Download as PDF, PPTX














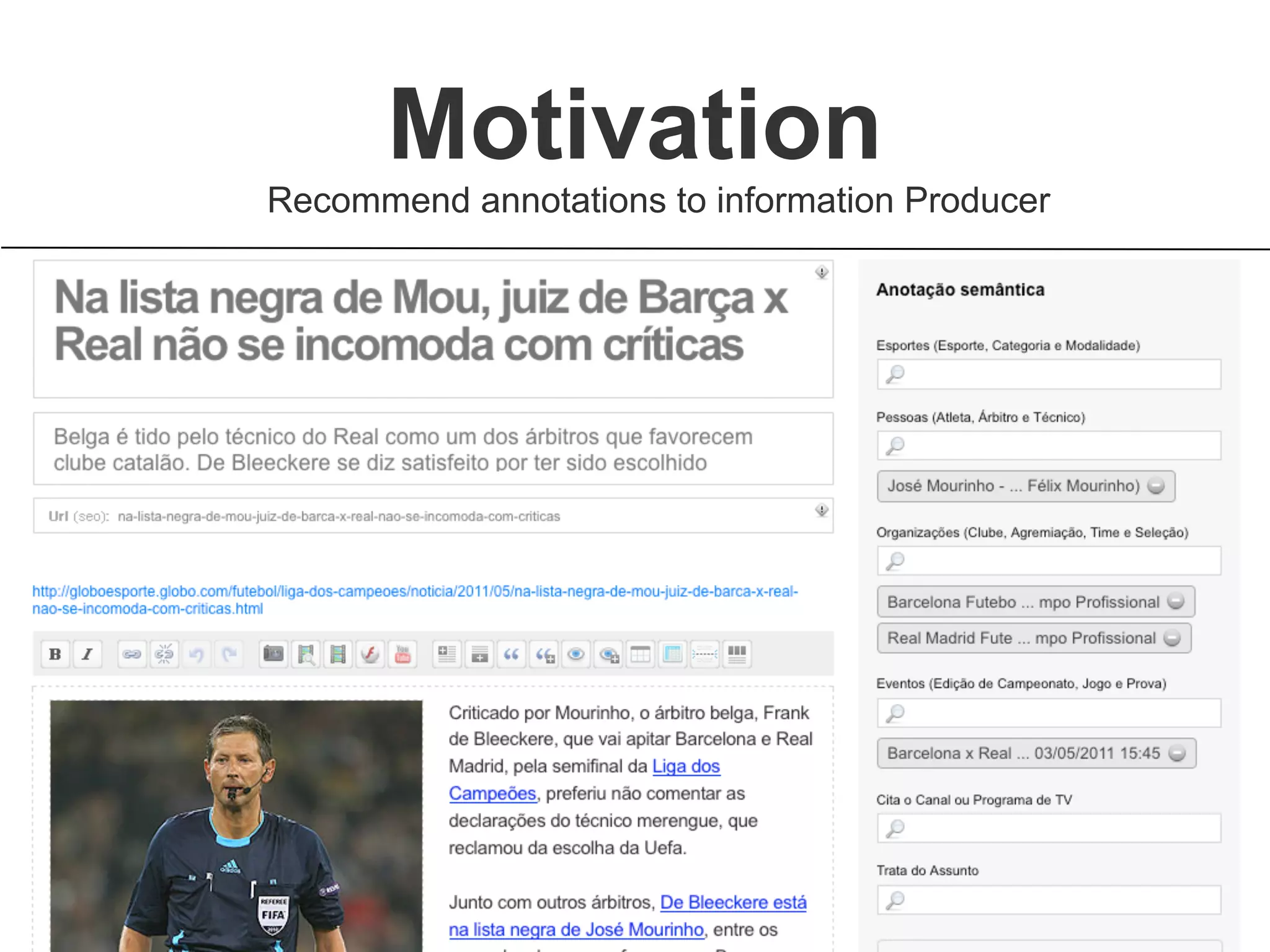
