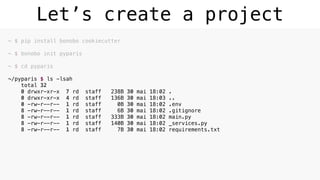
Download as PDF, PPTX







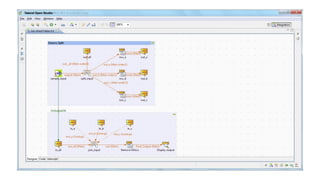
![Extract Transform Load
• Not new. Popular concept in the 1970s [1] [2]
• Everywhere. Commerce, websites, marketing, finance, …
• Update secondary data-stores from a master data-store.
• Insert initial data somewhere
• Bi-directional API calls
• Every day, compute time reports, edit invoices if threshold then send e-mail.
• …
[1] https://en.wikipedia.org/wiki/Extract,_transform,_load
[2] https://www.sas.com/en_us/insights/data-management/what-is-etl.html](https://image.slidesharecdn.com/pyparis-bonoboetl-170612154441/85/Simple-ETL-in-python-3-5-with-Bonobo-PyParis-2017-8-320.jpg)


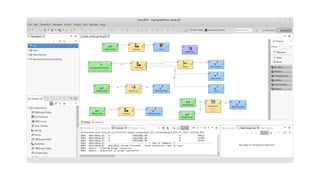






































![Classes!
from bonobo.config import Configurable, Option, Service
class QueryDatabase(Configurable):
# Simple string option
table_name = Option(str, default='customers')
# External dependency
database = Service('database.default')
def call(self, database, **row):
customer = database.query(self.table_name, customer_id=row['clientId'])
return {
**row,
'is_customer': bool(customer),
}](https://image.slidesharecdn.com/pyparis-bonoboetl-170612154441/85/Simple-ETL-in-python-3-5-with-Bonobo-PyParis-2017-54-320.jpg)















![Docker Extension
$ pip install bonobo[docker]
$ bonobo runc myjob.py
PREVIEW](https://image.slidesharecdn.com/pyparis-bonoboetl-170612154441/85/Simple-ETL-in-python-3-5-with-Bonobo-PyParis-2017-71-320.jpg)












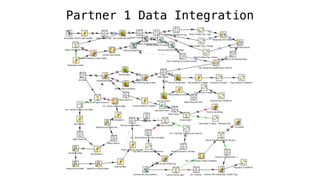
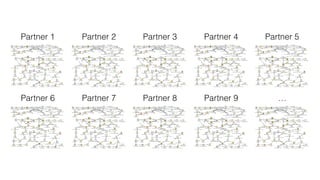
The document discusses Bonobo, a simple ETL framework for Python 3.5 and above, designed for data integration using code as configuration. It emphasizes Bonobo's ability to create, manage, and execute ETL jobs easily, incorporating libraries like joblib and pandas, while noting its distinct features compared to existing tools. The text also outlines the history, current status, and future plans for the Bonobo framework, including open-source goals and enhancements for developer experience.



































































