The document discusses memory management in Python, focusing on memory allocation, garbage collection, and strategies for optimizing memory usage. Key topics include managed versus unmanaged memory, reference counting, generational garbage collection, and the impact of the global interpreter lock on multithreading. The author provides practical tips for developers to improve memory efficiency and suggests resources for further reading on Python memory management.







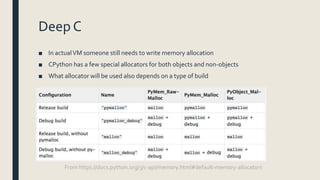
![Memory Allocation Layers
Physical Memory Swap
OS-specificVirtual Memory Manager
Kernel dynamic storage allocation & management (page-based)
General-purpose allocator (e.g. malloc)
Virtual memory allocated for the python process
Python’s raw memory allocator (PyMem API)
Python memory
Python’s object allocator
Object memory Internal buffers
[ int ] [ dict ] [ list ] [ string ]
Object-specific memory
Python Core
Non-object
memory
0
-1
-2
1
2
3](https://image.slidesharecdn.com/python-thanks-for-the-memories-190912153352/85/Python-Thanks-for-the-memories-9-320.jpg)



















![Generators
■ Very often you don’t really need to store the whole list/dict/etc.
■ Passing generator to a function looks prettier and usually more efficient
foo([x.bar for x in arr])
vs
foo(x.bar for x in arr)
■ Use generators as a first choice option for every new method returning a collection
■ Side effect: it will be easier to transform your code to be asynchronous](https://image.slidesharecdn.com/python-thanks-for-the-memories-190912153352/85/Python-Thanks-for-the-memories-30-320.jpg)
























































