Download to read offline














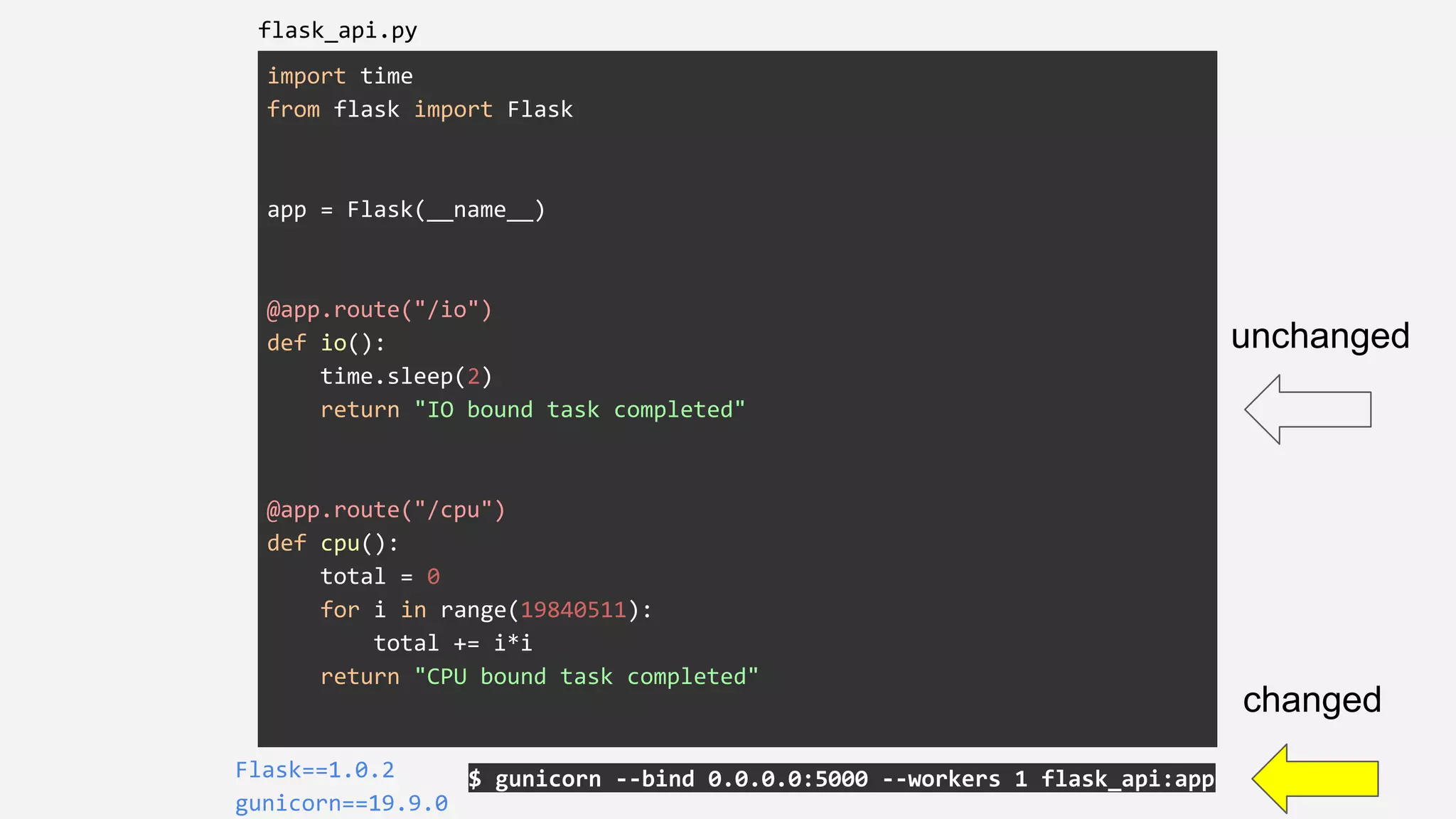


![grpc_server.py
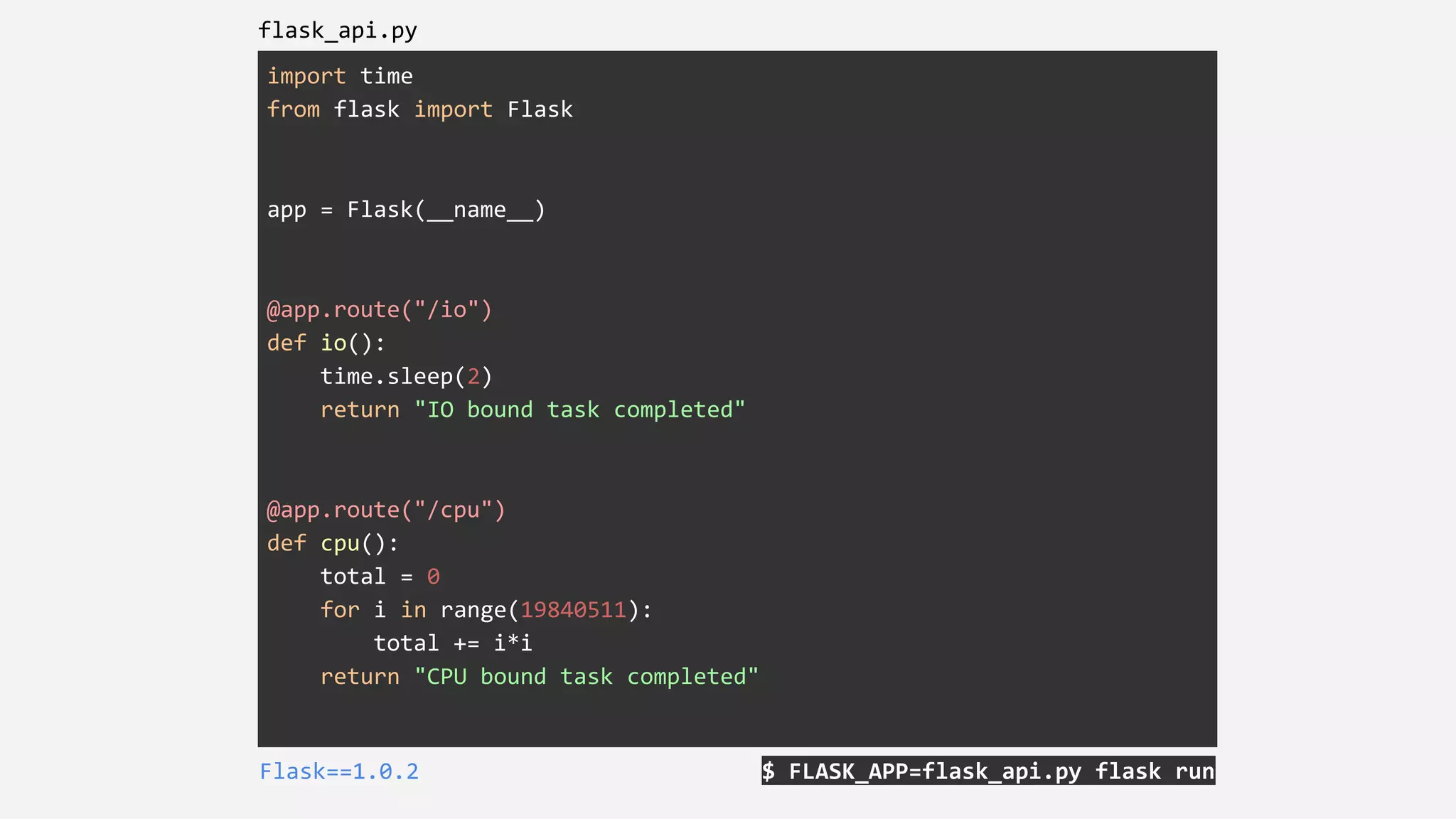
$ python grpc_server.py
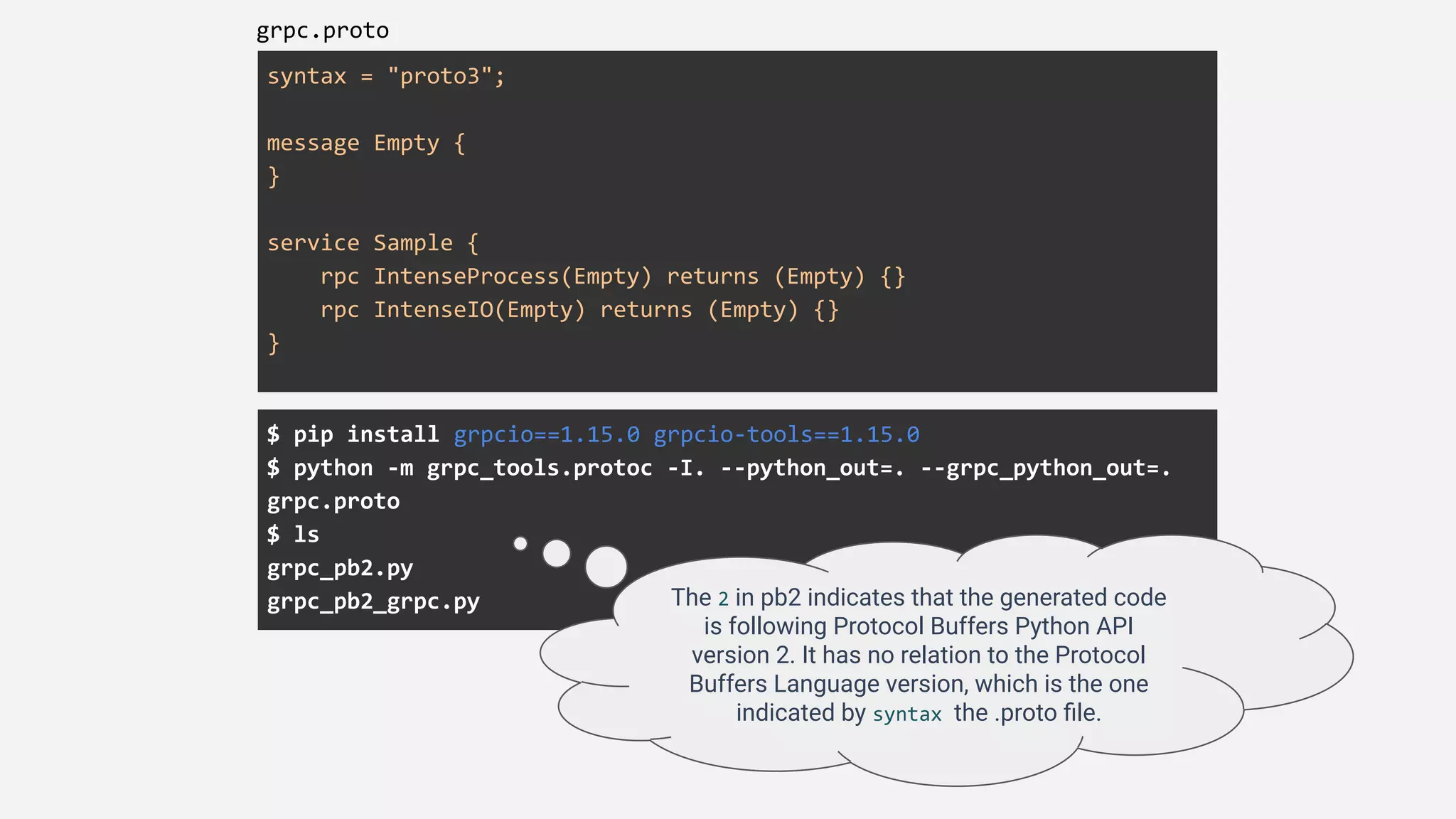
grpcio==1.15.0
grpcio-tools==1.15.0
import time
from concurrent import futures
import grpc
import grpc_pb2
import grpc_pb2_grpc
class SampleServicer(grpc_pb2_grpc.SampleServicer):
def IntenseProcess(self, request, context):
total = 0
for i in range(19840511):
total += i*i
return grpc_pb2.Empty()
def IntenseIO(self, request, context):
time.sleep(2)
return grpc_pb2.Empty()
server = grpc.server(futures.ThreadPoolExecutor(max_workers=10))
grpc_pb2_grpc.add_SampleServicer_to_server(SampleServicer(), server)
print('Starting server. Listening on port 5001.')
