Download as PDF, PPTX














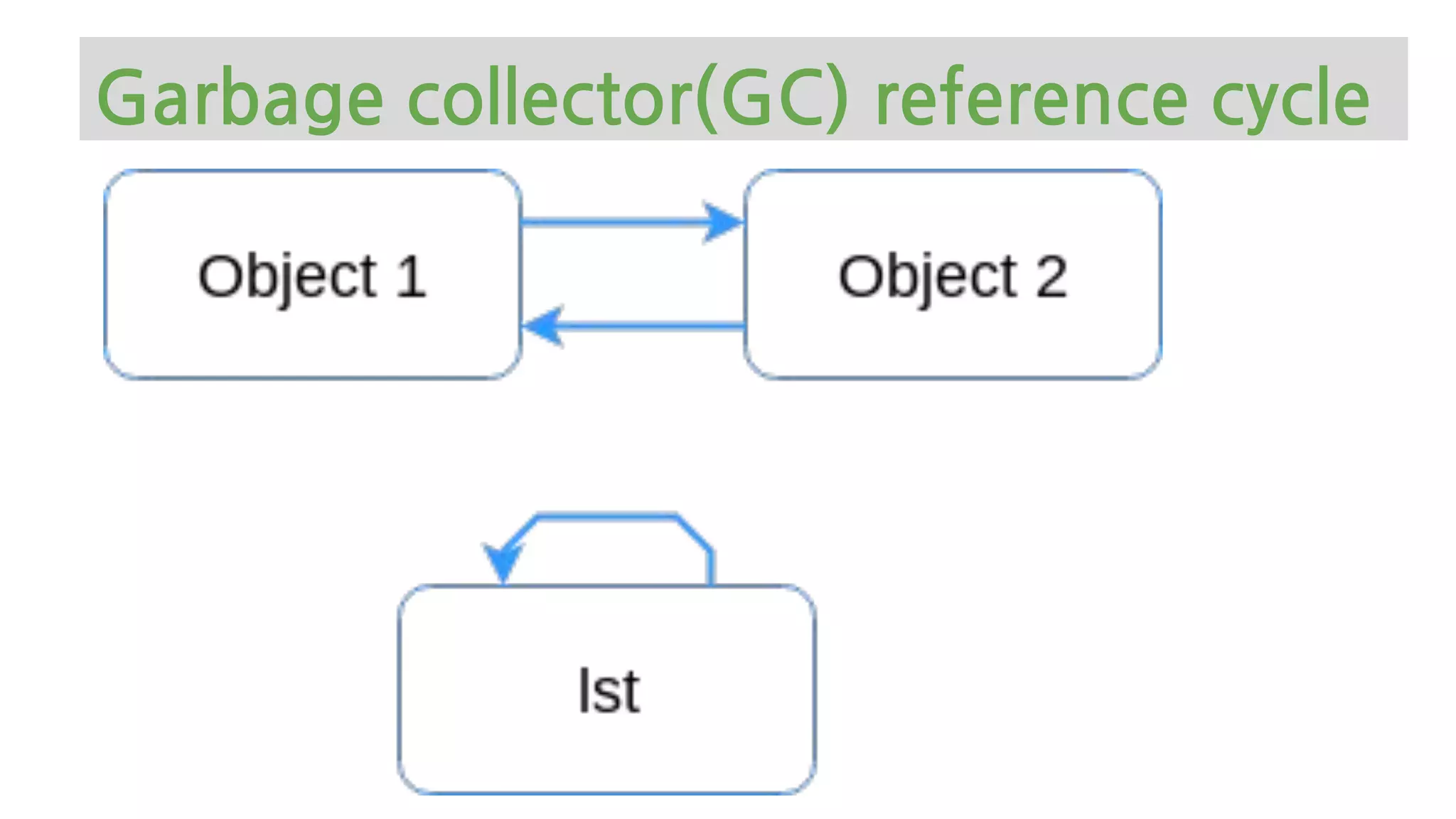
![>>> def ref_cycle():
... list = [1, 2, 3, 4]
... list.append(list)
... return list
Garbage collector(GC) reference cycle](https://image.slidesharecdn.com/europythonmemorymanagement-200729161140/75/Python-Memory-Management-101-Europython-28-2048.jpg)


![Python Object Graphs
https://mg.pov.lt/objgraph/
import objgraph
x = "hello"
y = [x, [x], list(x), dict(x=x)]
objgraph.show_refs([y],
filename='sample-graph.png')](https://image.slidesharecdn.com/europythonmemorymanagement-200729161140/75/Python-Memory-Management-101-Europython-31-2048.jpg)



![● Avoid List Slicing with [:]
list= [1,2,3,4]
list[1:3]
list[slice(1,3)]
Best practices for memory management](https://image.slidesharecdn.com/europythonmemorymanagement-200729161140/75/Python-Memory-Management-101-Europython-35-2048.jpg)



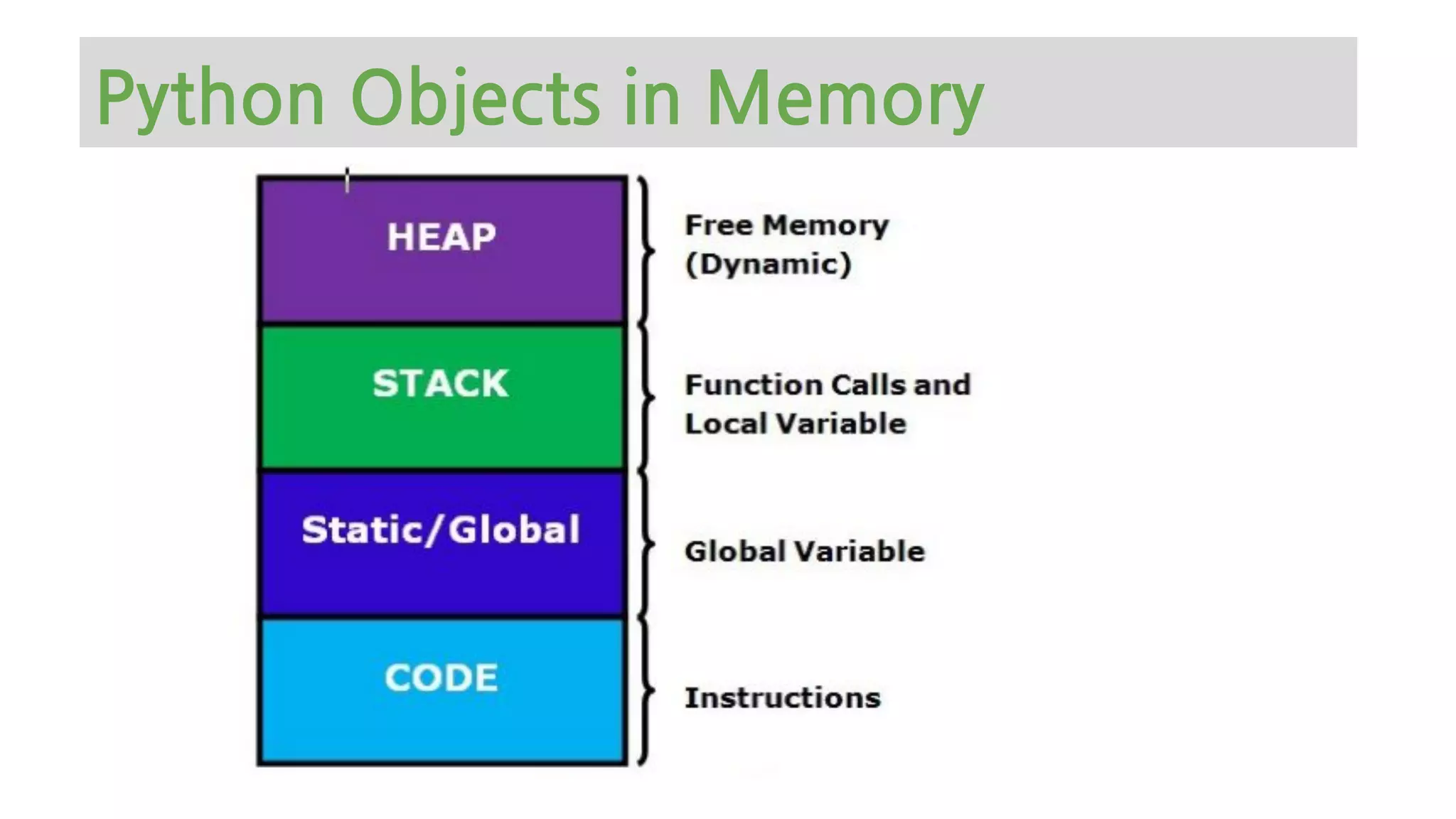
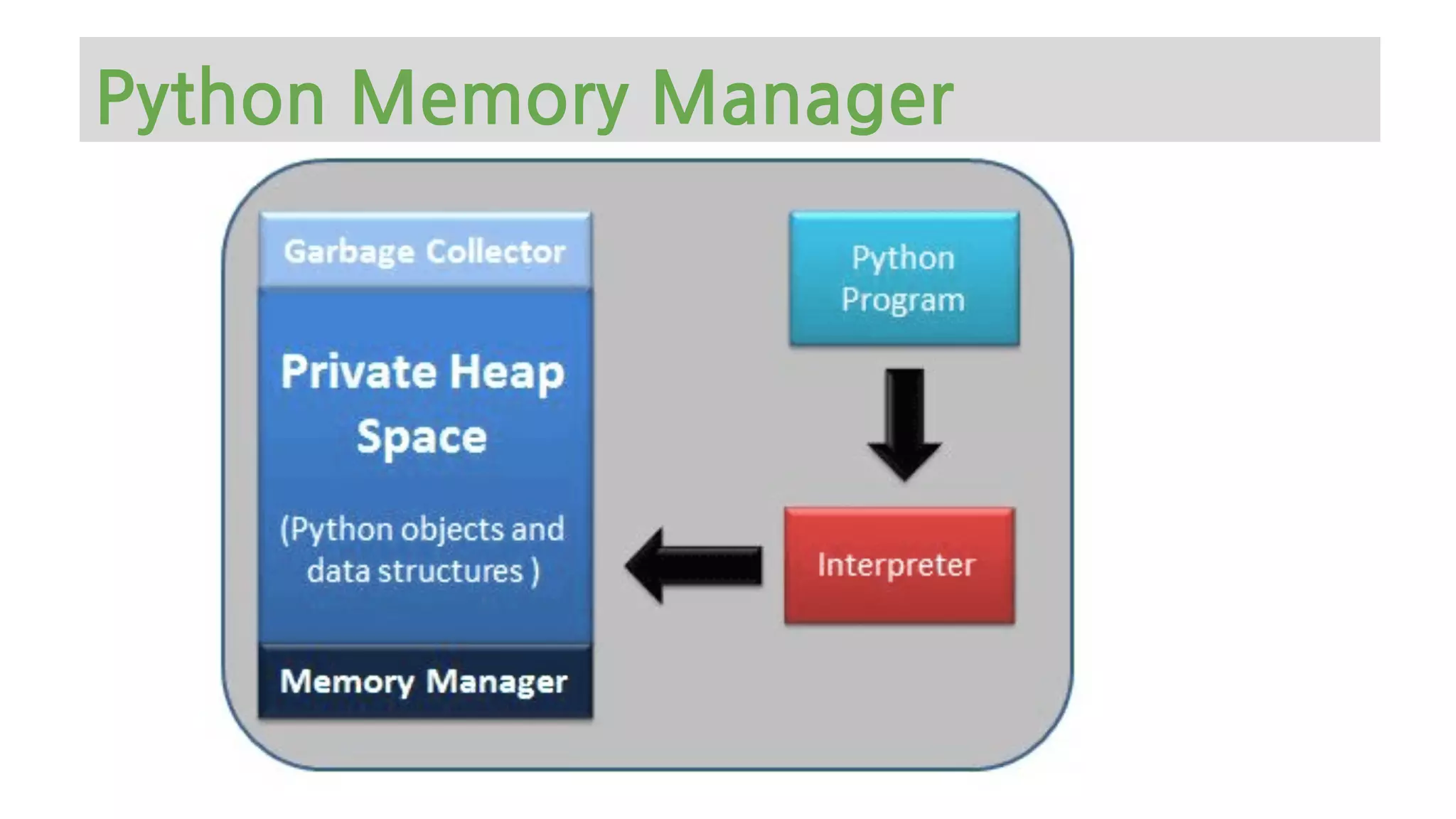
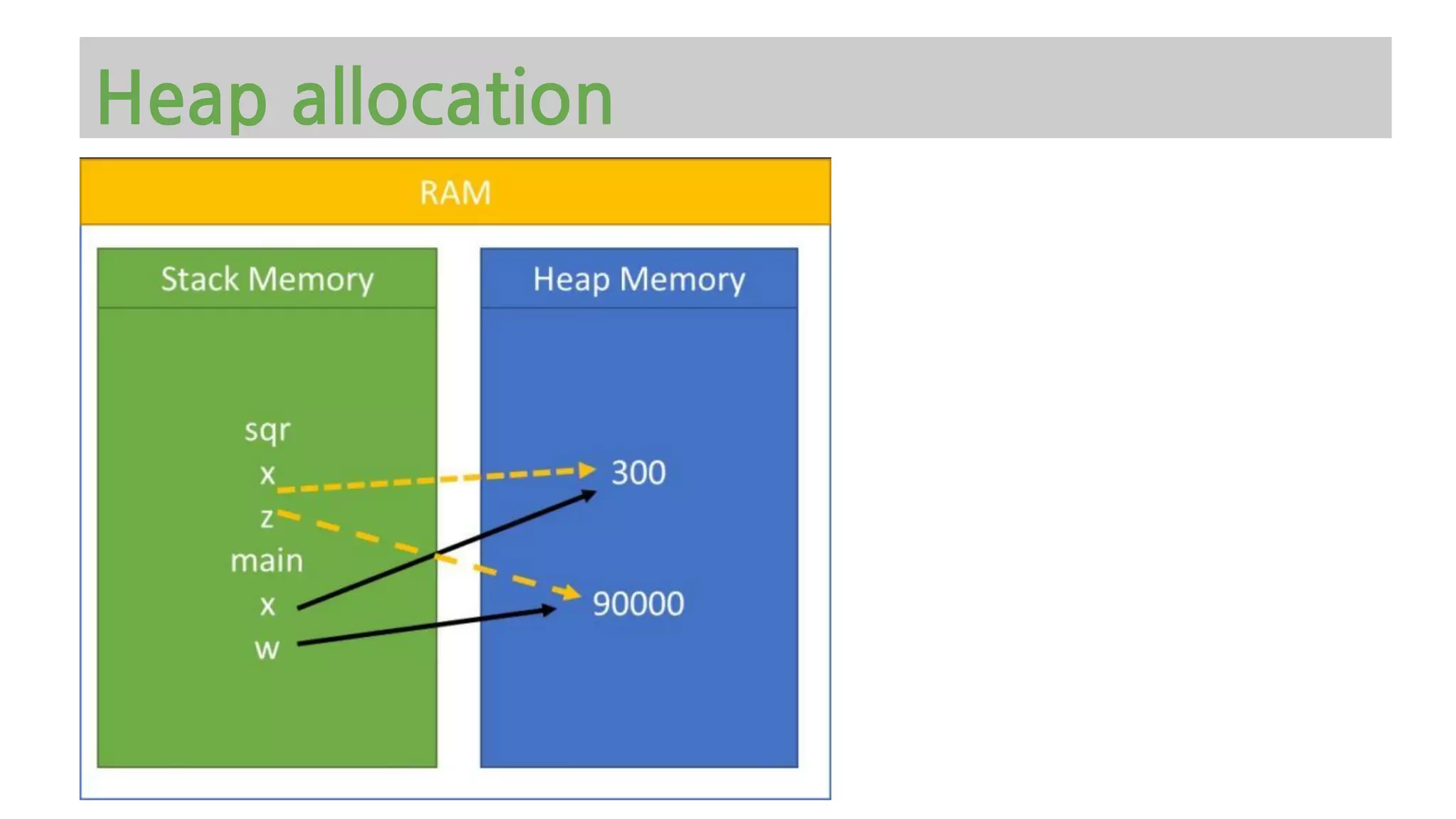