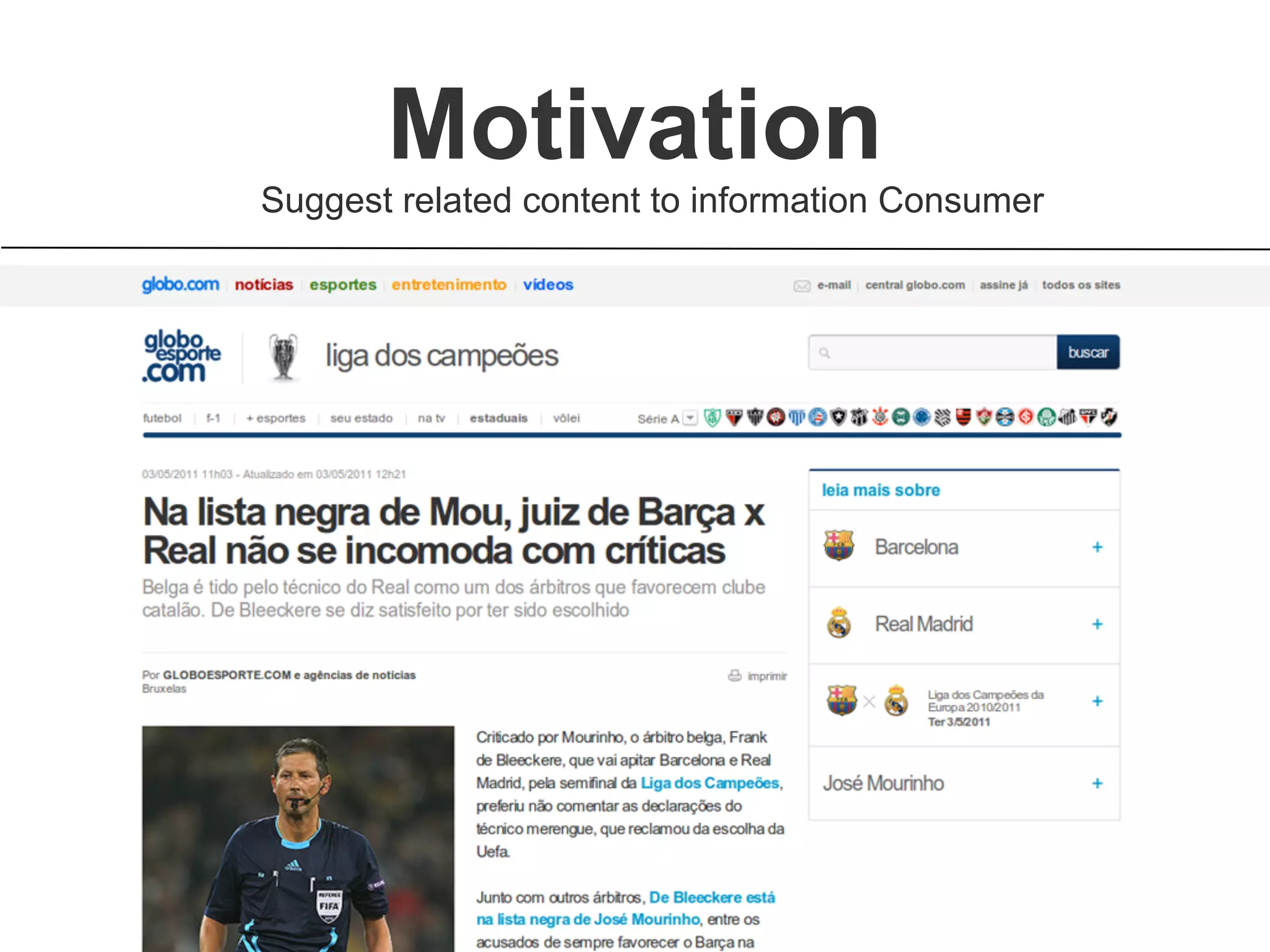
