALK セミナー:テーブルレシピ徹底活用術!~ Excel 感覚で スマートにデータ準備 ~
by
QlikPresalesJapan
20250916_QlikTips_Consumption_for_Analytics_QCAのキャパシティ容量の仕様に関する解説
by
QlikPresalesJapan
【Qlik 医療データ活用勉強会】Qlikデータソン医療関連アプリの紹介、DPC分析ツールキットの提供
by
QlikPresalesJapan
【Qlik 医療データ活用勉強会】 第53回 20251126 医療の質可視化アプリの公開
by
QlikPresalesJapan
【Qlik 医療データ活用勉強会】医療の質分析(経皮的冠動脈形成術施行後の予後の測定)
by
QlikPresalesJapan
Qlik Replicateでのタスクの定義と管理
1.
© 2019 QlikTech
International AB. All rights reserved. Qlik Replicateでの タスクの定義と管理 クリックテック・ジャパン株式会社
2.
2 タスクの定義と管理 ンソールの使用 ここでは、レプリケーションタスクの設計方法について説明します。タスクを設計するには、まず、少なくとも 1つのソース エンドポイント と1つのターゲット
エンドポイントをQlik Replicateと連携するように構成しておく必要があります。 ※ タスク構成 (レプリケートされるテーブルの数など)、ソーステーブルのサイズ、Replicateサーバーマシンのハードウェア構成などの 複数の要素が1つのReplicateサーバーで実行できるタスクの量に影響します。 ※ このことを念頭に置いて、1つのレプリケートサーバーで同時に実行するタスクの数は100を超えないようにしてください。 (前 述の要素などに応じて、可能な同時実行数が少なくなる場合があります)。 ※ ベストプラクティスは、本番環境に移行する前にテスト環境でロードテストを実行することです。
3.
3 タスクの概要 ンソールの使用 • ソースエンドポイントとターゲットエンドポイント • 同期して保持するソーステーブルとターゲットテーブル •
関連するソーステーブルの列 • (オプション)1 つ以上のソース列の値に対する とのフィルター条件 (SQLite構文で記述) • (オプション)ターゲット表の列 。それらはデータ型と値(SQL構文の式また は関数が利用可能)を含みます。 指定しない場合、Replicateはソース テーブルと同じ列名と値を使用し、ソース DBMS データ型をターゲット DBMSデータ型にデフォルトでマッピングします。 タスクが定義されると、すぐにアクティブ化できます。レプリケートは、必要なメタ データ定義を含むターゲット テーブルを自動的に作成してロードし、CDC をア クティブにします。Qlik レプリケートコンソールを使用すると、レプリケーションプロ セスを監視、停止、または再開できます。 タスクは、ブラウザを通じてQlik Replicateコンソールを使用して定義します。タスクを定義する際には、以下を指定します。
4.
4 複数タスクの利用 複数のレプリケーションタスクを一度に定義してアクティブ化できます。これは、以下のようなケースのタスクの場合に最適です: • 異なるソーステーブルを持つ • いくつかのソース
テーブルを共有するが、ソース行で異なるフィルター条件を持つ • 異なるターゲット表を更新する ※ 同じターゲット表および行を2つの異なるレプリケーション・タスクで更新すると予測不能な結果を招く可能性があります。 異なるタスクは独立して動作し、同時に実行できます。それぞれに独自の初期ロード、CDC、およびログリーダープロセスがあります。
5.
5 タスクの追加
6.
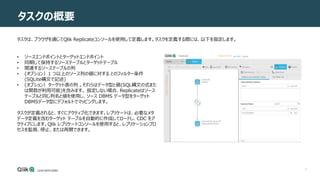
6 タスクの追加 ンソールの使用 タスクを追加するには: 1.[Tasks] ビューで、[New Task]
をクリックします。 2. タスクの名前を入力します。この名前は、タスクの目的を示すわ かりやすい名前にする必要があります。名前は32 文字以下で 、英数字以外の文字や|¥ / : * ?“ < >の文字は含めること ができません。 3. 必要に応じて、タスクの説明を[Description]に入力します。 タスクに必要な機能の設計を開始する前に、まずタスクの既定の動作を定義する必要があります。
7.