server.add_insecure_port('[::]:50051')
server.start()
try:
while True:
time.sleep(86400)
except KeyboardInterrupt:
server.stop(0)](https://image.slidesharecdn.com/pyconuk2018journeytogrpc-190508101836/75/PyConUK-2018-Journey-from-HTTP-to-gRPC-40-2048.jpg)



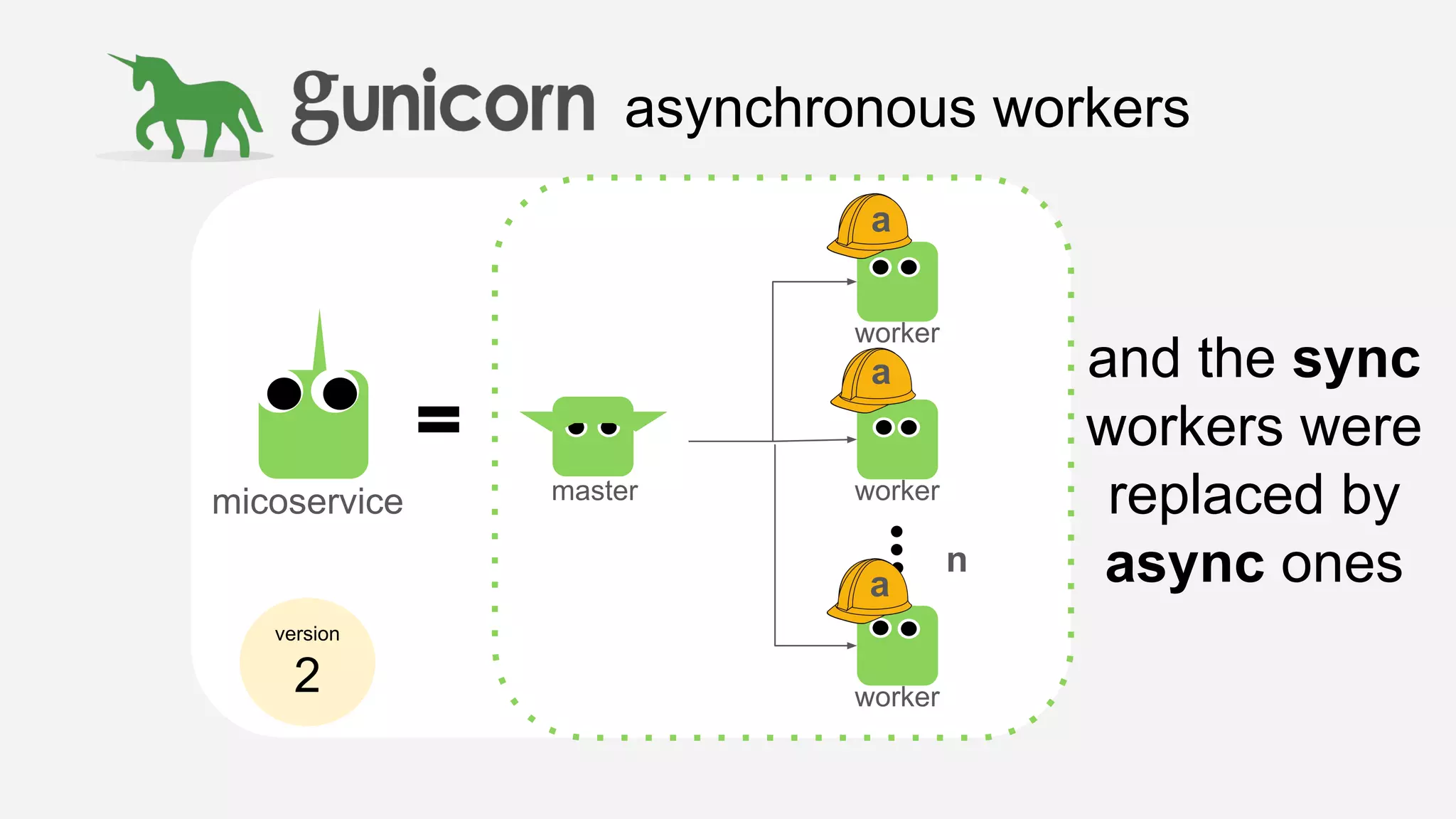