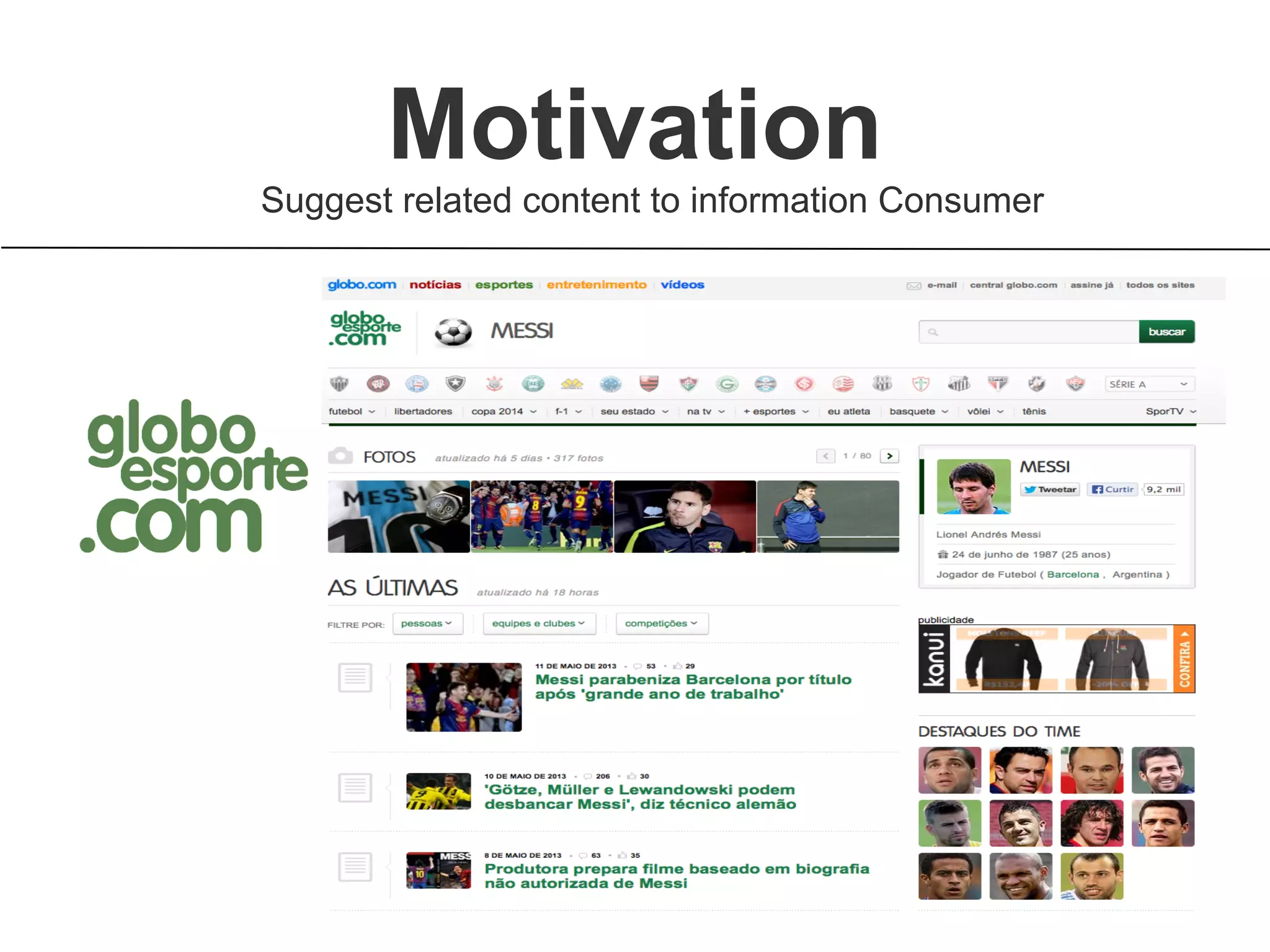