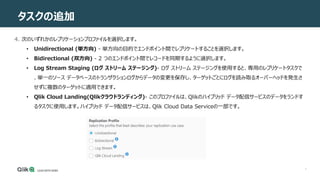
7 タスクの追加 ンソールの使用 4. 次のいずれかのレプリケーションプロファイルを選択します。 • Unidirectional
(単方向) - 単方向の目的でエンドポイント間でレプリケートすることを選択します。 • Bidirectional (双方向) - 2 つのエンドポイント間でレコードを同期するように選択します。 • Log Stream Staging (ログ ストリーム ステージング)- ログ ストリーム ステージングを使用すると、専用のレプリケートタスクで 、単一のソース データベースのトランザクションログからデータの変更を保存し、ターゲットごとにログを読み取るオーバーヘッドを発生さ せずに複数のターゲットに適用できます。 • Qlik Cloud Landing(Qlikクラウドランディング)- このプロファイルは、Qlikのハイブリッド データ配信サービスのデータをランドす るタスクに使用します。ハイブリッド データ配信サービスは、Qlik Cloud Data Serviceの一部です。
8.
8 タスクの追加 ンソールの使用 5. タスクオプションを選択します: • Full
Load: Full Loadが有効な場合、Qlik Replicateは、初期ソースデータをターゲットエンドポイントに読み込みます。 • Apply Changes: このオプションが有効になっている場合、Qlik レプリケートによって変更が処理 (INSERT/UPDATE/DELETE/DDL)されます。 ※ Bidirectionalが選択されている場合、変更のApply Changesオプションを無効にすることはできません。 • Store Change: このオプションが有効な場合、変更が変更テーブル(Change Table)または監査テーブル(Audit Table)に格 納されます。 6. [OK] をクリックして [New Task] ダイアログ ボックスを閉じ、設定を保存します。
9.
9 タスク説明の編集と表示 ンソールの使用 特定のタスクの説明を入力し、必要に応じてその説明を簡単に表示または編集できます。 タスクの説明を表示または編集するには、 1. 目的のタスクを開きます。 2. [Description]ツールバー・ボタンをクリックします。 3.
説明を入力します。 4. [OK] をクリックします。
10.
10 エンドポイントの定義と管理
11.
11 エンドポイントの定義 ンソールの使用 タスクの設計を開始する前に、レプリケートサーバーにエンドポイントを追加する必要があります。レプリケートサーバーにエンドポイントを追加 する場合は、接続情報と適切なユーザー資格情報を指定する必要があります。 エンドポイントを追加するには: 1. [Tasks]ビューで、[Manage Endpoint Connections]
をクリックします。 2. [New Endpoint] をクリックします。 3. 使用しているエンドポイントの種類を選択します。入 力する必要がある情報は、選択するエンドポイントに よって異なります。 ※ エンドポイントの名前は32 文字以下で、英数字以外の文字や|¥ / : * ?“ < >の文字は含めることができません。 ※ サポートされるデータベースの一覧については、「サポートされるプラットフォームとエンドポイント」を参照してください。
12.
12 タスクへのソースエンドポイントとターゲットエンドポイントの追加 ンソールの使用 エンドポイントを追加したら、タスクを設計できます。このプロセスの最初の手順では、データが現在格納されているソースエンドポイントと、データをレ プリケートするターゲットエンドポイントを定義します。これを行うには、エンドポイントのいずれかをタスクマップにドラッグします(Designerモード)。 ソース・ターゲット エンドポイントをタスクに追加するには: 1. 新しいタスクを作成します。左側のペインに使用可能なエンドポイント が表示された状態で、タスク
マップが表示されます。 2. ソース エンドポイントを、タスクマップの上部の円 にドラッグします。 3. ターゲットエンドポイントを、タスクマップの下のにドラッグします。 4. [Save]をクリックします。 ※ 円にエンドポイントをドラッグできない場合は、使用しているエンドポイントがソースもしくはターゲットエンドポイントとして定義されていることを確認してください。
13.
13 テーブルまたはビューの選択
14.
14 レプリケーションのテーブルまたはビューの選択 レプリケートするソース テーブルまたはビューを選択する方法について説明します。 • テーブル:サポートされている全てのエンドポイントで選択できます •
ビュー:次のエンドポイントでのみ選択できます。 太字を除き、Full Loadのみタスクでのみサポートされます。また、ビューはテーブルとして ターゲットエンドポイントにレプリケートされます。 • Teradata • Amazon Redshift • PostgreSQL • MySQL • SAP Sybase ASE • IBM DB2 for LUW • IBM DB2 for z/OS • Oracle • Microsoft SQL Server • ODBC with CDC • ODBC ※ビューをレプリケートする場合、対応するテーブルは主キーなしで作成されます。これは、ターゲットテーブルに主キーを持たさせる必要がある変更の適用タスクに関する問題を提示します。した がって、(上記の CDC 対応エンドポイントのいずれかを使用して) 変更の適用タスクも実行している場合は、変換を使用してターゲット テーブルごとに 1 つ以上の主キーを定義する必要が あります。 ※CDC および Teradata ソース エンドポイントで ODBC を操作する場合、レプリケートするビューとテーブルは同じコンテキスト フィールドを持つ必要があります。ビューだけをレプリケートする 場合は、すべてのビューに同じコンテキスト フィールドが必要です。
15.