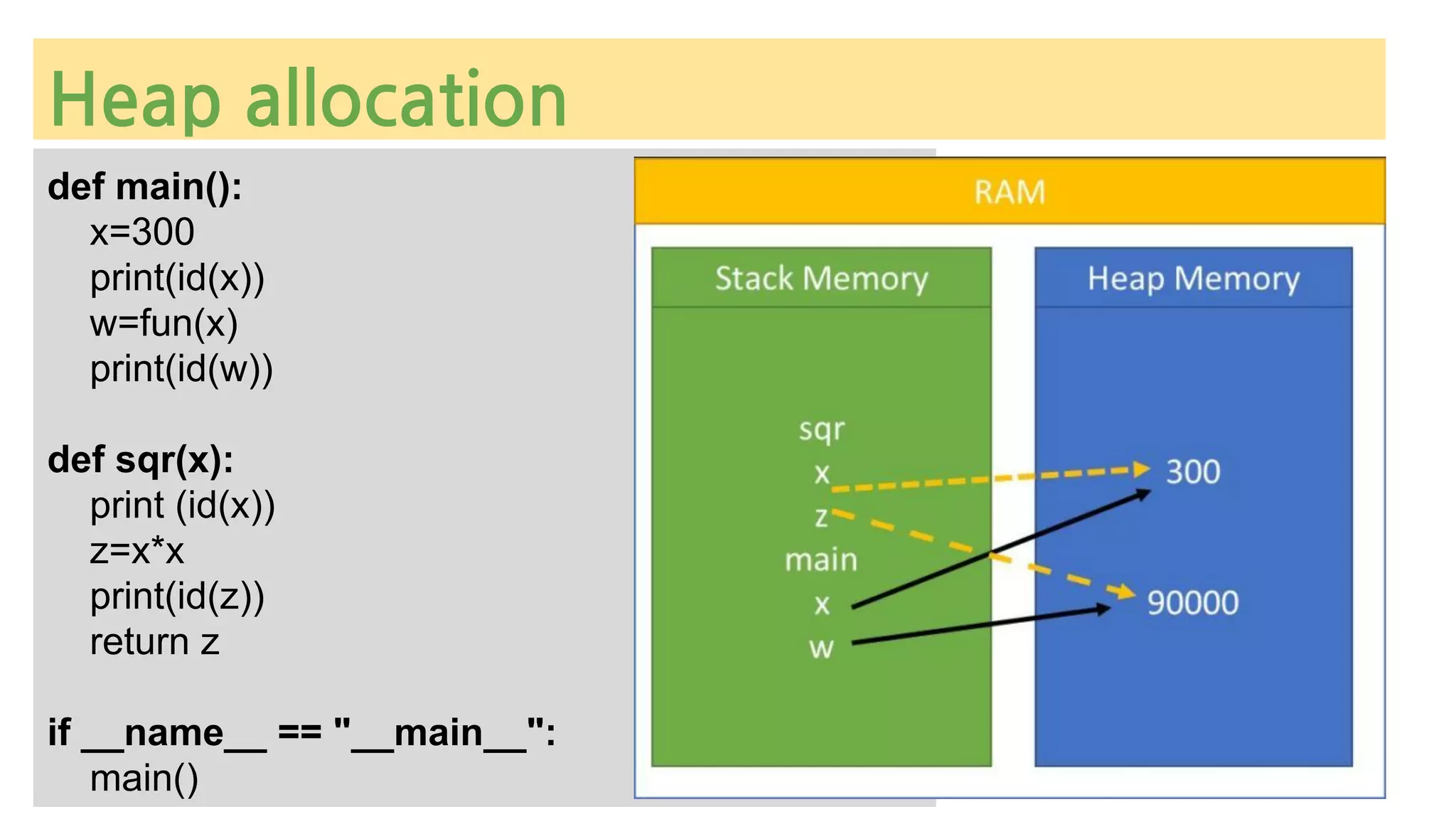
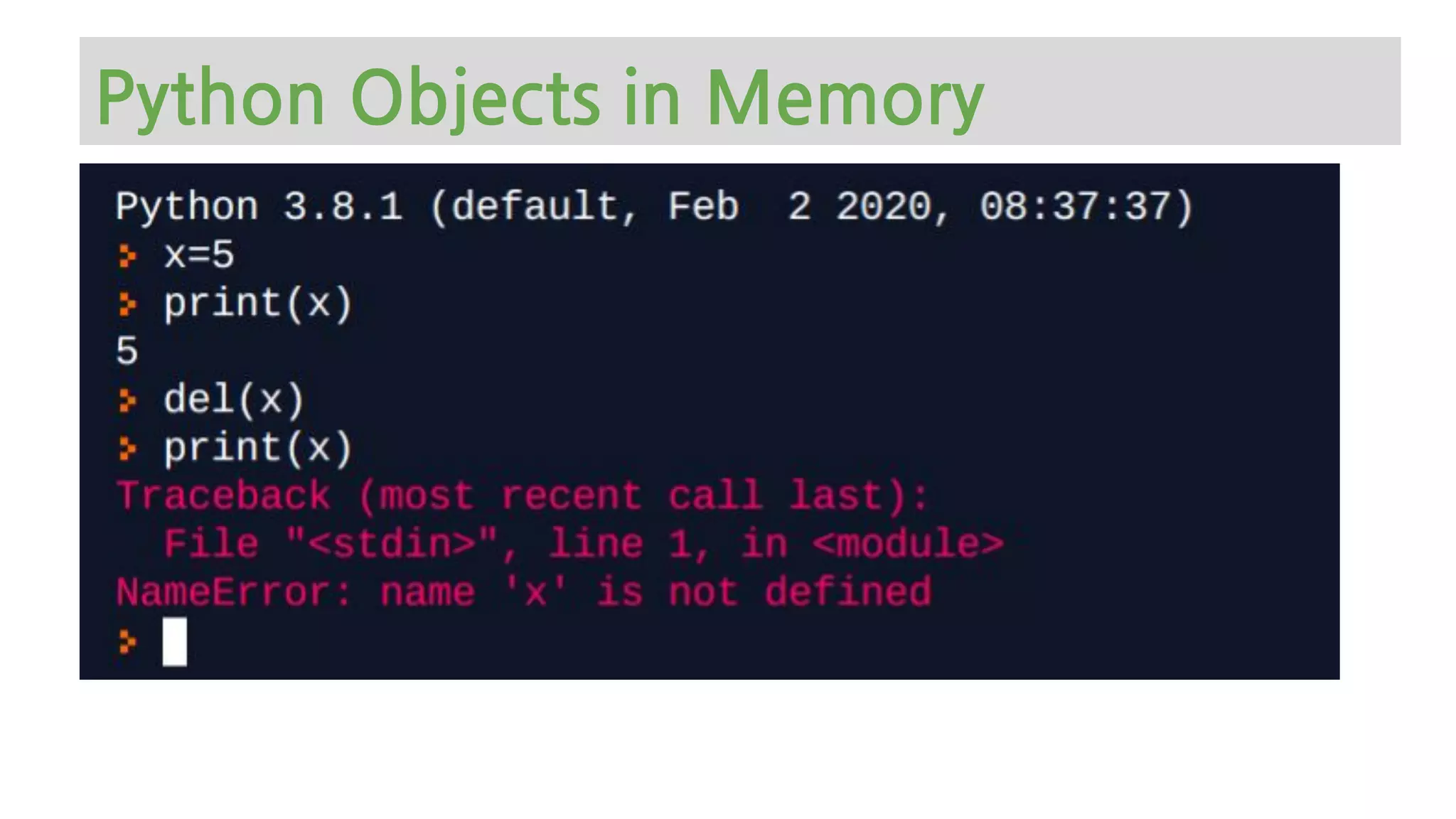
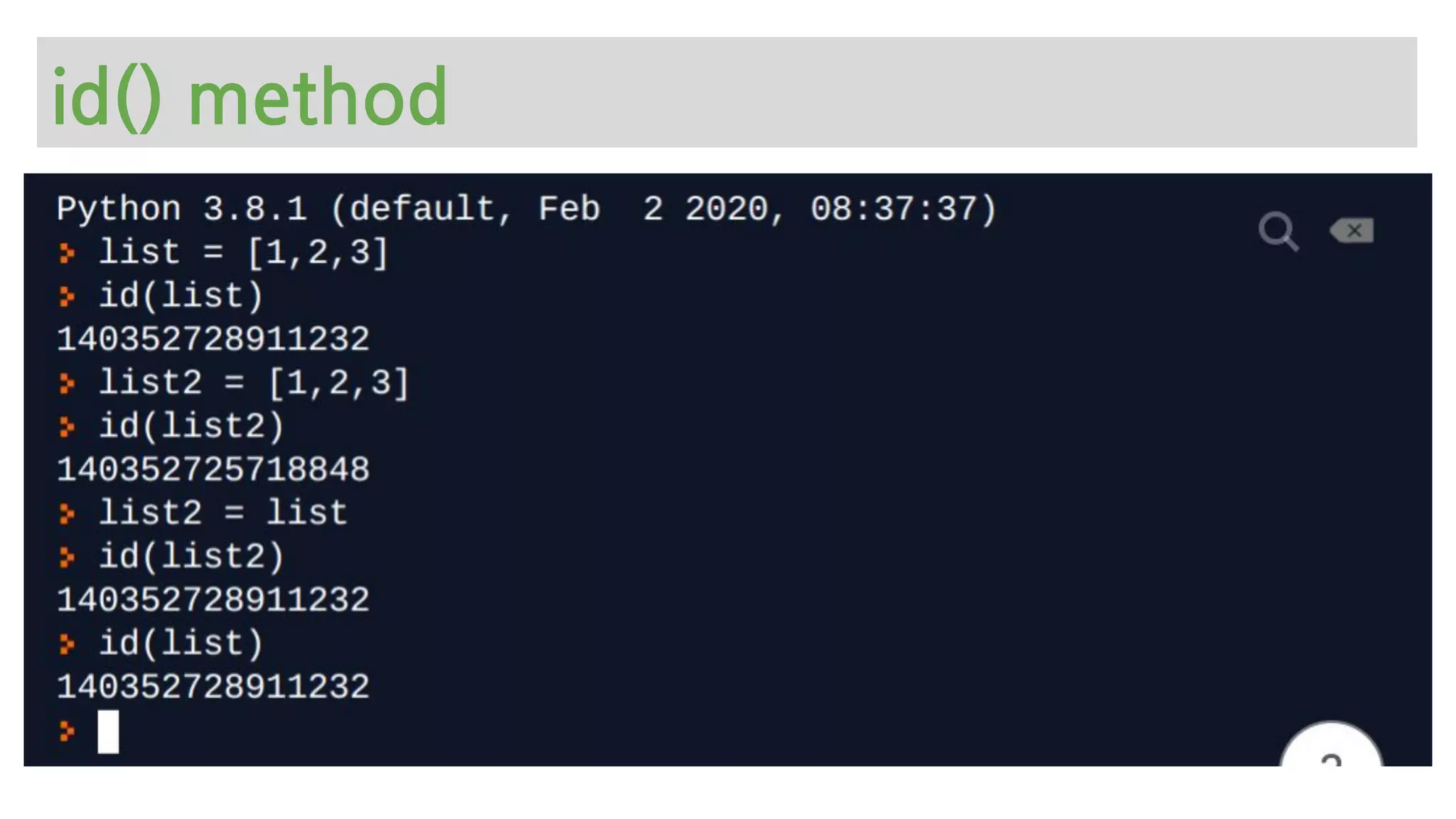
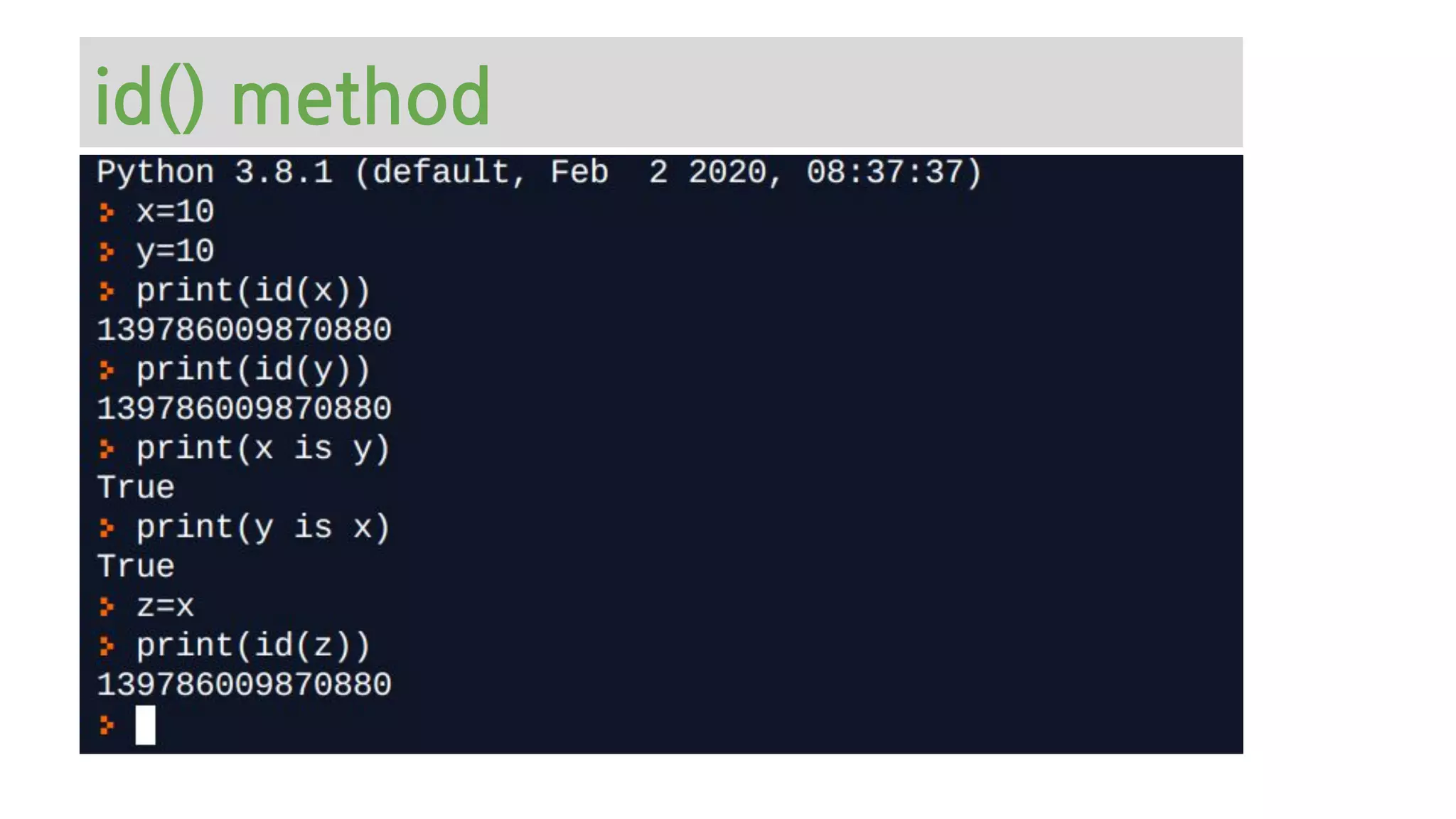
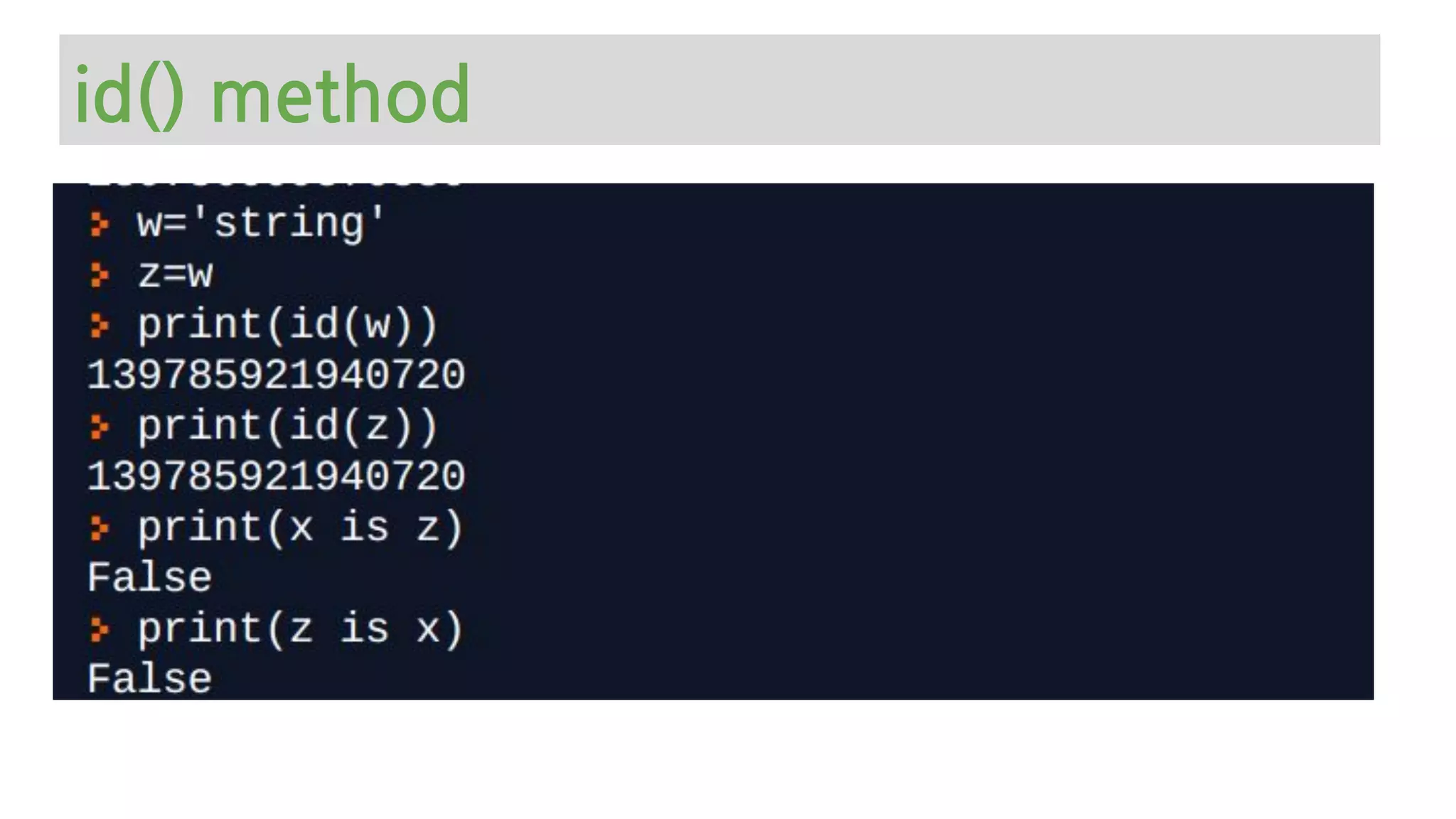
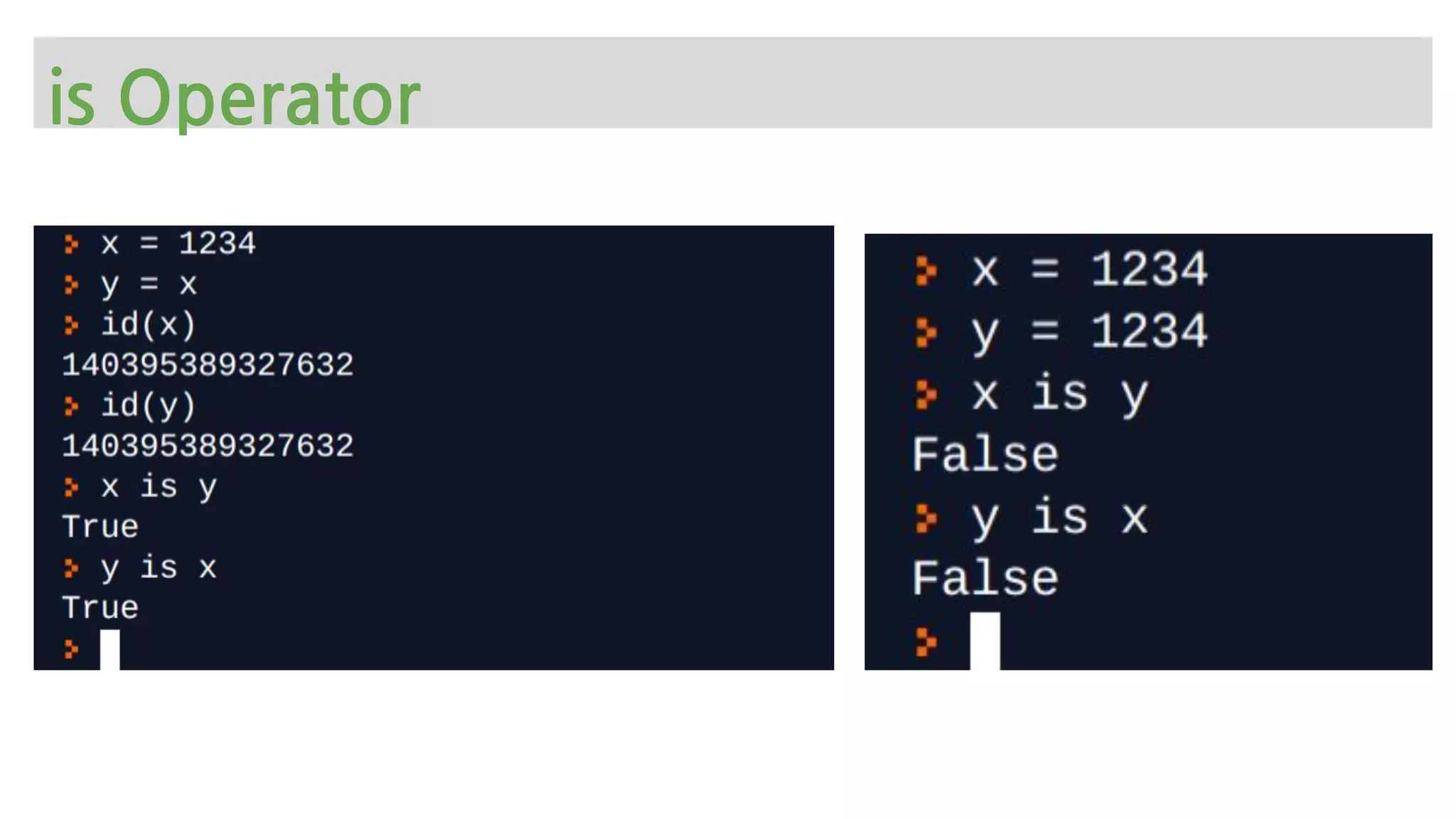