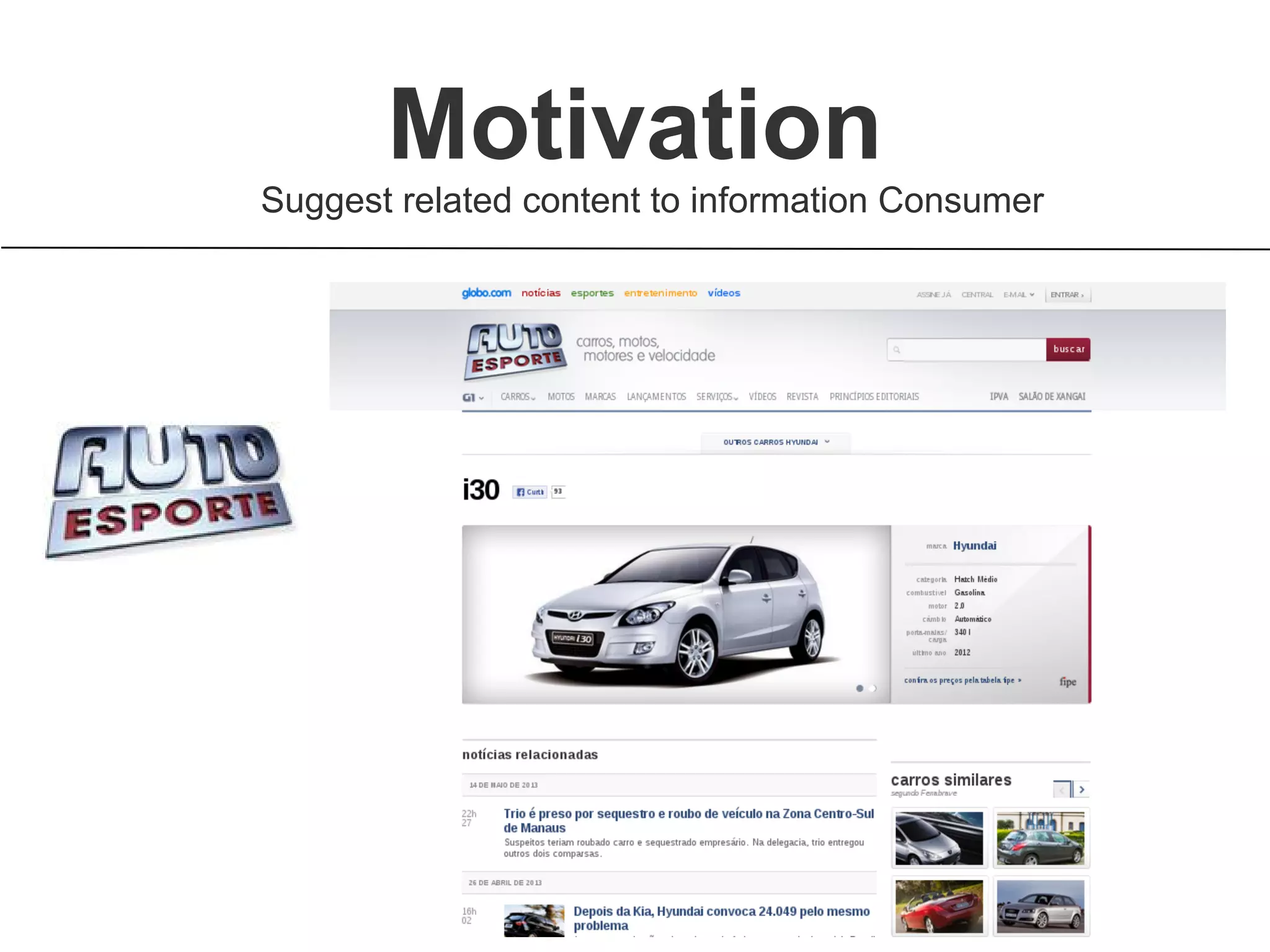






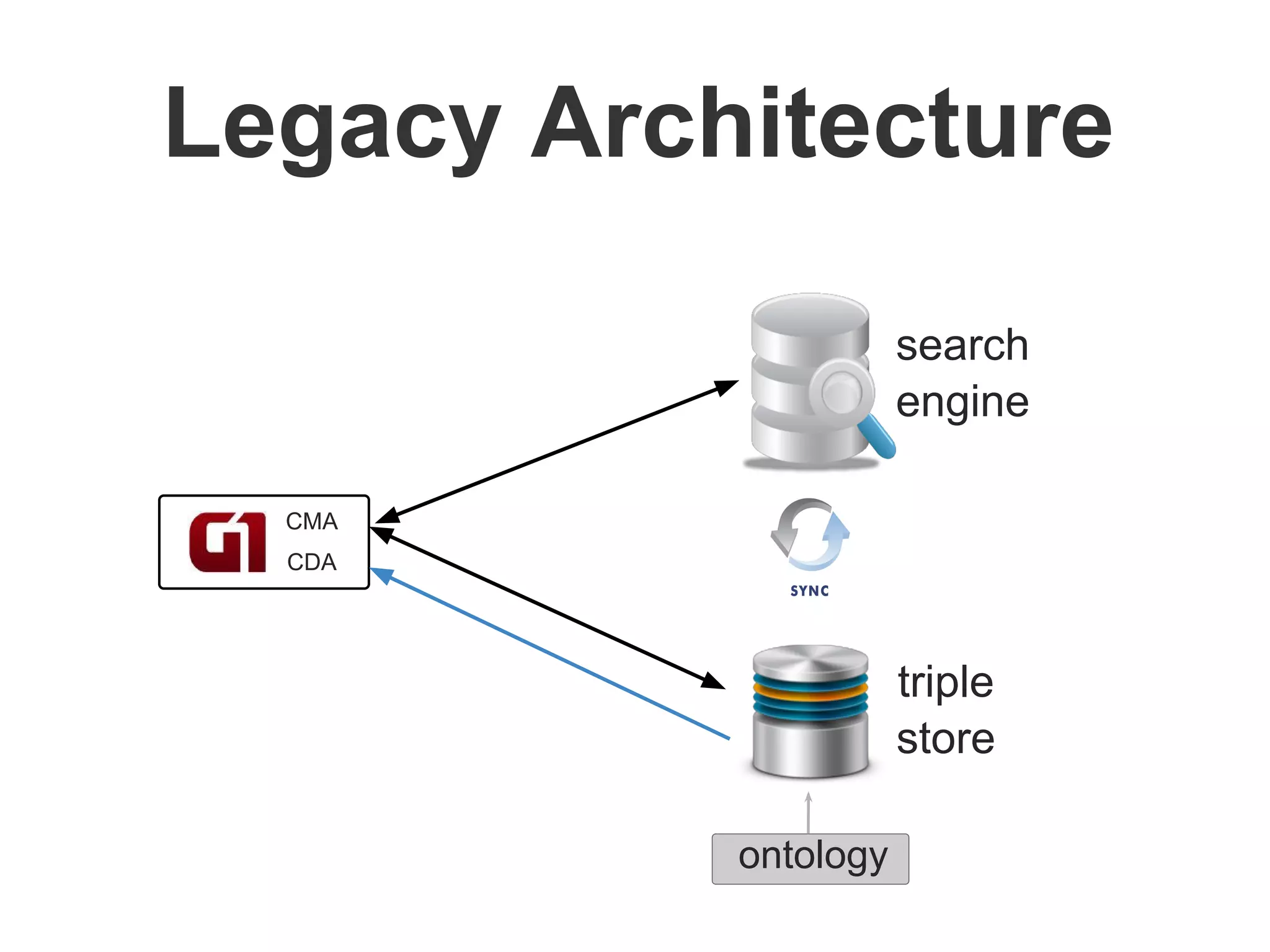