15 レプリケーションのテーブルまたはビューの選択 テーブル/ビューを選択するには: 1. タスクを開き、Designerモードで、右側の [Table
Selection] をクリックします。 テーブル/ビューを選択したら、タスクを実行できます。ただし、必要に応じてターゲットエンドポイントのフィルタリングテーブル構 造の変換を行うこともできます。
16.
16 レプリケーションのテーブルまたはビューの選択 [Table Selection]によって開くウインドウは、データソースがビューをサポートしているかによって異なります。 テーブル・ビューがサポートされている場合 テーブルのみの場合 検索の対象が選択可能
17.
17 レプリケーションのテーブルまたはビューの検索 レプリケーションタスクに含める準備として、特定のテーブル/ビューを検索する方法について説明します。最初に、特定の条件に一致するテーブルを検索しま す。次に、必要なテーブル/ビューを検索結果から選択し、タスクに含めます。 テーブル/ビューを検索するには、次の手順を実行します。 1. Designerモードで、[Table Selection]
をクリックします。 2. ソース エンドポイントがビュー選択をサポートしている場合は、検索対象をAll、 Tables、Viewsから選択することができます。 3. [Schemas] ドロップダウン リストから、テーブル/ビュー スキーマを選択します。 4. 必要に応じて、 [Table] フィールドに、をレプリケートするテーブル/ビューの名前ま たは名前の一部を入力します。これを行わない場合、選択したスキーマ内のすべて のテーブル/ビューが検索されます。 5. [Search] をクリックして、テーブル/ビューの一覧を表示します。[Results]フィー ルドには、指定した検索条件に一致するテーブル/ビューが表示されます。 6. レプリケートの対象とするテーブルを選択して、右側の[Selected Tables]に追 加します。 7. [OK] をクリックします。
18.
18 テーブル/ビュー選択パターンの作成 以下のようなワイルドカード文字を利用してパターンを作成し、条件に合致するテーブル/ビューのみを選択することができます。 % : ワイルドカード文字(複数文字) _
: ワイルドカード文字(一文字) ワイルドカード文字は、標準文字として解釈されないようにエスケープする必要があります。エスケープ文字の規則はデータベースによって異なっているため、サ ポートされているエスケープ文字に関するガイダンスについては、データベースのヘルプを参照してください。例 (_がワイルドカード文字) は次のとおりです。 • MySQL and PostgreSQL - _ • Microsoft SQL Server - [_] • Oracle - Oracle の場合は、エスケープ文字内部パラメータを使用してカスタムエスケープ文字を定義します。 例) NorthwindスキーマのメンバーであるNorthwind. customer% テーブルを除くすべてのテーブルをレプリケートするパターンを次の例に示します。 Include Northwind.% Exclude Northwind.customer%
19.
19 テーブル/ビュー選択パターンの作成 テーブル/ビュー選択パターンを作成するには: 1. Designerビューの [Select
Tables] ダイアログ ボックスで、次のいずれかの操作を行います。 • [Schema] ドロップダウン リストからスキーマを選択します。 • [Table] フィールドに、テーブル/ビューの名前または名前の一部を入力します。 2.選択のアクションを以下のいずれかから選択します。 1.[Include]をクリックすると、選択基準に一致するすべてのテーブル/ビューが含まれます。 2.[Exclude]をクリックすると、選択基準に一致するテーブル/ビューが除外されます。 3.[OK] をクリックして[Select Tables]ダイアログ ボックスを閉じます。
20.
20 テーブル/ビュー選択パターンの作成 テーブル/ビュー選択パターンの対象テーブルを確認するには: • テーブル選択パターンを使用するときに含まれるすべてのテーブル/ビューを表示するには、Designerビューの [Full
Table List] タブをクリックします。 • [Full Table List]には、定義したテーブル パターンに含まれるすべてのテーブル/ビューと、明示的に選択したすべてのテーブル/ビューが一覧表示されます。
21.