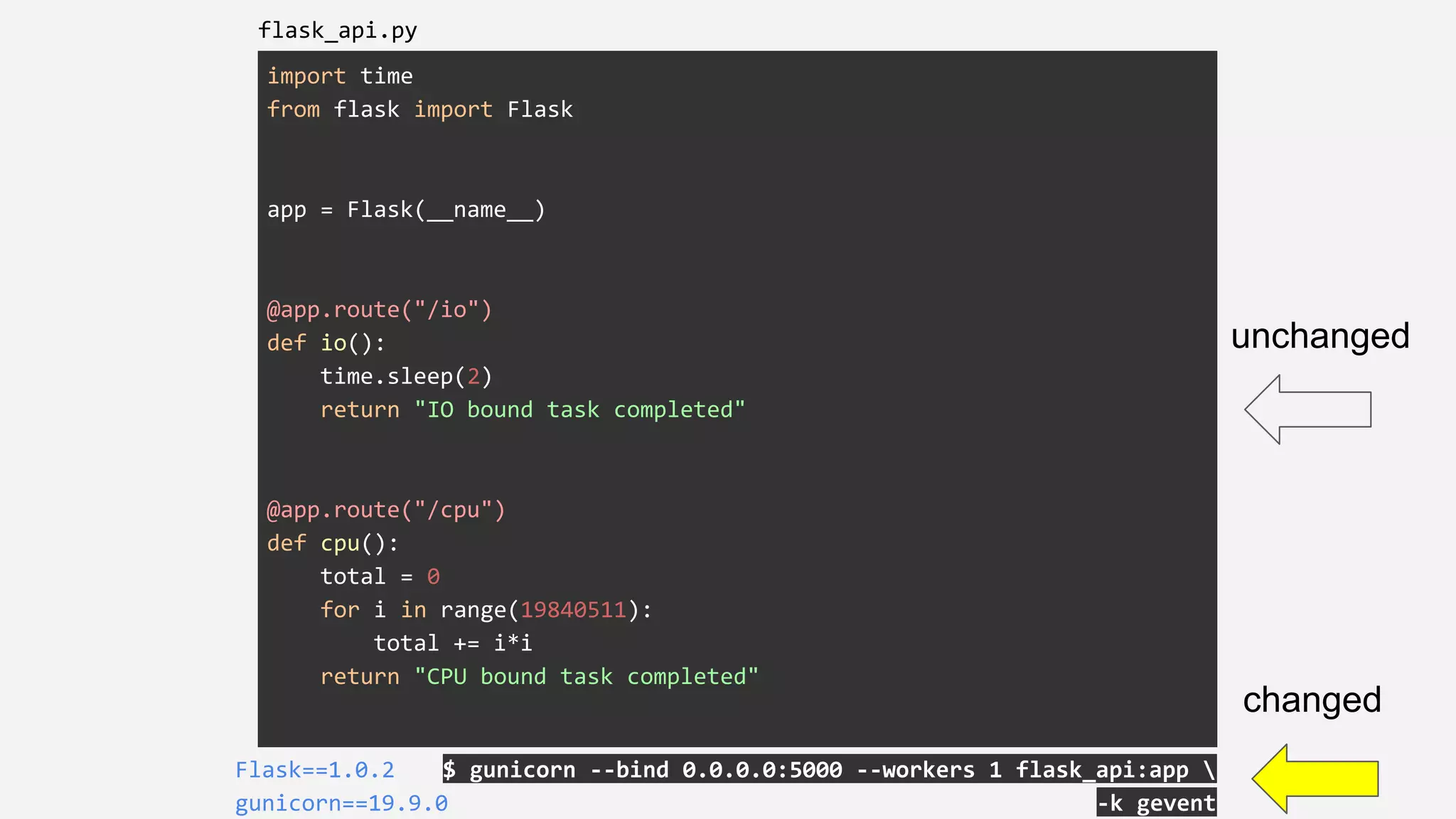
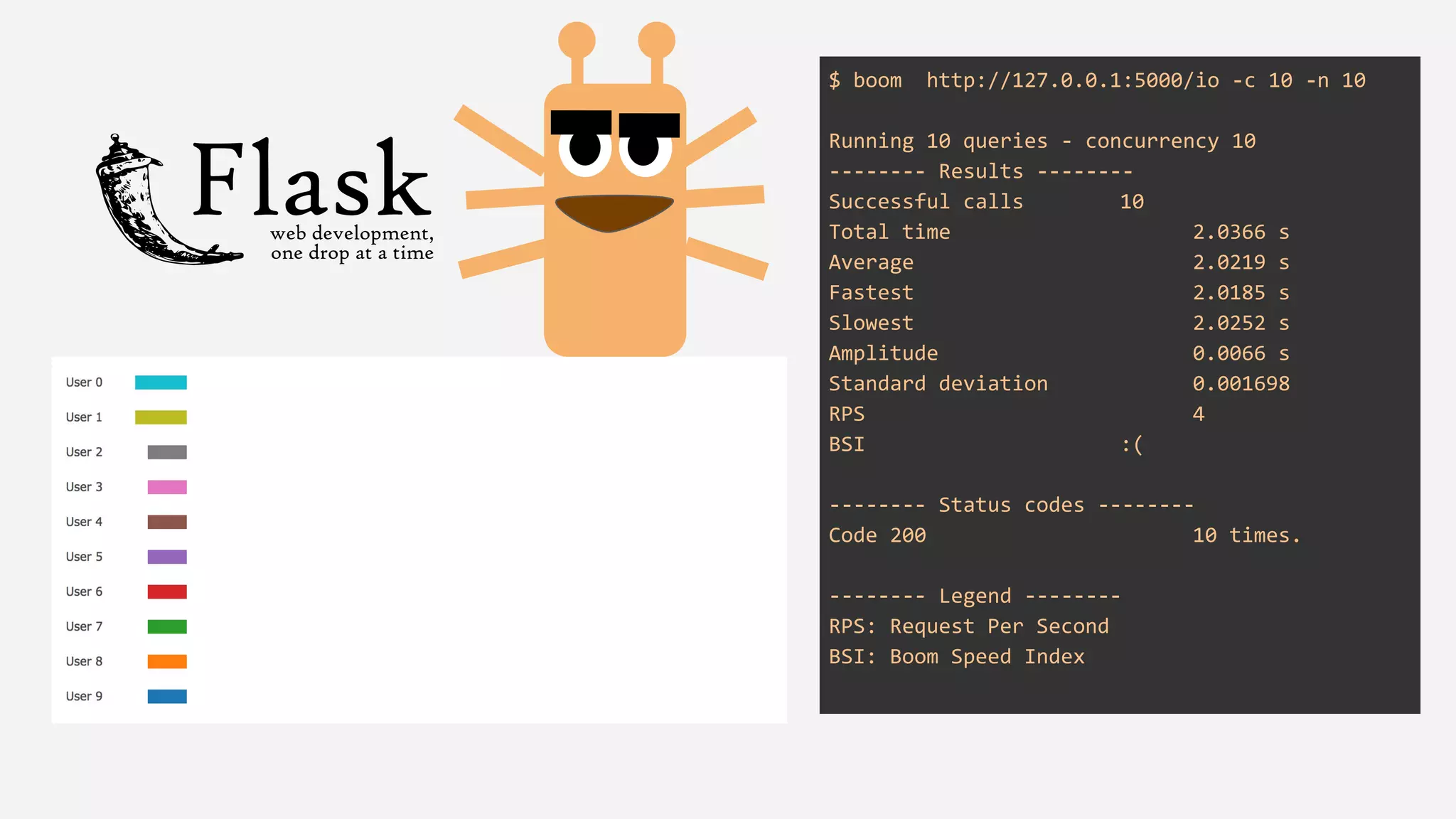



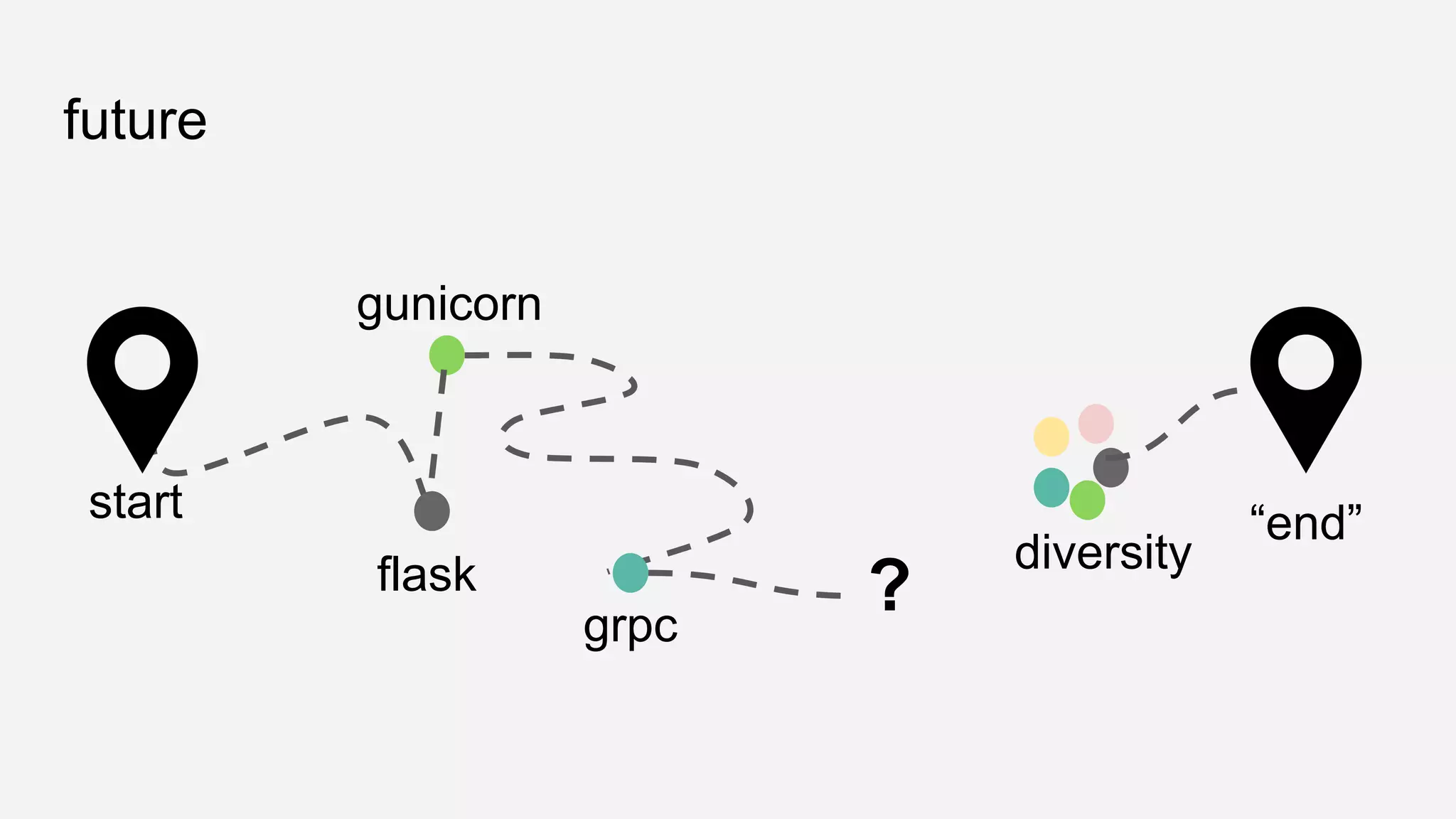






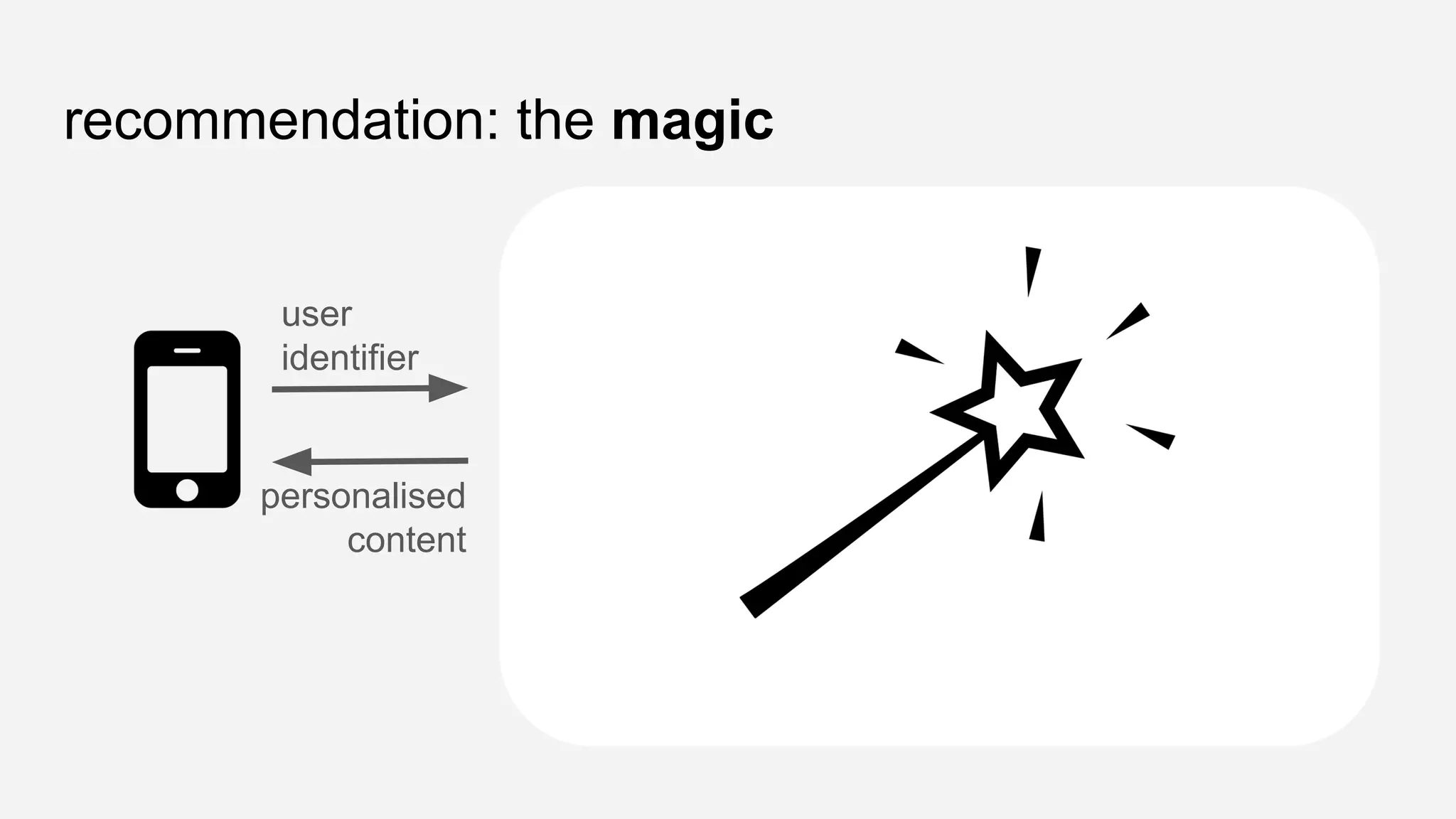
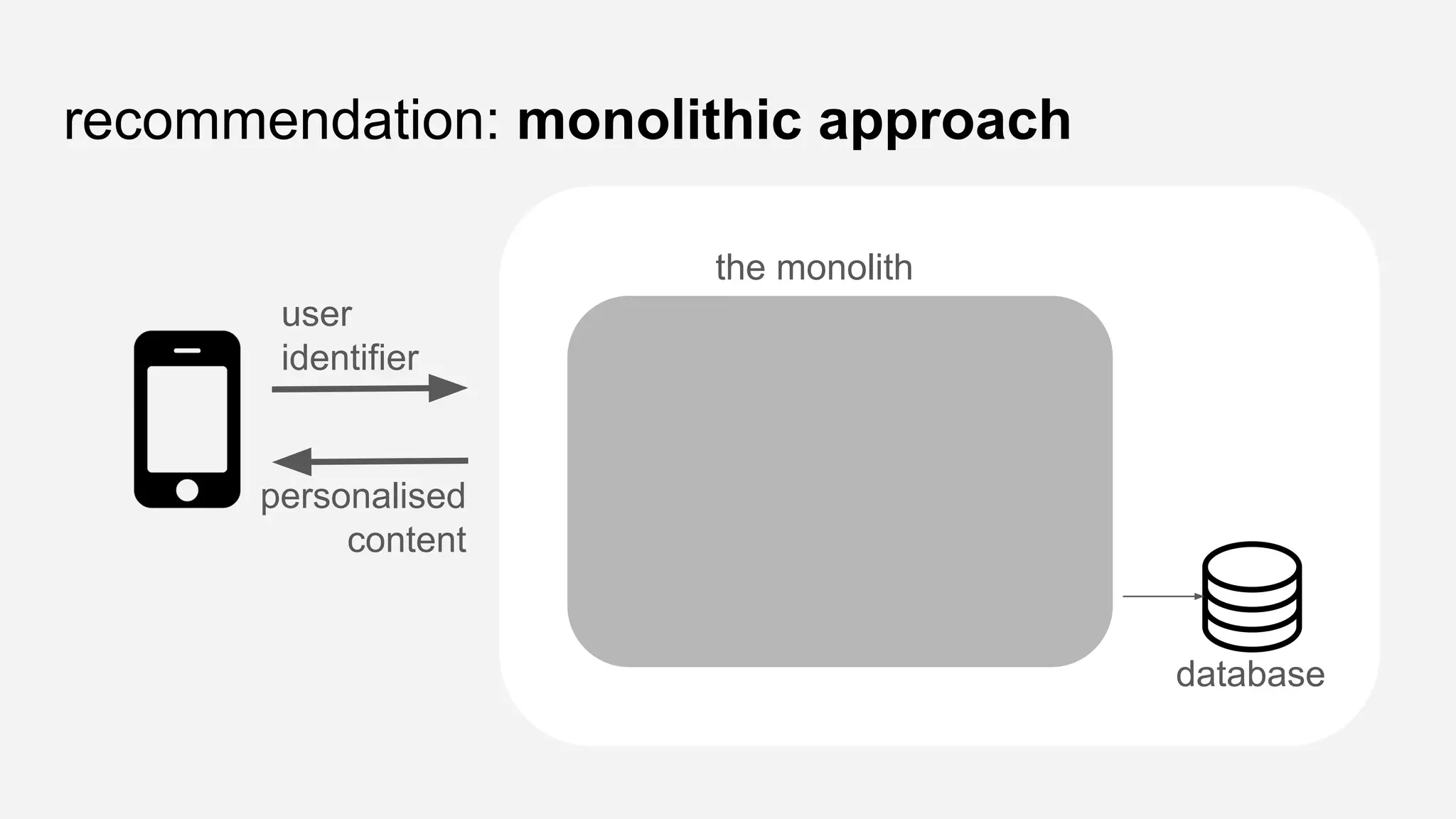
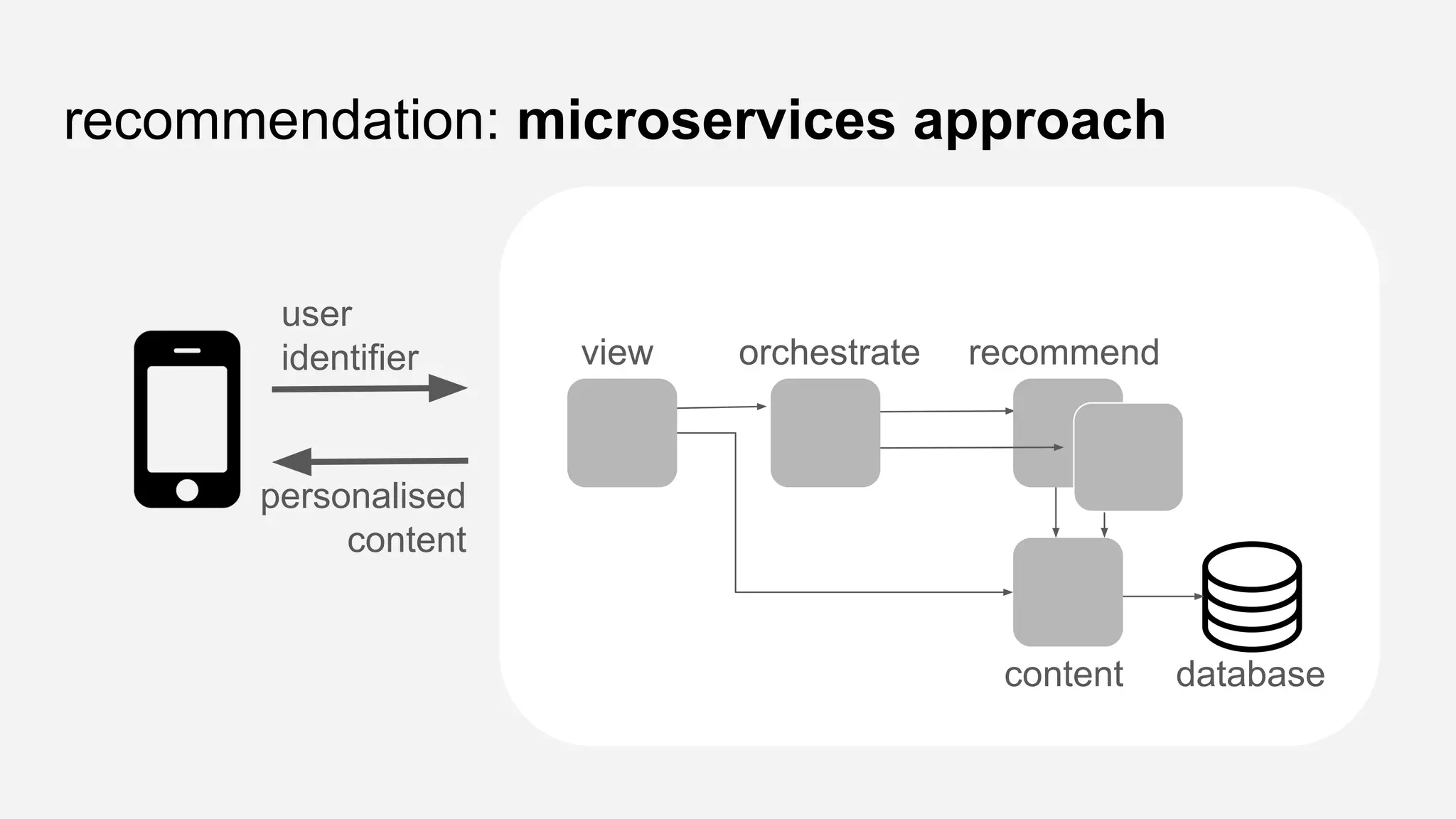
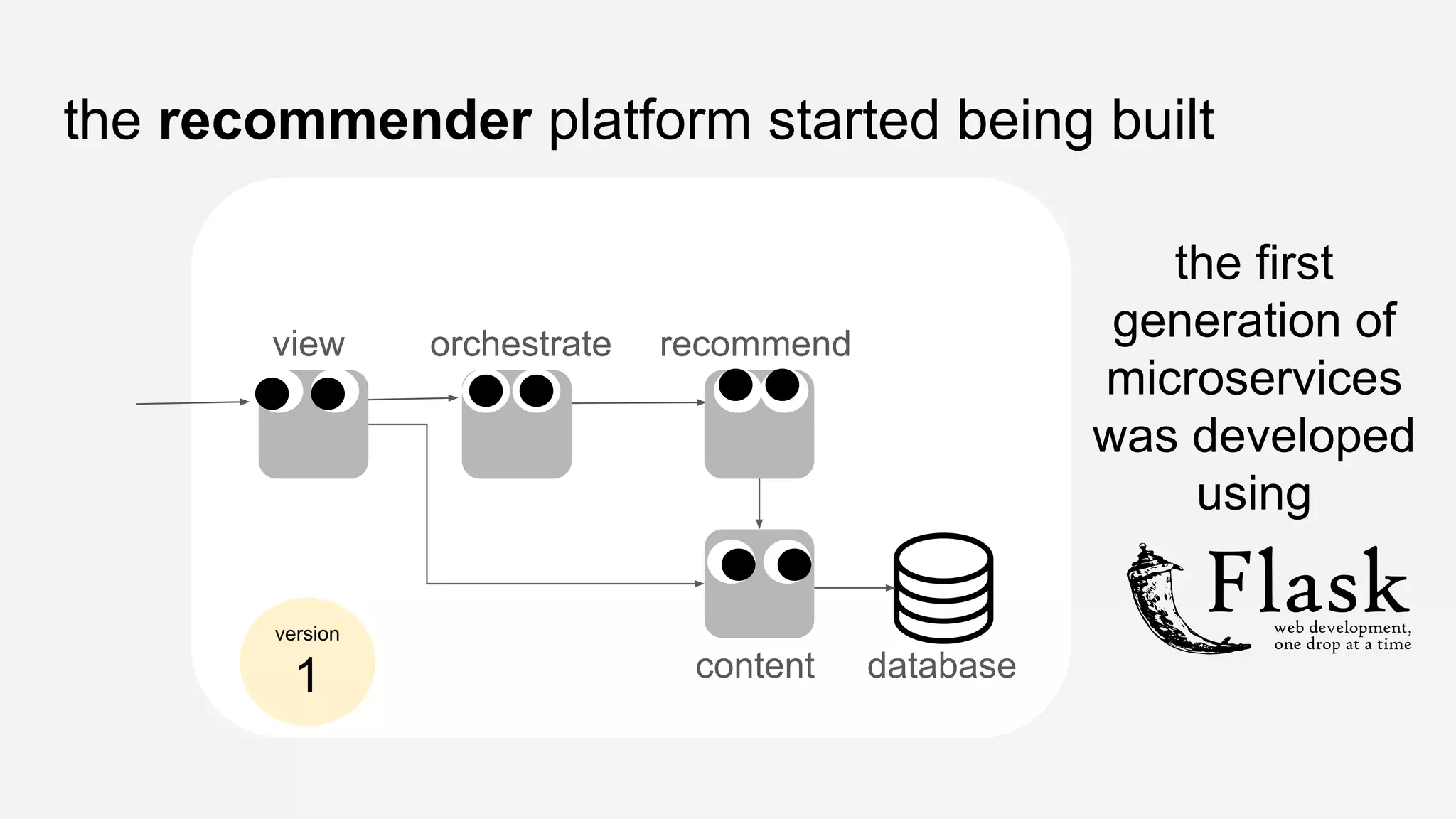
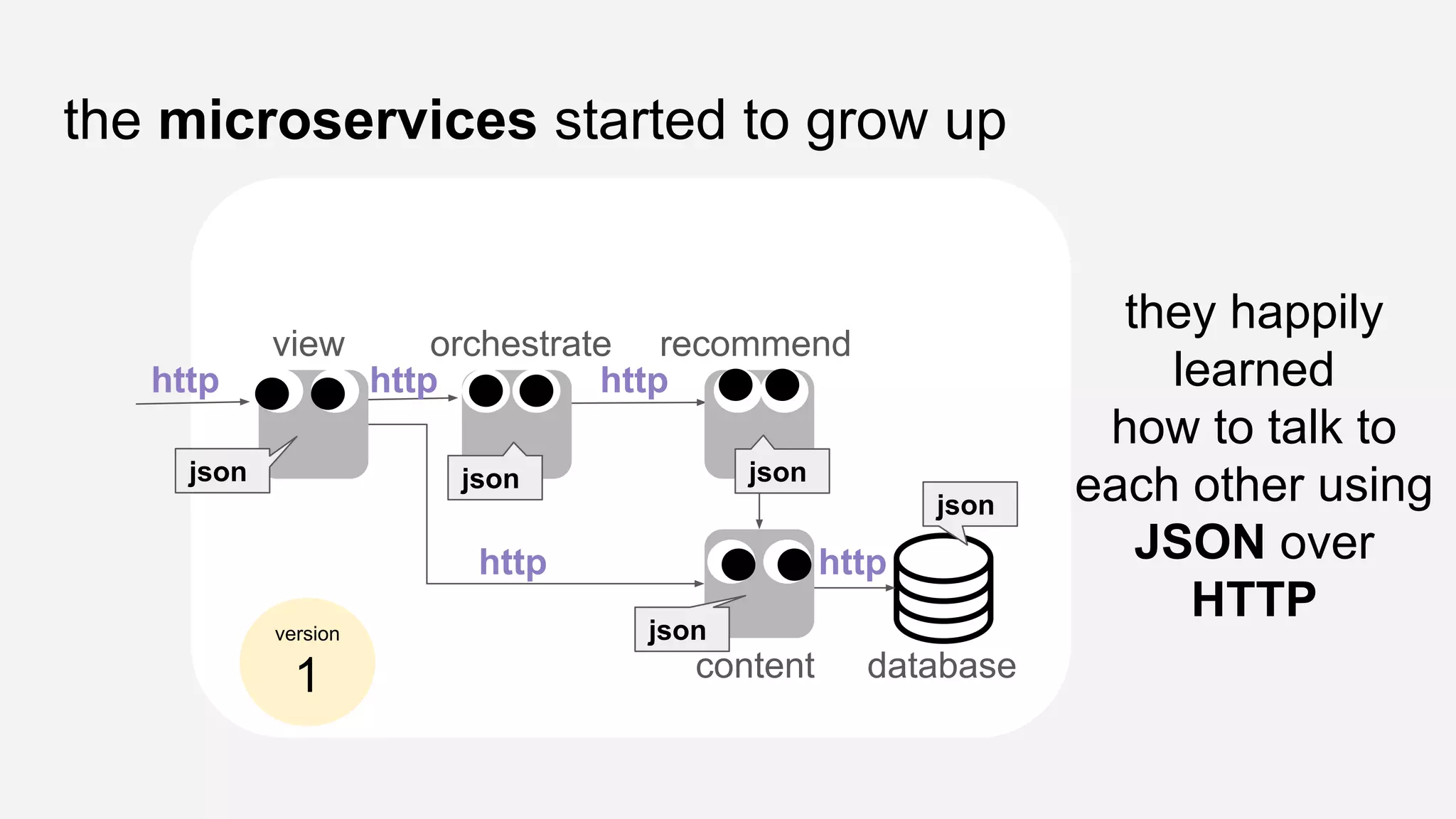