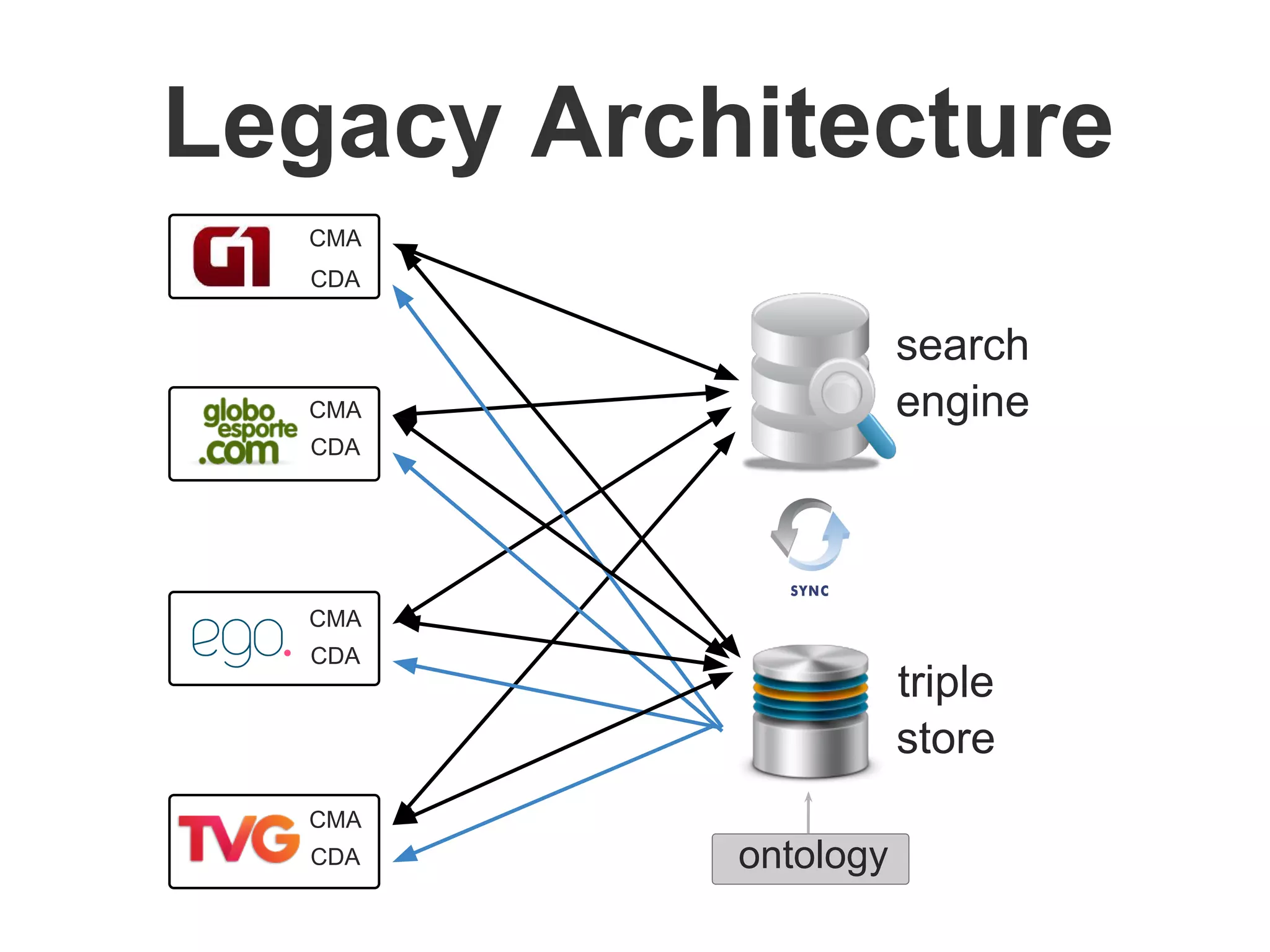