21 読み込み順序の設定 選択した各テーブルの読み込み順序を設定できます。たとえば、選択したテーブルリストに異なるサイズのテーブルが含まれ、大きなテーブルの前に小さいテー ブルをロードする場合に便利です。テーブルのグループが同じロード順序で設定されている場合、レプリケートはテーブル ID に従ってテーブルをロードします。 ロード順序は、以下の場所で設定および変更できます: •
[Table Selection]のウインドウ上 • コンソールの右側にある[Patterns and Selected Tables]およ び[Full Table List]の一覧 読み込み順序を設定するには、次の手順を実行します: 1. 一覧からテーブルを選択します。 2. [Load Order] ドロップダウン リストから、使用可能な優先度レベ ル(Lowest Priority, Low Priority, Normal Priority, High Priority, Highest Priority) のいずれかを選択します。 ※ 初期ロード実行後にテーブルを追加する場合などを除いて、アルファベット順にロードされます。 ※ テーブルに数値が含まれる場合、Table1>Table2>Table21>Table3 という順になります。 ※ タスクの実行中は、読み込み順序を変更できません。ロード順序を変更する場合は、まずタスク を停止し、必要に応じてロード順序を変更し、最後にターゲットをリロードします。 ※ [Exclude]パターンに対して読み込み順序を設定することはできません。
22.
22 タスクの移行
23.
23 タスクの移行 • レプリケーションタスクをファイルにエクスポートできます。 • タスクのインポートとエクスポートは、コマンド・ラインまたはQlik
Replicateコンソールを使用して行うことができます。 コマンドラインを使用してタスクをエクスポートすると、エクスポートされたすべてのタスクは、 <product_dir>/Qlik/Replicate/Data の下のimports フォルダーに保存されます。 Qlik レプリケートコンソールを使用してタスクをエクスポートする場合、次のいずれかが発生します (ブラウザーの設定に従います)。 タスク JSON ファイルは自動的にデフォルトのダウンロード場所にダウンロードされます ダウンロード場所の入力を求められます • エクスポート ファイル (*.json) をQlik レプリケートサーバーの別のインスタンスにインポートできます。これにより、Qlik Replicateで作成し たタスクを別の環境で使用できます。たとえば、開発環境でタスクを作成し、そのタスクを運用環境で使用する場合などです。
24.
24 タスクのエクスポート Qlik Replicateコンソールを使用してタスクをエクスポートす るには、次の手順を実行します。 1.次のいずれかの操作を行います。 • [Tasks]タブで、エクスポートするタスクを選択し、 [Export
Task] ツールバーボタンをクリックするか、タ スクを右クリックして [Export Task] を選択します。 • タスクを開いた状態で、 [Export Task]ツールバーボ タンをクリックします。 2.ブラウザの設定に応じて、次のいずれかが発生します。 • タスク JSON ファイルは自動的にデフォルトのダウンロー ド場所にダウンロードされます • ダウンロード場所を指定するように求められます。この場 合は、JSON ファイルを希望の場所に保存します。 Qlik Replicateコンソールまたはコマンド ラインを使用してタスクをエクスポートする方法について説明します。
25.
25 タスクのエクスポート コマンド ラインを使用してタスクをエクスポートするには: 1. インポートするタスクを定義したQlik
Replicateコンピュータから、次の操作を実行してQlik Replicateコマンド ライン コンソールを開きます。 Windows の場合: 以下のいずれかを行います。 • [スタート]メニューの [すべてのプログラム] に移動し、[Qlik Replicate] をポイントして[Utilities ]をポイントし、[Qlik Replicate Command Line] を選択します。 • Windows コマンドライン コンソールを開き、ディレクトリを次のように変更することもできます。 <Qlik レプリケートインストール ディレクトリ>bin (デフォルト: C:Program FilesAttunityReplicatebin) Linux の場合: <Qlik レプリケートインストールパス>binで以下のコマンドを実行します。 source ./arep_login.sh 2. コマンドラインコンソールのプロンプトで、次のように入力します。 repctl -d data-directory exportrepository task=task_name[folder_name=path] 3. 既定では、エクスポートされたタスク設定を含むtask_name>.json <名前のファイルが<product_dir>dataimportsフォルダーに作成 されます。ファイルを別のフォルダーに作成する場合は、コマンドにfolder_name=pathパラメーターを含めます。 ※ <product_dir>dataフォルダがインストール中に既定以外の場所にインストールされた場合は、後で既定以外の場所に移動した場合は、 フォルダの場所をレプリケートする必要があります。 • これは、コマンドに-d <data_folder>パラメーターを含めることによって行われます。 例:repctl -d D:Data exportrepository task=mytask
26.