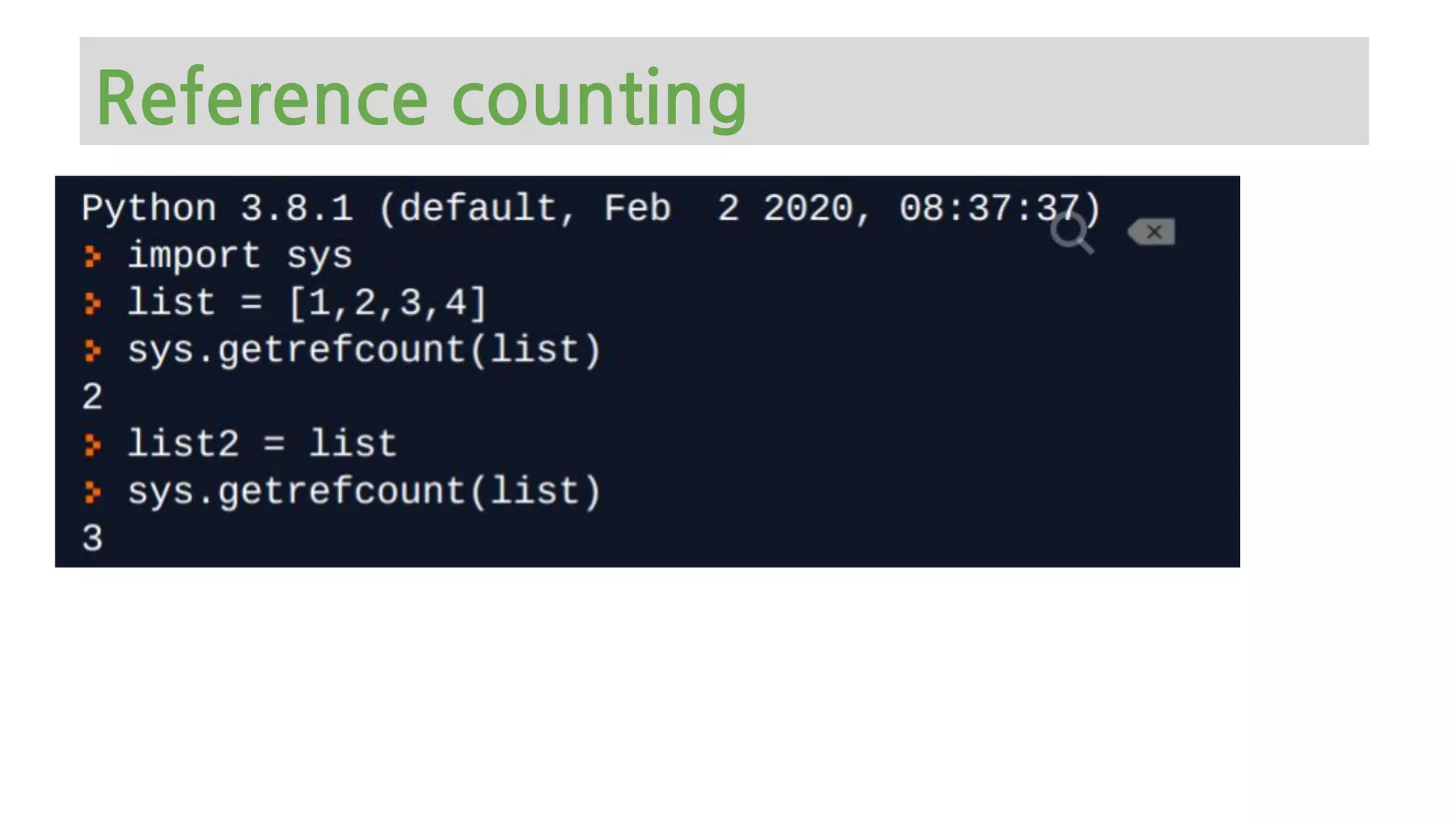
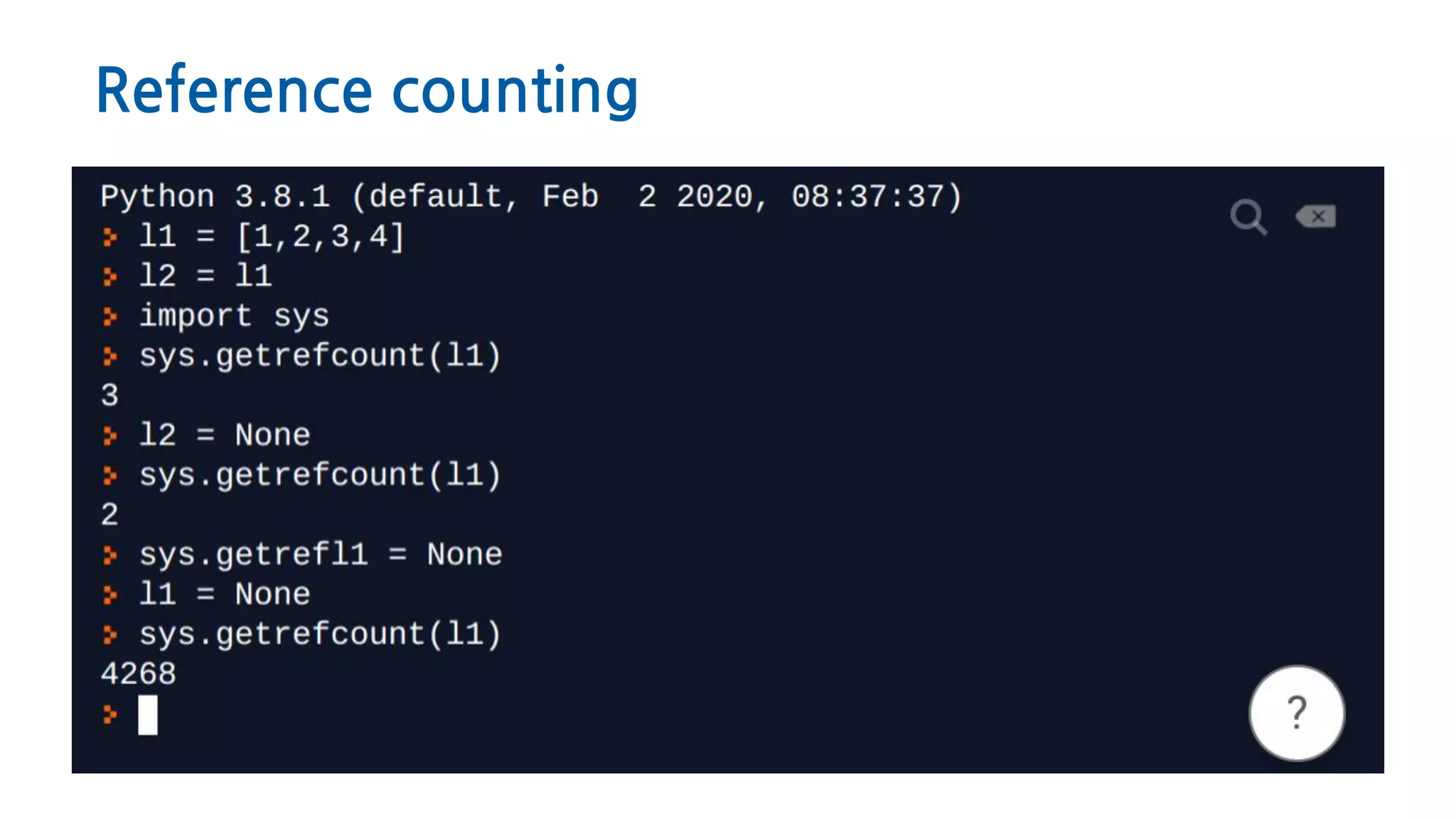
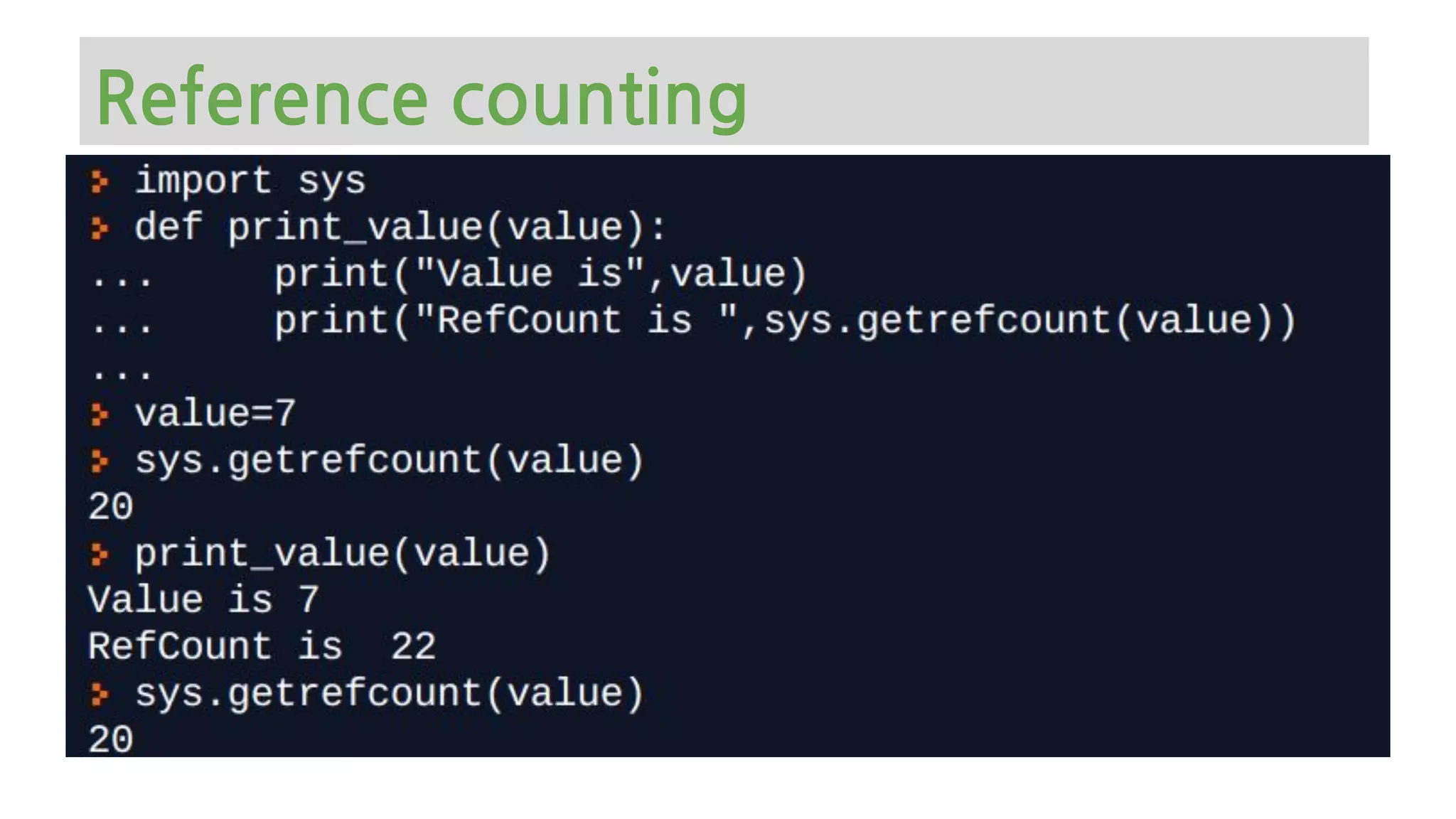
The document provides an overview of Python memory management, focusing on garbage collection and reference counting. It explains key concepts such as heap allocation, the id() method, and the workings of the garbage collector module, along with best practices for managing memory in Python. Additionally, it includes examples and links to resources for further reading on the topic.
























![Data Structures - Lecture 7 [Linked List]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture-7linkedlists-150121011916-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)






























