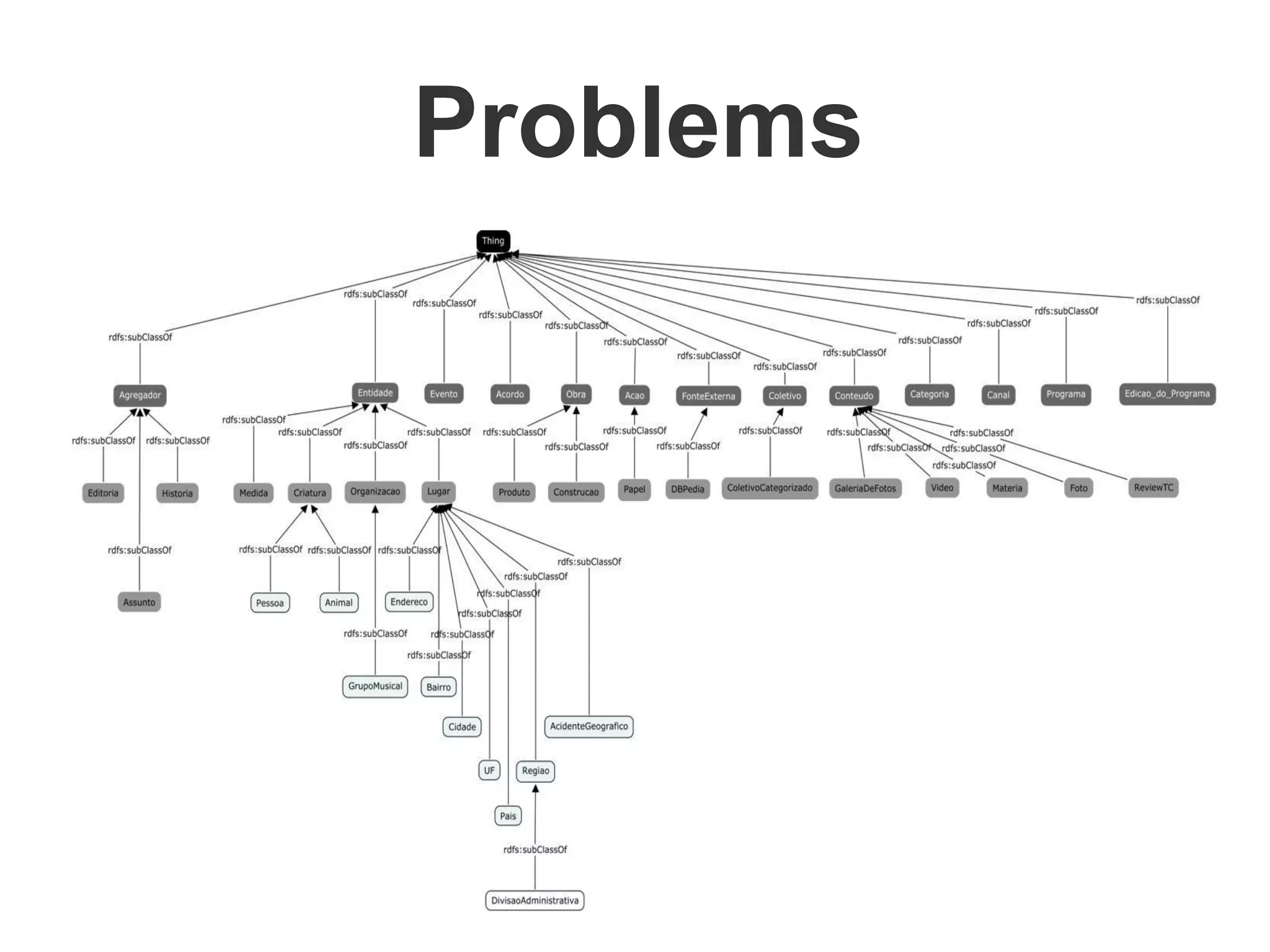