26 タスクのインポート Qlik Replicateコンソールまたはコマンド ラインを使用してタスクをインポートする方法について説明します。 Qlik
Replicateコンソールを使用してタスクをインポートする には、次の手順を実行します。 1. [Tasks]タブで、[Import Task] ツールバーボタンをクリッ クします。 2. インポートするタスク JSON ファイルを参照し、[Import Task] をクリックします。タスクがインポートされます。 ※ タスクをインポートする前に、移行先サーバー上のインポート対象のタスクが既に存在している場合には実行中か停止していることを確認してください。
27.
27 タスクのインポート タスクをインポートする Qlik Replicate
コンピュータから、Qlik Replicateコマンドラインコンソールを開いて以下のコマンドを実行します。 • タスクのエクスポートと同様の手順でQlik Replicateコマンド ライン コンソールを開きます。 • タスクをインポートするには、以下のコマンドを実行します。 importrepository [-d data-directory] json_file=<エクスポートした*.jsonファイルへのフルパス>。 例を示します。 importrepository -d D:MyData json_file=C:Temptables.json ※ インストール時に<product_dir>dataフォルダがデフォルト以外の場所にインストールされていた場合や、後にデフォルト以外の場 所に移動された場合は、Replicateにそのフォルダの場所を伝える必要があります。そのためには、コマンドに -d data_folder パラ メータを含める必要があります。 例) repctl -d D:MyData importrepository json_file=C:mytask.json ※ コマンドでタスクを別の環境にインポートする場合は、ファイルを2台目のQlik Replicateコンピュータの場所にコピーして、そこからイン ポートする必要があります。
28.
28 エクスポートされた (json) ファイルの編集 •
*.json ファイルは、任意のプレーンテキストエディタで開くことができ、ファイル内のセクションを変更することができます。 • ただし、データは変更するだけで、フィールド名は変更しないようにしてください。 たとえば、エントリ“name”::DB_Name“について、この場合、 DB_Nameのデータを変更することはできます ”が、メタ データ (“name”)は変更できません。 • ファイルのインポート後に、Qlik Replicateコンソールを使用してエンドポイント、テーブル、タスク、タスク設定、およびロガー設定 に関する情報を変更する必要があります。
29.
29 タスクのコピー・名前変更を行う場合 タスクのコピーや名前変更を行う場合、エクスポートしたjsonファイルのタスク名を変更してインポートします。
30.
www.qlik.com/sap
Download




![6
タスクの追加
ンソールの使用
タスクを追加するには:
1.[Tasks] ビューで、[New Task] をクリックします。
2. タスクの名前を入力します。この名前は、タスクの目的を示すわ
かりやすい名前にする必要があります。名前は32 文字以下で
、英数字以外の文字や|¥ / : * ?“ < >の文字は含めること
ができません。
3. 必要に応じて、タスクの説明を[Description]に入力します。
タスクに必要な機能の設計を開始する前に、まずタスクの既定の動作を定義する必要があります。](https://image.slidesharecdn.com/071definingandmanagingtasks-210902061213/85/Qlik-Replicate-6-320.jpg)
![8
タスクの追加
ンソールの使用
5. タスクオプションを選択します:
• Full Load: Full Loadが有効な場合、Qlik Replicateは、初期ソースデータをターゲットエンドポイントに読み込みます。
• Apply Changes: このオプションが有効になっている場合、Qlik レプリケートによって変更が処理
(INSERT/UPDATE/DELETE/DDL)されます。
※ Bidirectionalが選択されている場合、変更のApply Changesオプションを無効にすることはできません。
• Store Change: このオプションが有効な場合、変更が変更テーブル(Change Table)または監査テーブル(Audit Table)に格
納されます。
6. [OK] をクリックして [New Task] ダイアログ ボックスを閉じ、設定を保存します。](https://image.slidesharecdn.com/071definingandmanagingtasks-210902061213/85/Qlik-Replicate-8-320.jpg)
![9
タスク説明の編集と表示
ンソールの使用
特定のタスクの説明を入力し、必要に応じてその説明を簡単に表示または編集できます。
タスクの説明を表示または編集するには、
1. 目的のタスクを開きます。
2. [Description]ツールバー・ボタンをクリックします。
3. 説明を入力します。
4. [OK] をクリックします。](https://image.slidesharecdn.com/071definingandmanagingtasks-210902061213/85/Qlik-Replicate-9-320.jpg)

![11
エンドポイントの定義
ンソールの使用