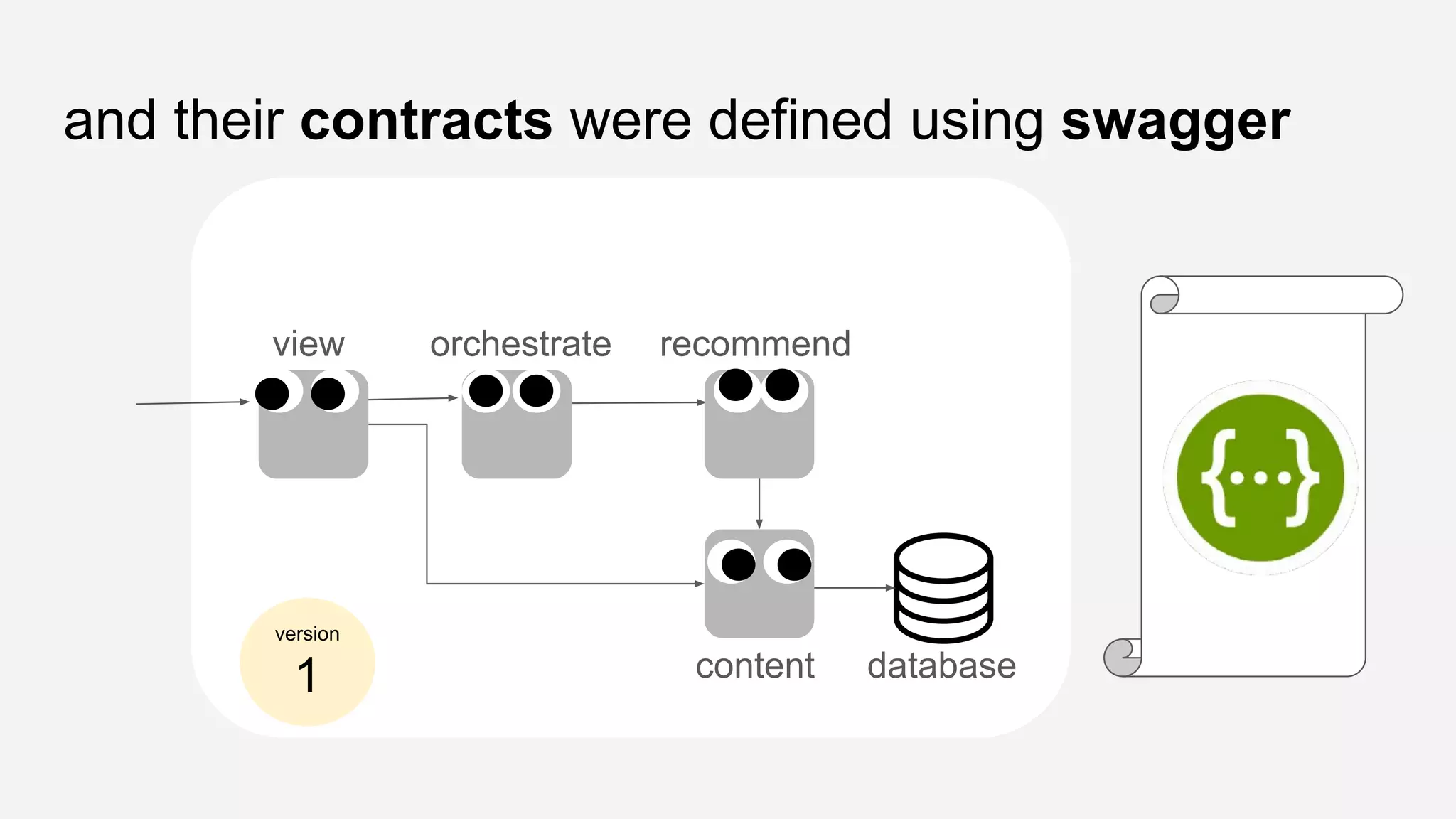
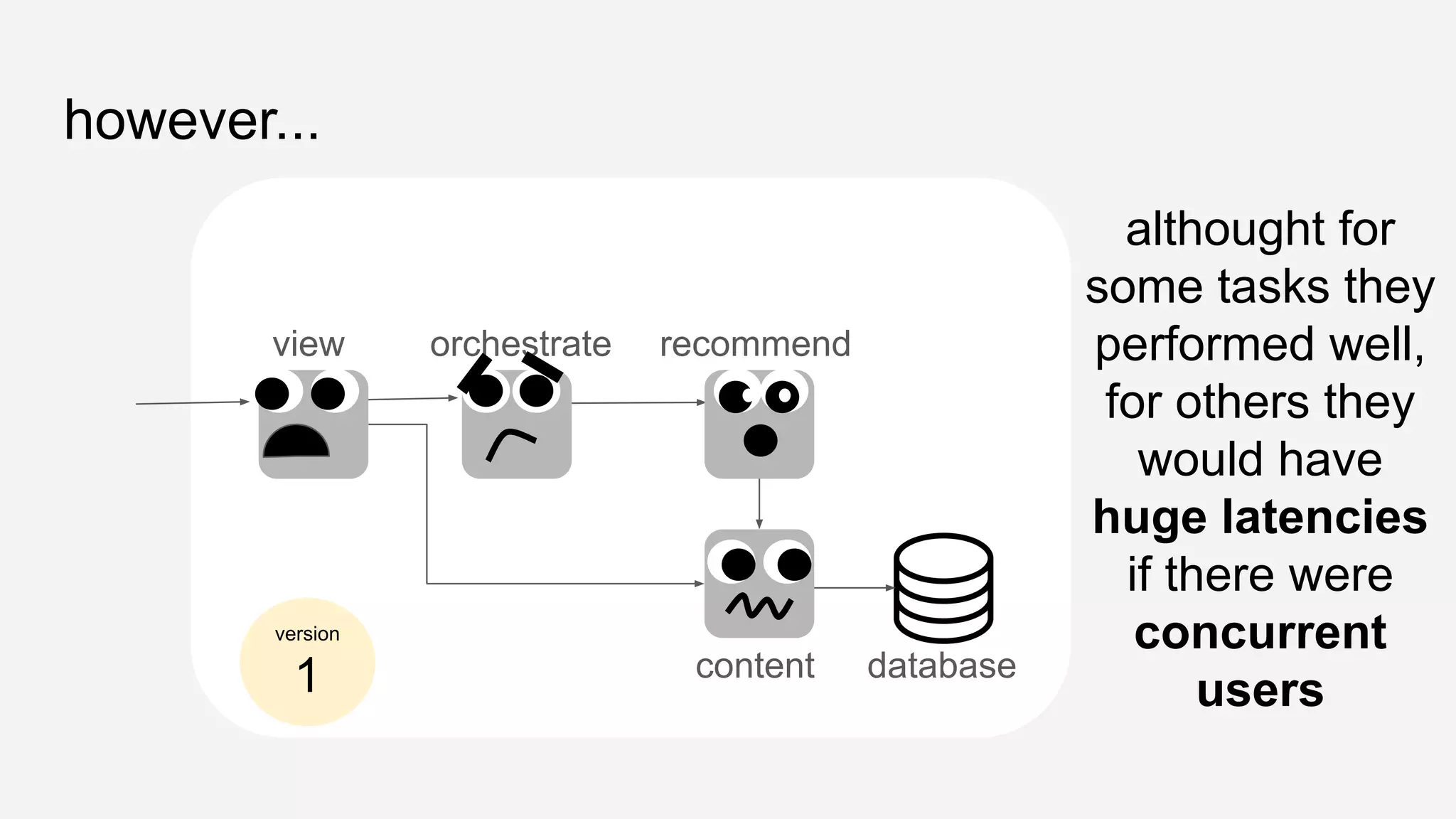
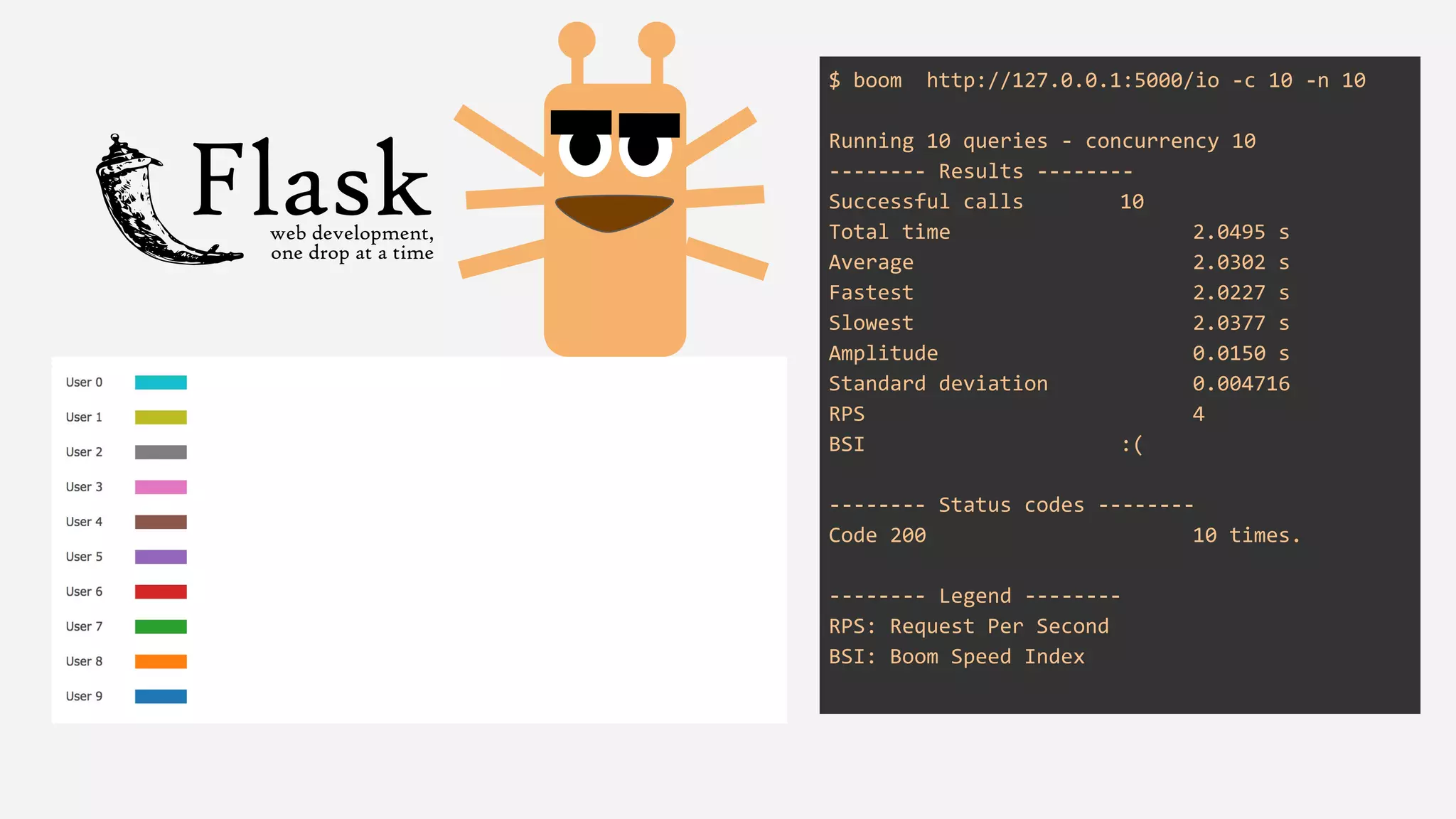
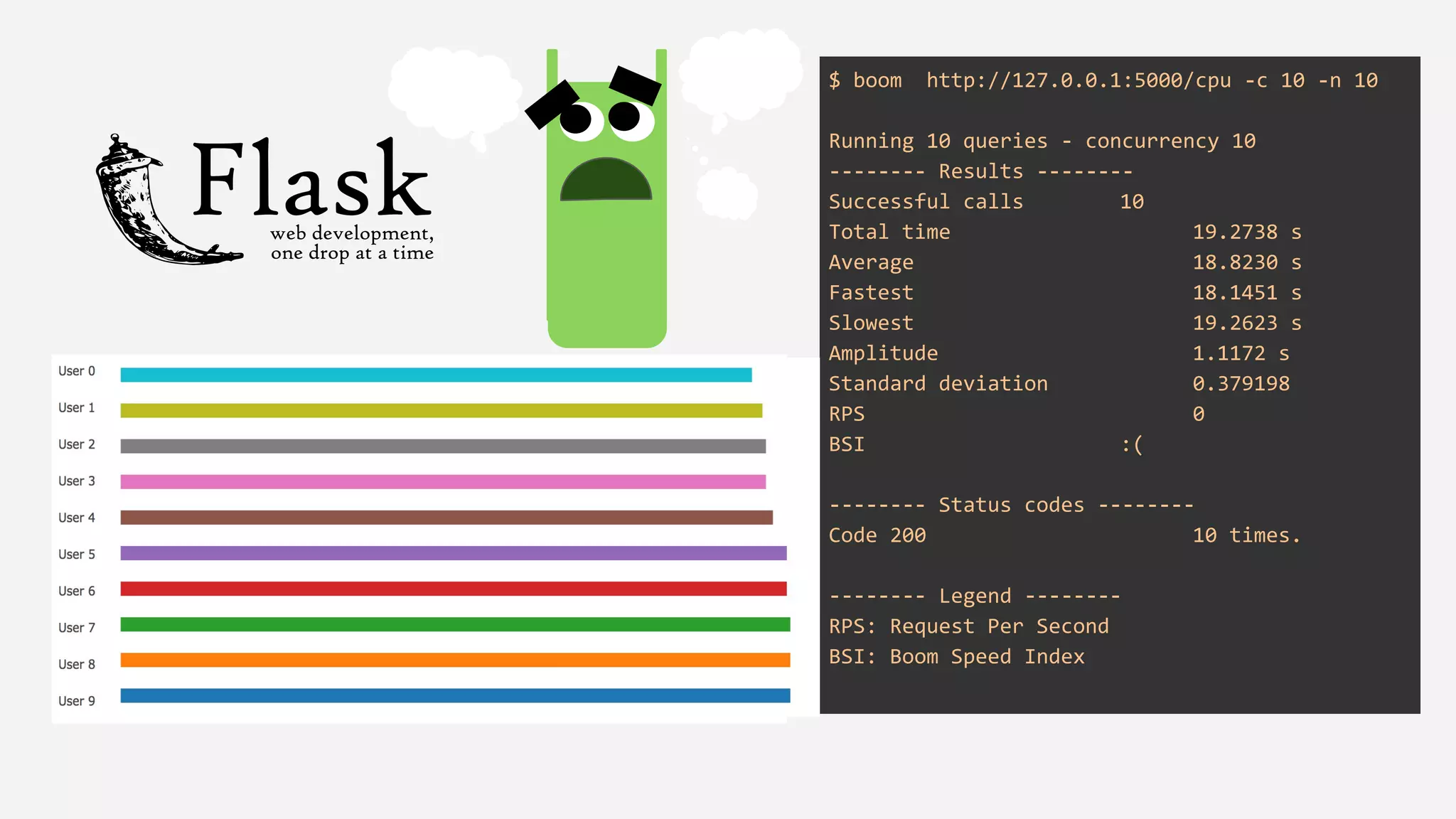
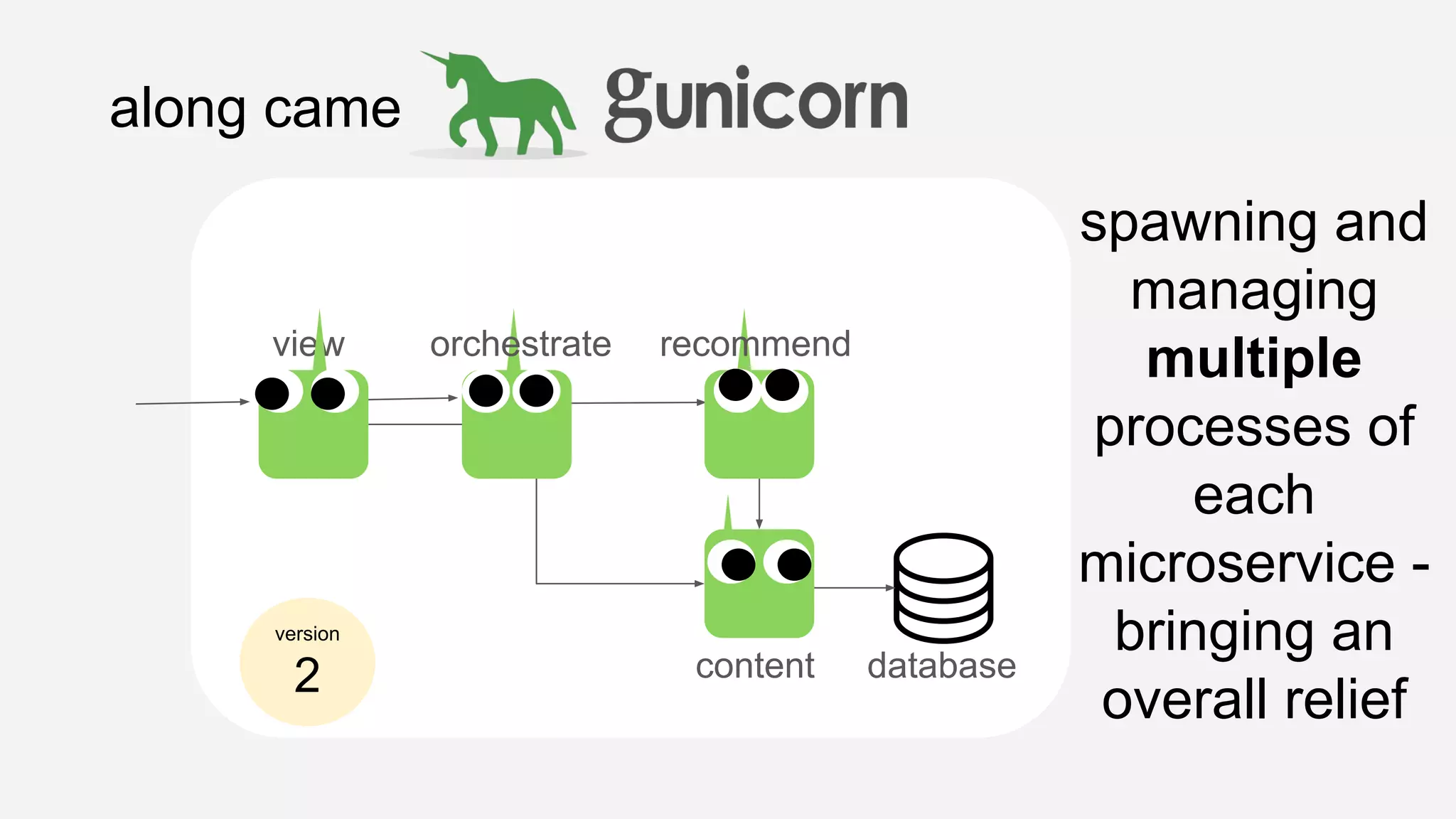
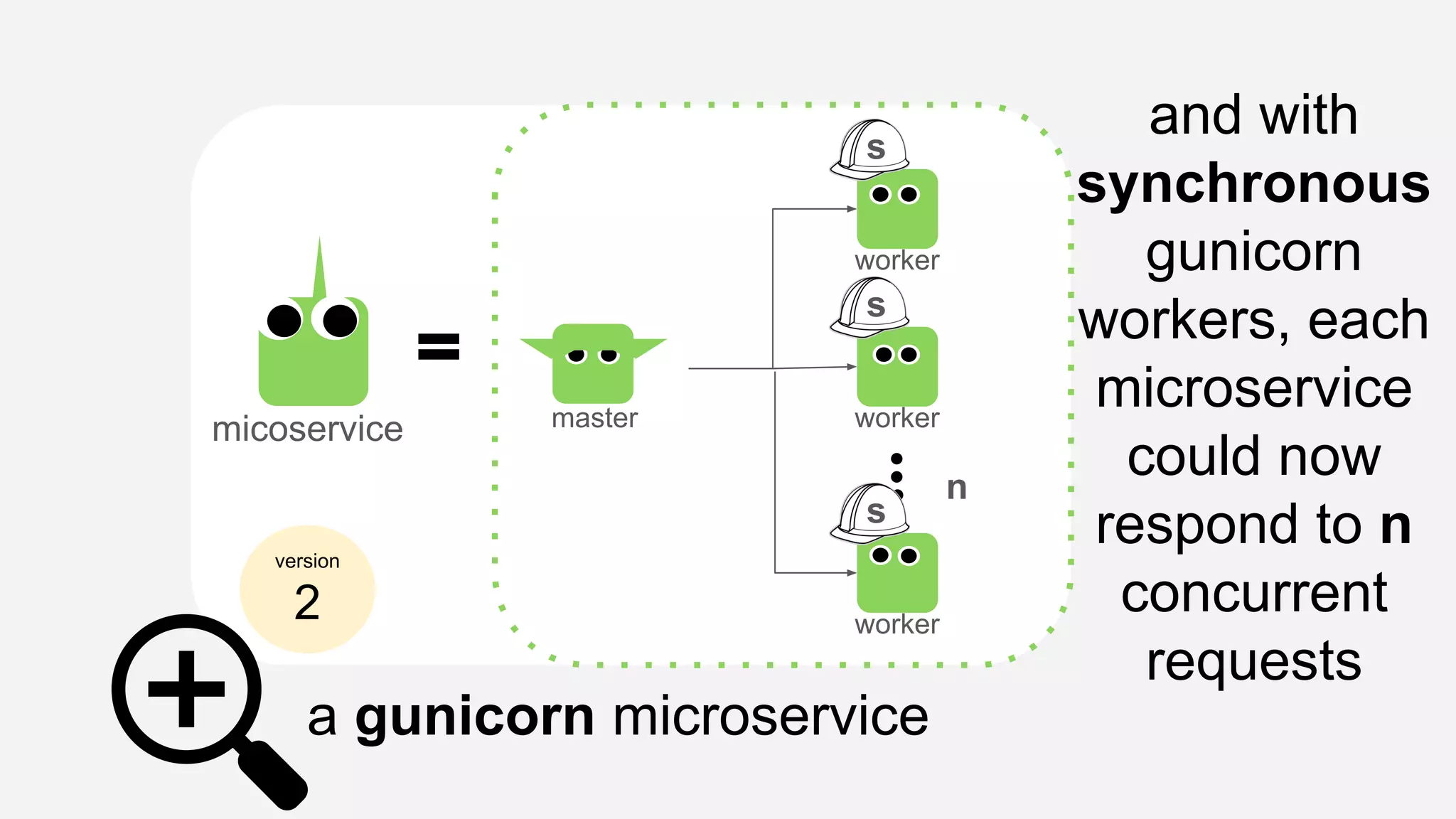
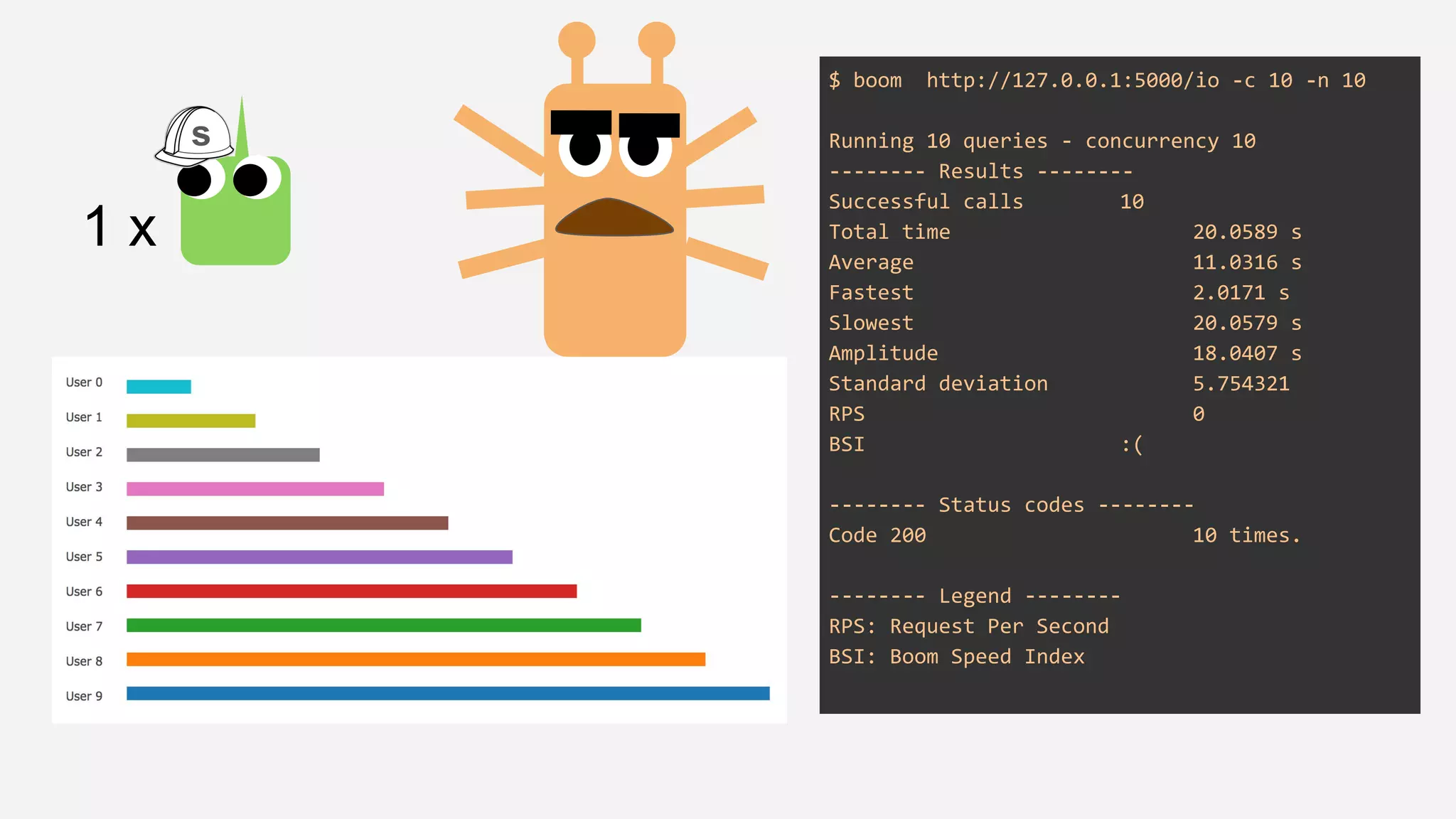
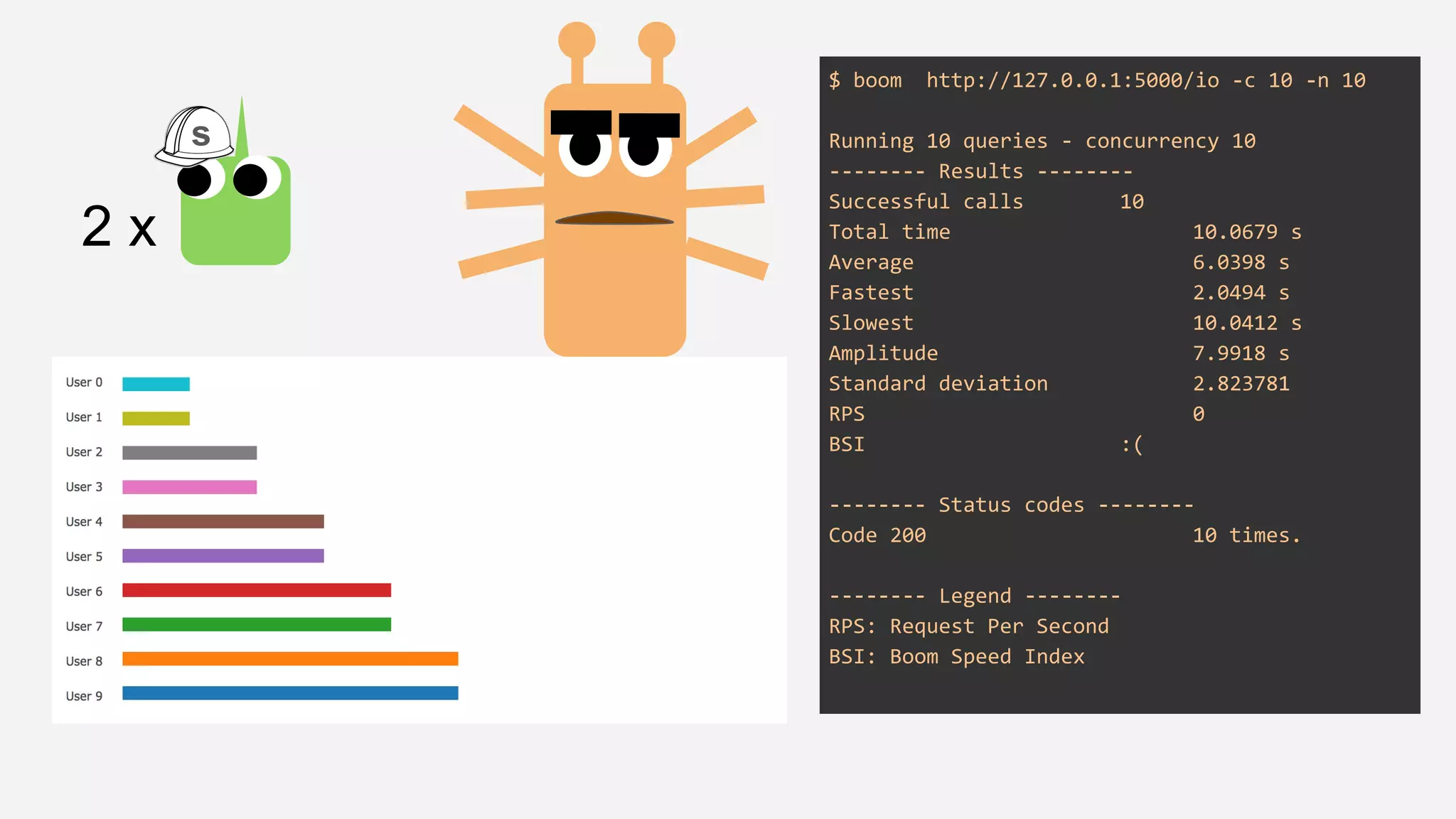