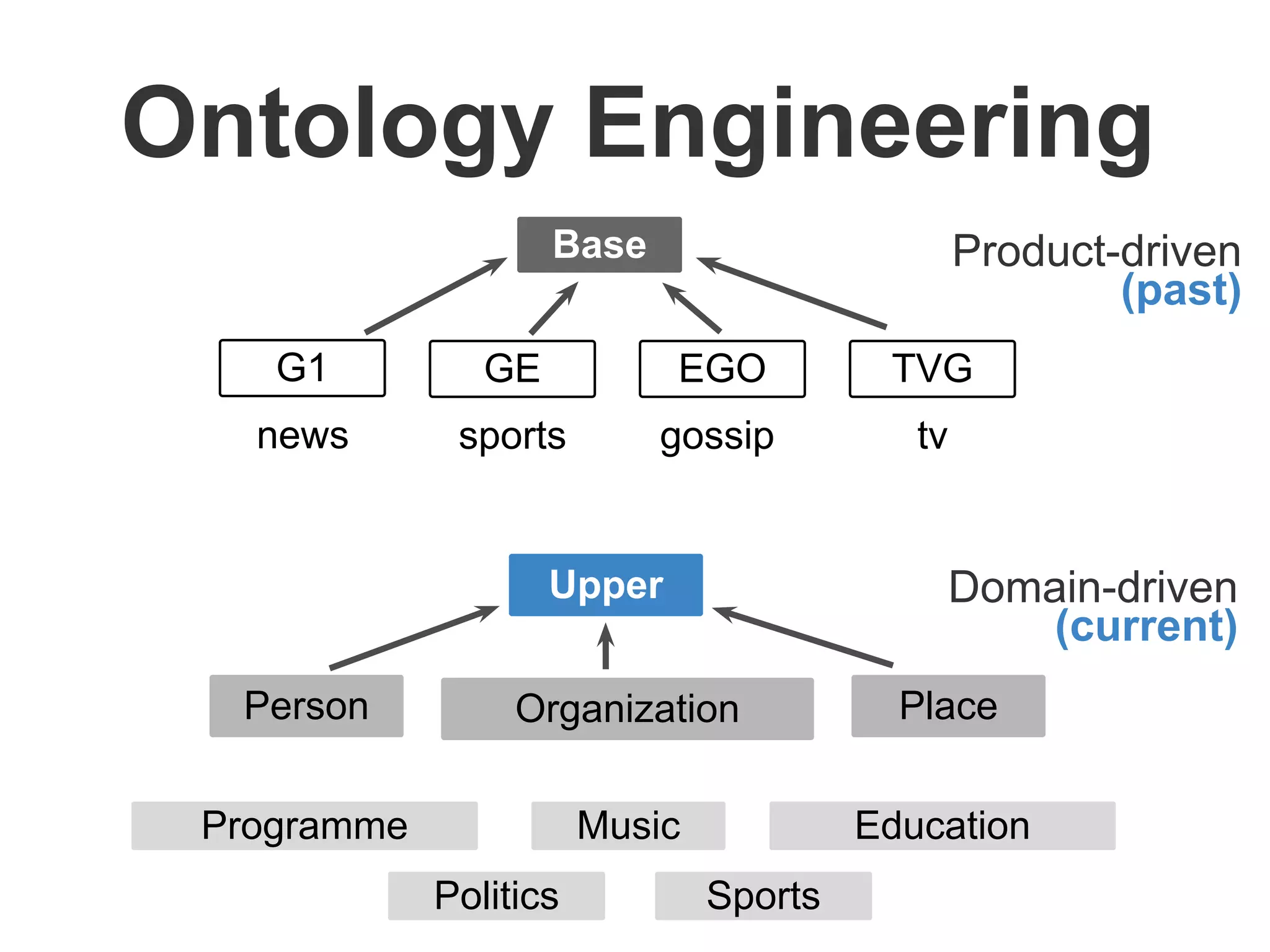
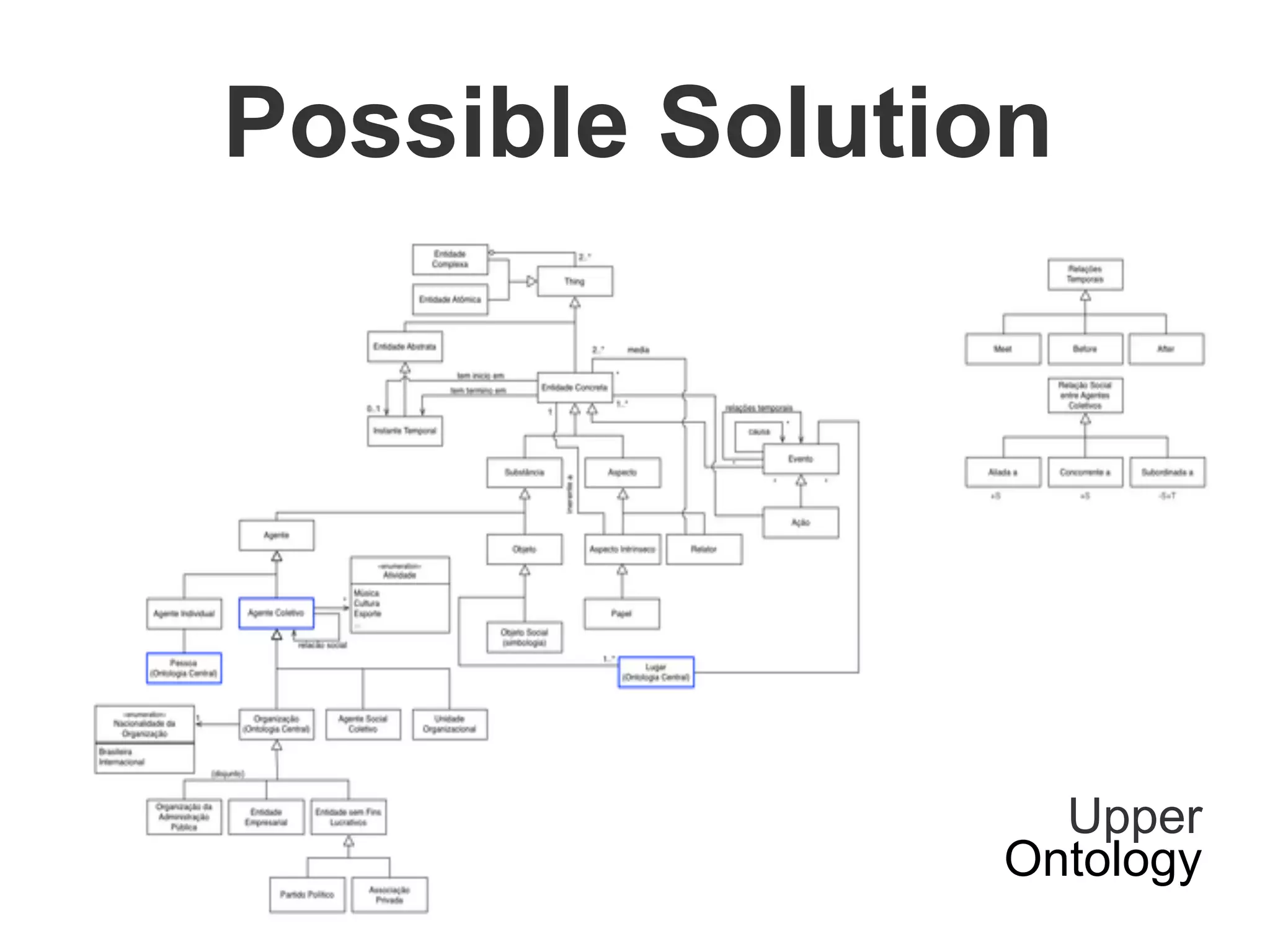