タスクの設計を開始する前に、レプリケートサーバーにエンドポイントを追加する必要があります。レプリケートサーバーにエンドポイントを追加
する場合は、接続情報と適切なユーザー資格情報を指定する必要があります。
エンドポイントを追加するには:
1. [Tasks]ビューで、[Manage Endpoint
Connections] をクリックします。
2. [New Endpoint] をクリックします。
3. 使用しているエンドポイントの種類を選択します。入
力する必要がある情報は、選択するエンドポイントに
よって異なります。
※ エンドポイントの名前は32 文字以下で、英数字以外の文字や|¥ / : * ?“ < >の文字は含めることができません。
※ サポートされるデータベースの一覧については、「サポートされるプラットフォームとエンドポイント」を参照してください。](https://image.slidesharecdn.com/071definingandmanagingtasks-210902061213/85/Qlik-Replicate-11-320.jpg)
![12
タスクへのソースエンドポイントとターゲットエンドポイントの追加
ンソールの使用
エンドポイントを追加したら、タスクを設計できます。このプロセスの最初の手順では、データが現在格納されているソースエンドポイントと、データをレ
プリケートするターゲットエンドポイントを定義します。これを行うには、エンドポイントのいずれかをタスクマップにドラッグします(Designerモード)。
ソース・ターゲット エンドポイントをタスクに追加するには:
1. 新しいタスクを作成します。左側のペインに使用可能なエンドポイント
が表示された状態で、タスク マップが表示されます。
2. ソース エンドポイントを、タスクマップの上部の円 にドラッグします。
3. ターゲットエンドポイントを、タスクマップの下のにドラッグします。
4. [Save]をクリックします。
※ 円にエンドポイントをドラッグできない場合は、使用しているエンドポイントがソースもしくはターゲットエンドポイントとして定義されていることを確認してください。](https://image.slidesharecdn.com/071definingandmanagingtasks-210902061213/85/Qlik-Replicate-12-320.jpg)


![15
レプリケーションのテーブルまたはビューの選択
テーブル/ビューを選択するには:
1. タスクを開き、Designerモードで、右側の [Table Selection] をクリックします。
テーブル/ビューを選択したら、タスクを実行できます。ただし、必要に応じてターゲットエンドポイントのフィルタリングテーブル構
造の変換を行うこともできます。](https://image.slidesharecdn.com/071definingandmanagingtasks-210902061213/85/Qlik-Replicate-15-320.jpg)
![16
レプリケーションのテーブルまたはビューの選択
[Table Selection]によって開くウインドウは、データソースがビューをサポートしているかによって異なります。
テーブル・ビューがサポートされている場合
テーブルのみの場合
検索の対象が選択可能](https://image.slidesharecdn.com/071definingandmanagingtasks-210902061213/85/Qlik-Replicate-16-320.jpg)
![17
レプリケーションのテーブルまたはビューの検索
レプリケーションタスクに含める準備として、特定のテーブル/ビューを検索する方法について説明します。最初に、特定の条件に一致するテーブルを検索しま
す。次に、必要なテーブル/ビューを検索結果から選択し、タスクに含めます。
テーブル/ビューを検索するには、次の手順を実行します。
1. Designerモードで、[Table Selection] をクリックします。
2. ソース エンドポイントがビュー選択をサポートしている場合は、検索対象をAll、
Tables、Viewsから選択することができます。
3. [Schemas] ドロップダウン リストから、テーブル/ビュー スキーマを選択します。
4. 必要に応じて、 [Table] フィールドに、をレプリケートするテーブル/ビューの名前ま
たは名前の一部を入力します。これを行わない場合、選択したスキーマ内のすべて
のテーブル/ビューが検索されます。
5. [Search] をクリックして、テーブル/ビューの一覧を表示します。[Results]フィー
ルドには、指定した検索条件に一致するテーブル/ビューが表示されます。
6. レプリケートの対象とするテーブルを選択して、右側の[Selected Tables]に追
加します。
7. [OK] をクリックします。](https://image.slidesharecdn.com/071definingandmanagingtasks-210902061213/85/Qlik-Replicate-17-320.jpg)
![18
テーブル/ビュー選択パターンの作成
以下のようなワイルドカード文字を利用してパターンを作成し、条件に合致するテーブル/ビューのみを選択することができます。
% : ワイルドカード文字(複数文字)
_ : ワイルドカード文字(一文字)
ワイルドカード文字は、標準文字として解釈されないようにエスケープする必要があります。エスケープ文字の規則はデータベースによって異なっているため、サ
ポートされているエスケープ文字に関するガイダンスについては、データベースのヘルプを参照してください。例 (_がワイルドカード文字) は次のとおりです。
• MySQL and PostgreSQL - _