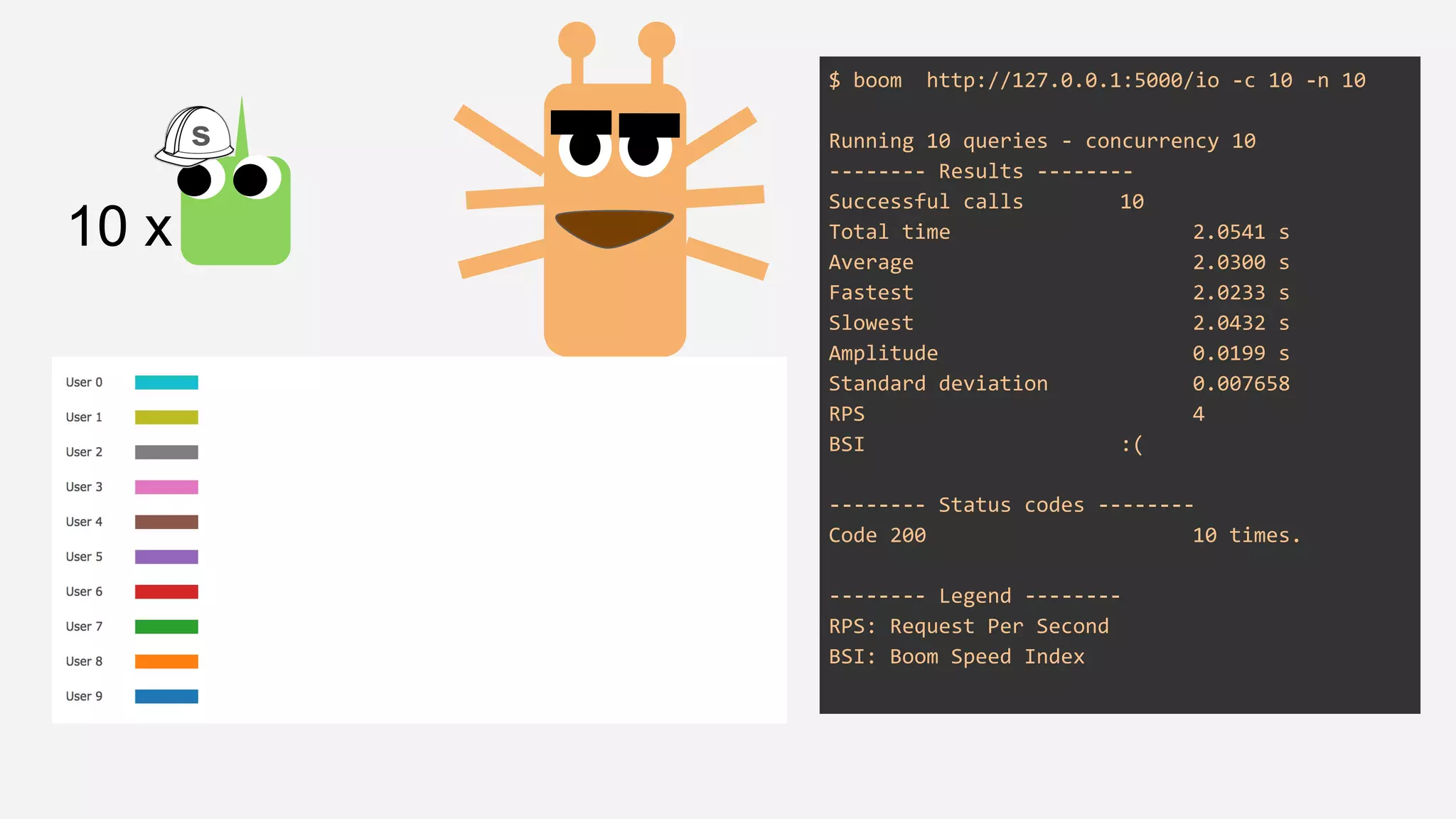
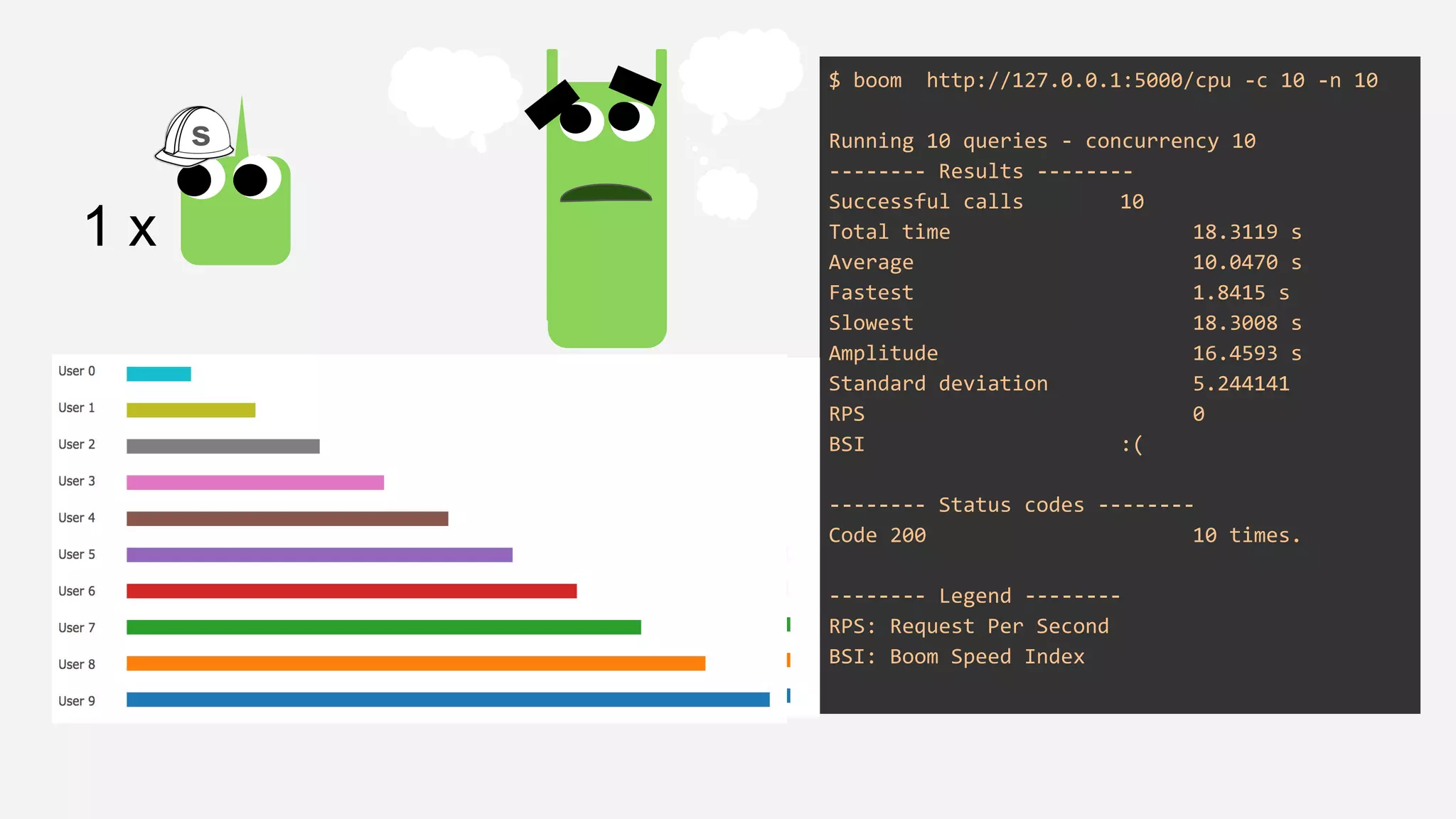
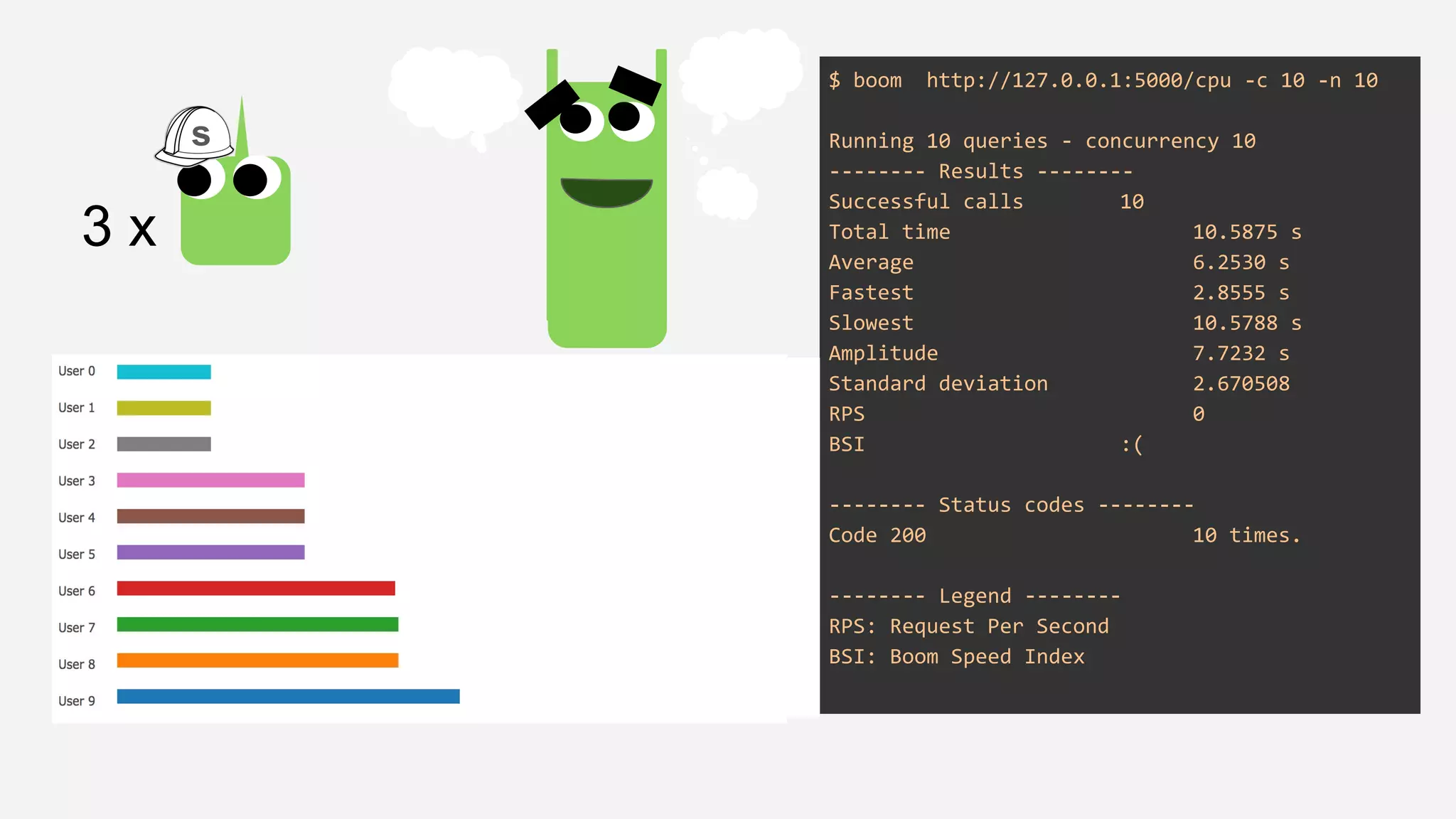
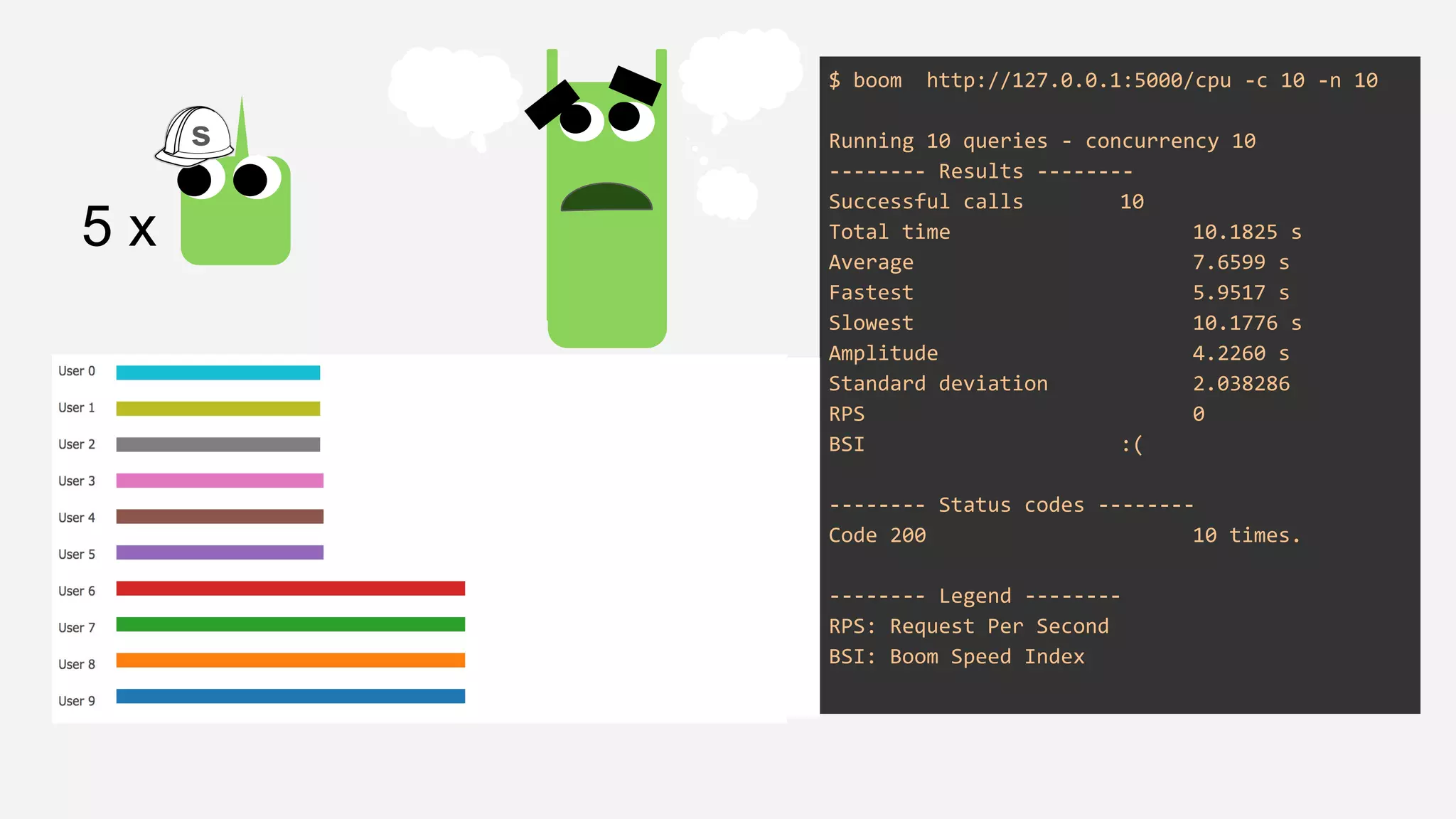
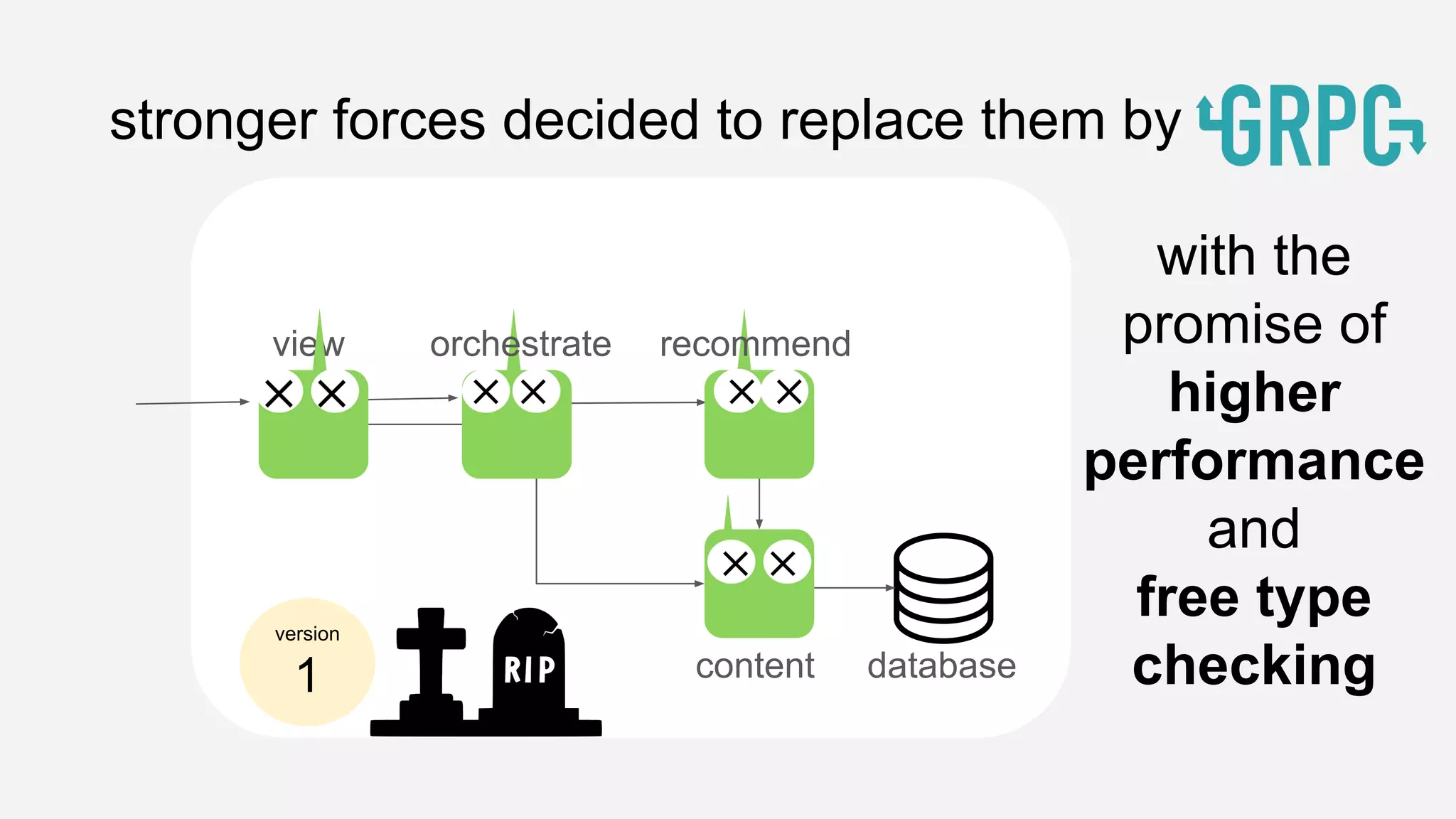
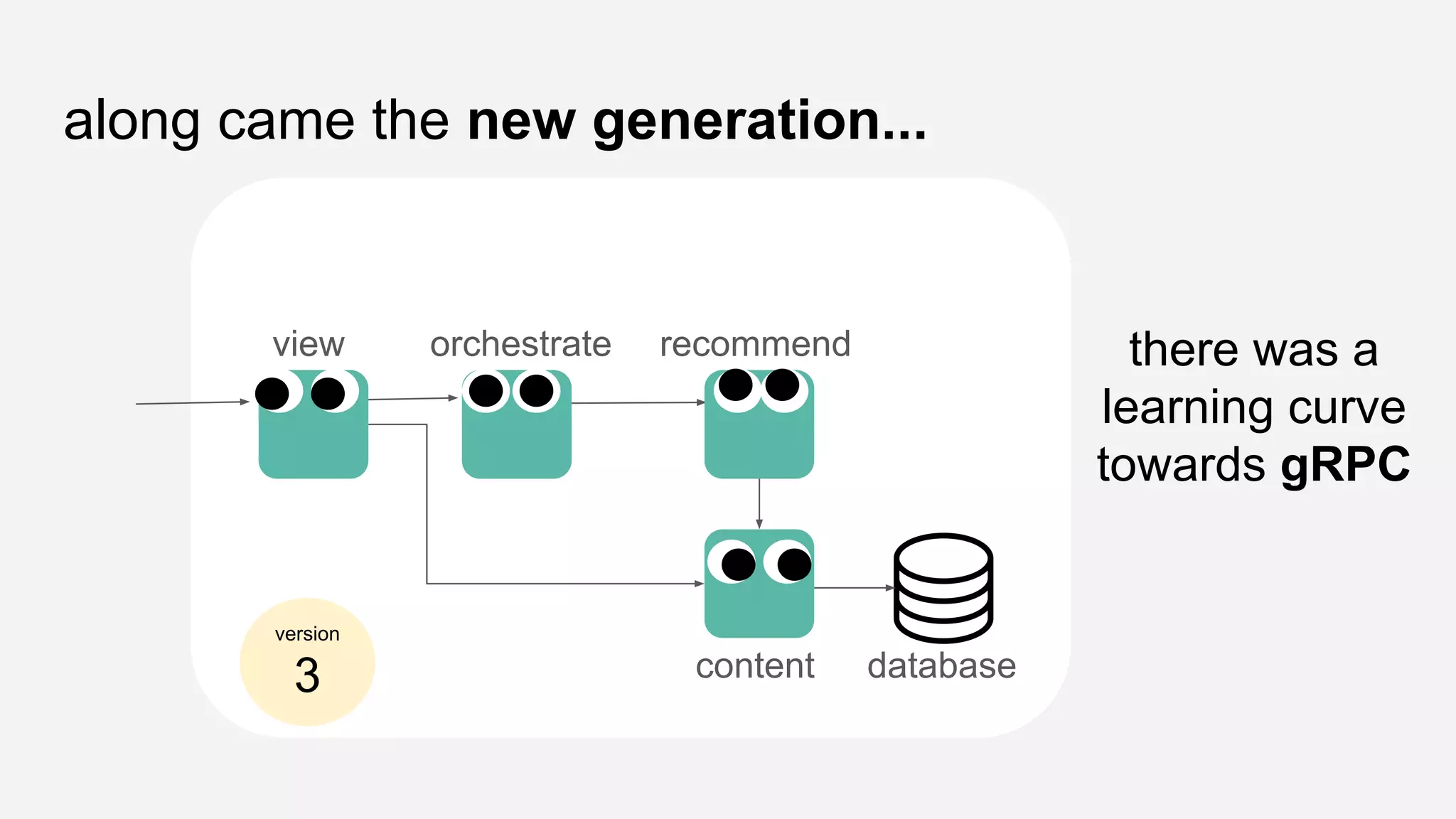
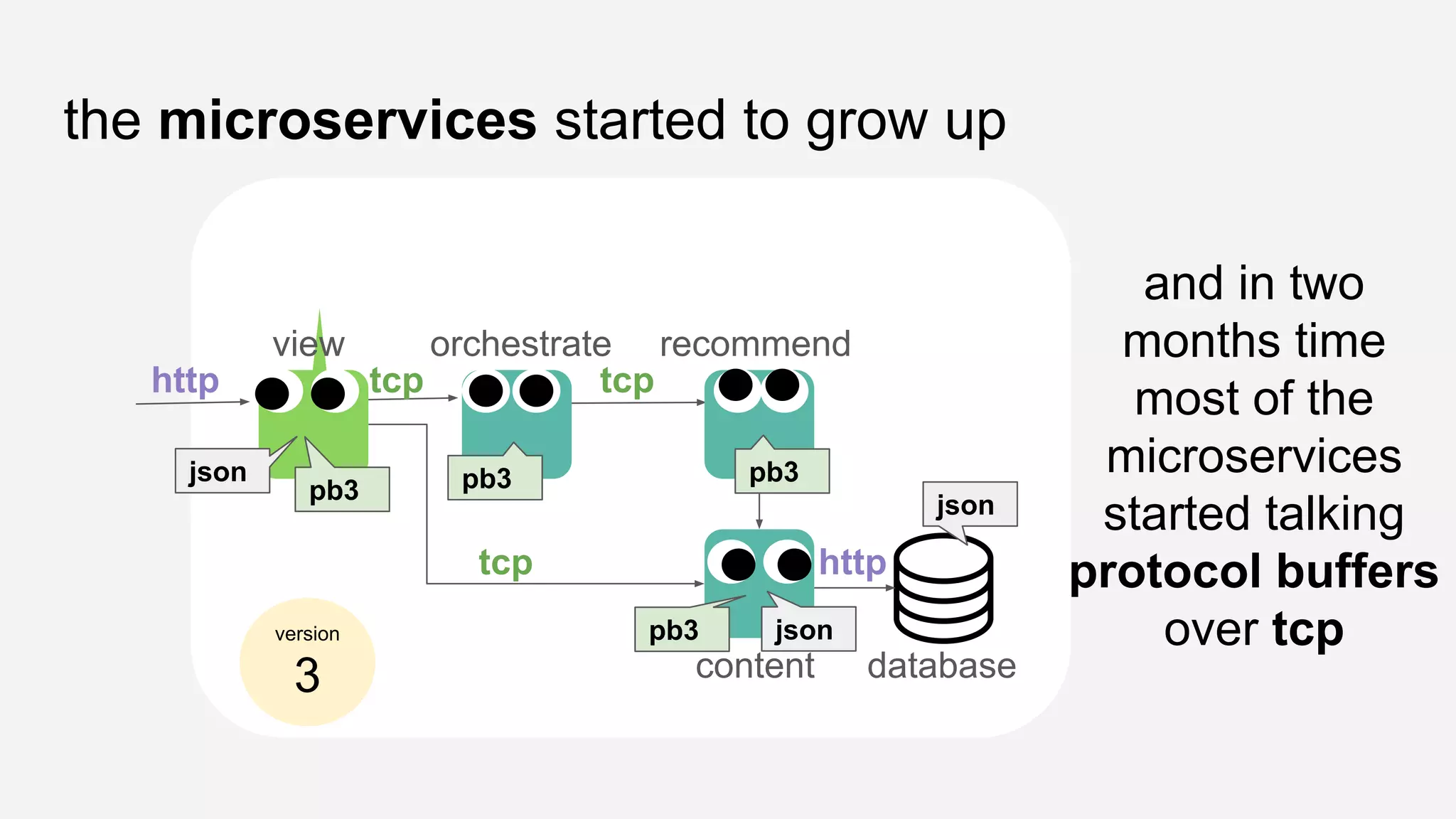
The presentation details the evolution of a recommender system at BBC from an HTTP-based monolithic architecture to a more efficient microservices architecture using gRPC and protocol buffers. It outlines the challenges faced with CPU and I/O-bound tasks in earlier versions, the benefits of introducing gunicorn and asynchronous workers to improve performance, and a transition to gRPC for better scalability and type safety. The speaker emphasizes the importance of adapting technologies to enhance system capabilities while maintaining performance.



![PythonBrasil[8] - CPython for dummies](https://cdn.slidesharecdn.com/ss_thumbnails/cpythonfordummies-170610060108-thumbnail.jpg?width=640&height=640&fit=bounds)































































![PythonBrasil[8] closing](https://cdn.slidesharecdn.com/ss_thumbnails/pythonbrasil8closing-130219054907-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



