• Microsoft SQL Server - [_]
• Oracle - Oracle の場合は、エスケープ文字内部パラメータを使用してカスタムエスケープ文字を定義します。
例) NorthwindスキーマのメンバーであるNorthwind. customer% テーブルを除くすべてのテーブルをレプリケートするパターンを次の例に示します。
Include Northwind.%
Exclude Northwind.customer%](https://image.slidesharecdn.com/071definingandmanagingtasks-210902061213/85/Qlik-Replicate-18-320.jpg)
![19
テーブル/ビュー選択パターンの作成
テーブル/ビュー選択パターンを作成するには:
1. Designerビューの [Select Tables] ダイアログ ボックスで、次のいずれかの操作を行います。
• [Schema] ドロップダウン リストからスキーマを選択します。
• [Table] フィールドに、テーブル/ビューの名前または名前の一部を入力します。
2.選択のアクションを以下のいずれかから選択します。
1.[Include]をクリックすると、選択基準に一致するすべてのテーブル/ビューが含まれます。
2.[Exclude]をクリックすると、選択基準に一致するテーブル/ビューが除外されます。
3.[OK] をクリックして[Select Tables]ダイアログ ボックスを閉じます。](https://image.slidesharecdn.com/071definingandmanagingtasks-210902061213/85/Qlik-Replicate-19-320.jpg)
![20
テーブル/ビュー選択パターンの作成
テーブル/ビュー選択パターンの対象テーブルを確認するには:
• テーブル選択パターンを使用するときに含まれるすべてのテーブル/ビューを表示するには、Designerビューの [Full Table List] タブをクリックします。
• [Full Table List]には、定義したテーブル パターンに含まれるすべてのテーブル/ビューと、明示的に選択したすべてのテーブル/ビューが一覧表示されます。](https://image.slidesharecdn.com/071definingandmanagingtasks-210902061213/85/Qlik-Replicate-20-320.jpg)
![21
読み込み順序の設定
選択した各テーブルの読み込み順序を設定できます。たとえば、選択したテーブルリストに異なるサイズのテーブルが含まれ、大きなテーブルの前に小さいテー
ブルをロードする場合に便利です。テーブルのグループが同じロード順序で設定されている場合、レプリケートはテーブル ID に従ってテーブルをロードします。
ロード順序は、以下の場所で設定および変更できます:
• [Table Selection]のウインドウ上
• コンソールの右側にある[Patterns and Selected Tables]およ
び[Full Table List]の一覧
読み込み順序を設定するには、次の手順を実行します:
1. 一覧からテーブルを選択します。
2. [Load Order] ドロップダウン リストから、使用可能な優先度レベ
ル(Lowest Priority, Low Priority, Normal Priority, High
Priority, Highest Priority) のいずれかを選択します。
※ 初期ロード実行後にテーブルを追加する場合などを除いて、アルファベット順にロードされます。
※ テーブルに数値が含まれる場合、Table1>Table2>Table21>Table3 という順になります。
※ タスクの実行中は、読み込み順序を変更できません。ロード順序を変更する場合は、まずタスク
を停止し、必要に応じてロード順序を変更し、最後にターゲットをリロードします。
※ [Exclude]パターンに対して読み込み順序を設定することはできません。](https://image.slidesharecdn.com/071definingandmanagingtasks-210902061213/85/Qlik-Replicate-21-320.jpg)


![24
タスクのエクスポート
Qlik Replicateコンソールを使用してタスクをエクスポートす
るには、次の手順を実行します。
1.次のいずれかの操作を行います。
• [Tasks]タブで、エクスポートするタスクを選択し、
[Export Task] ツールバーボタンをクリックするか、タ
スクを右クリックして [Export Task] を選択します。
• タスクを開いた状態で、 [Export Task]ツールバーボ
タンをクリックします。
2.ブラウザの設定に応じて、次のいずれかが発生します。
• タスク JSON ファイルは自動的にデフォルトのダウンロー
ド場所にダウンロードされます
• ダウンロード場所を指定するように求められます。この場
合は、JSON ファイルを希望の場所に保存します。
Qlik Replicateコンソールまたはコマンド ラインを使用してタスクをエクスポートする方法について説明します。](https://image.slidesharecdn.com/071definingandmanagingtasks-210902061213/85/Qlik-Replicate-24-320.jpg)
![25
タスクのエクスポート
コマンド ラインを使用してタスクをエクスポートするには:
1. インポートするタスクを定義したQlik Replicateコンピュータから、次の操作を実行してQlik Replicateコマンド ライン コンソールを開きます。
Windows の場合: 以下のいずれかを行います。
• [スタート]メニューの [すべてのプログラム] に移動し、[Qlik Replicate] をポイントして[Utilities ]をポイントし、[Qlik
Replicate Command Line] を選択します。
• Windows コマンドライン コンソールを開き、ディレクトリを次のように変更することもできます。
<Qlik レプリケートインストール ディレクトリ>bin (デフォルト: C:Program FilesAttunityReplicatebin)
Linux の場合: <Qlik レプリケートインストールパス>binで以下のコマンドを実行します。
source ./arep_login.sh
2. コマンドラインコンソールのプロンプトで、次のように入力します。
repctl -d data-directory exportrepository task=task_name[folder_name=path]
3. 既定では、エクスポートされたタスク設定を含むtask_name>.json <名前のファイルが<product_dir>dataimportsフォルダーに作成
されます。ファイルを別のフォルダーに作成する場合は、コマンドにfolder_name=pathパラメーターを含めます。
※ <product_dir>dataフォルダがインストール中に既定以外の場所にインストールされた場合は、後で既定以外の場所に移動した場合は、
フォルダの場所をレプリケートする必要があります。
• これは、コマンドに-d <data_folder>パラメーターを含めることによって行われます。
例:repctl -d D:Data exportrepository task=mytask](https://image.slidesharecdn.com/071definingandmanagingtasks-210902061213/85/Qlik-Replicate-25-320.jpg)
![26
タスクのインポート
Qlik Replicateコンソールまたはコマンド ラインを使用してタスクをインポートする方法について説明します。
Qlik Replicateコンソールを使用してタスクをインポートする
には、次の手順を実行します。
1. [Tasks]タブで、[Import Task] ツールバーボタンをクリッ
クします。
2. インポートするタスク JSON ファイルを参照し、[Import
Task] をクリックします。タスクがインポートされます。
※ タスクをインポートする前に、移行先サーバー上のインポート対象のタスクが既に存在している場合には実行中か停止していることを確認してください。](https://image.slidesharecdn.com/071definingandmanagingtasks-210902061213/85/Qlik-Replicate-26-320.jpg)
![27
タスクのインポート
タスクをインポートする Qlik Replicate コンピュータから、Qlik Replicateコマンドラインコンソールを開いて以下のコマンドを実行します。
• タスクのエクスポートと同様の手順でQlik Replicateコマンド ライン コンソールを開きます。
• タスクをインポートするには、以下のコマンドを実行します。
importrepository [-d data-directory] json_file=<エクスポートした*.jsonファイルへのフルパス>。
例を示します。
importrepository -d D:MyData json_file=C:Temptables.json
※ インストール時に<product_dir>dataフォルダがデフォルト以外の場所にインストールされていた場合や、後にデフォルト以外の場
所に移動された場合は、Replicateにそのフォルダの場所を伝える必要があります。そのためには、コマンドに -d data_folder パラ
メータを含める必要があります。
例) repctl -d D:MyData importrepository json_file=C:mytask.json
※ コマンドでタスクを別の環境にインポートする場合は、ファイルを2台目のQlik Replicateコンピュータの場所にコピーして、そこからイン
ポートする必要があります。](https://image.slidesharecdn.com/071definingandmanagingtasks-210902061213/85/Qlik-Replicate-27-320.jpg)








































![[INSIGHT OUT 2011] C12 50分で理解する SQL Serverでできることできないこと(uchiyama)](https://cdn.slidesharecdn.com/ss_thumbnails/insightout2011c1250sqlserveruchiyama-111206190505-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2018] #dbts2018 #C17 『OracleからPostgreSQLへ移行する際のポイントとレ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts2018c17quest-180929165135-thumbnail.jpg?width=640&height=640&fit=bounds)


