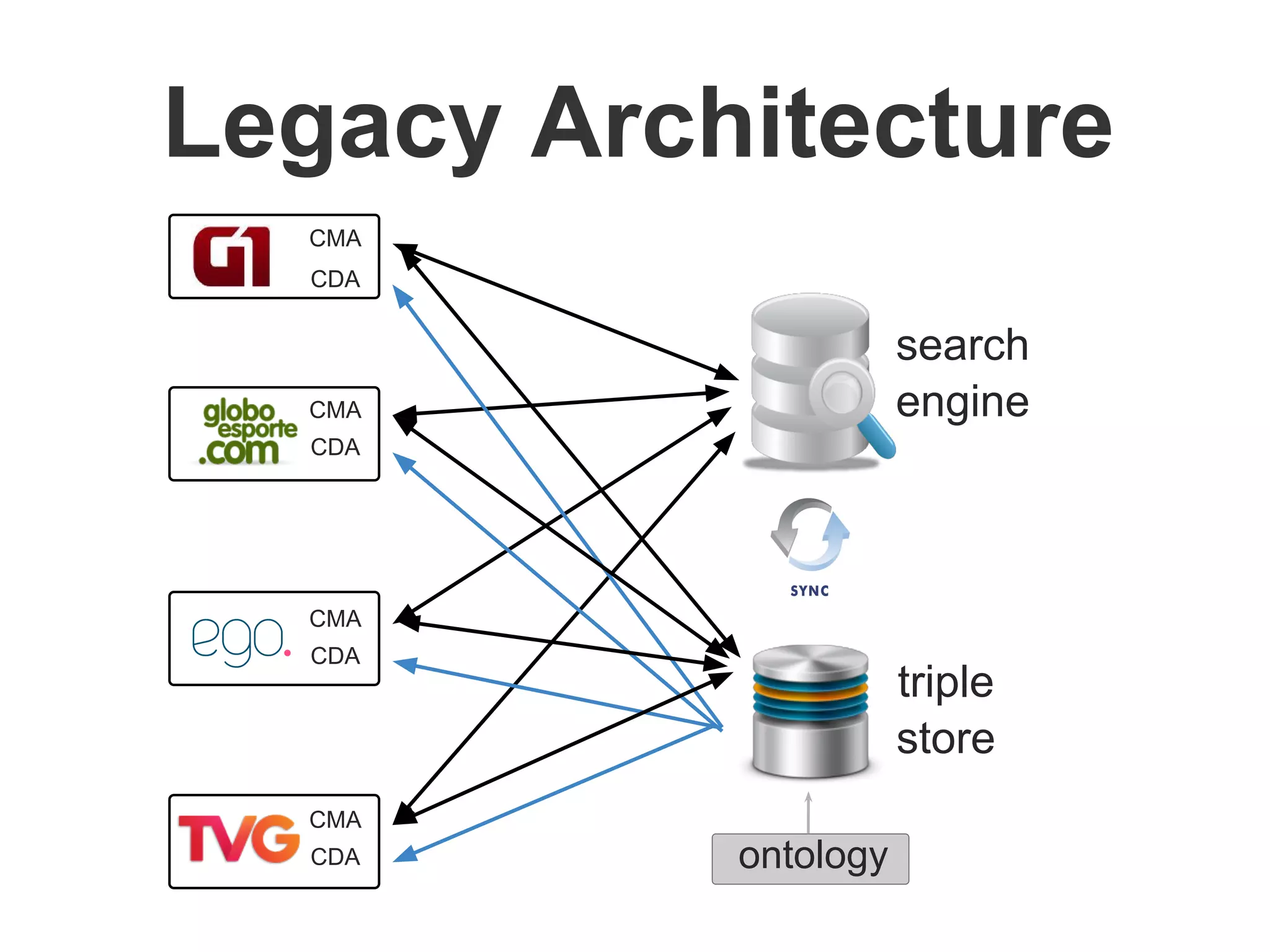
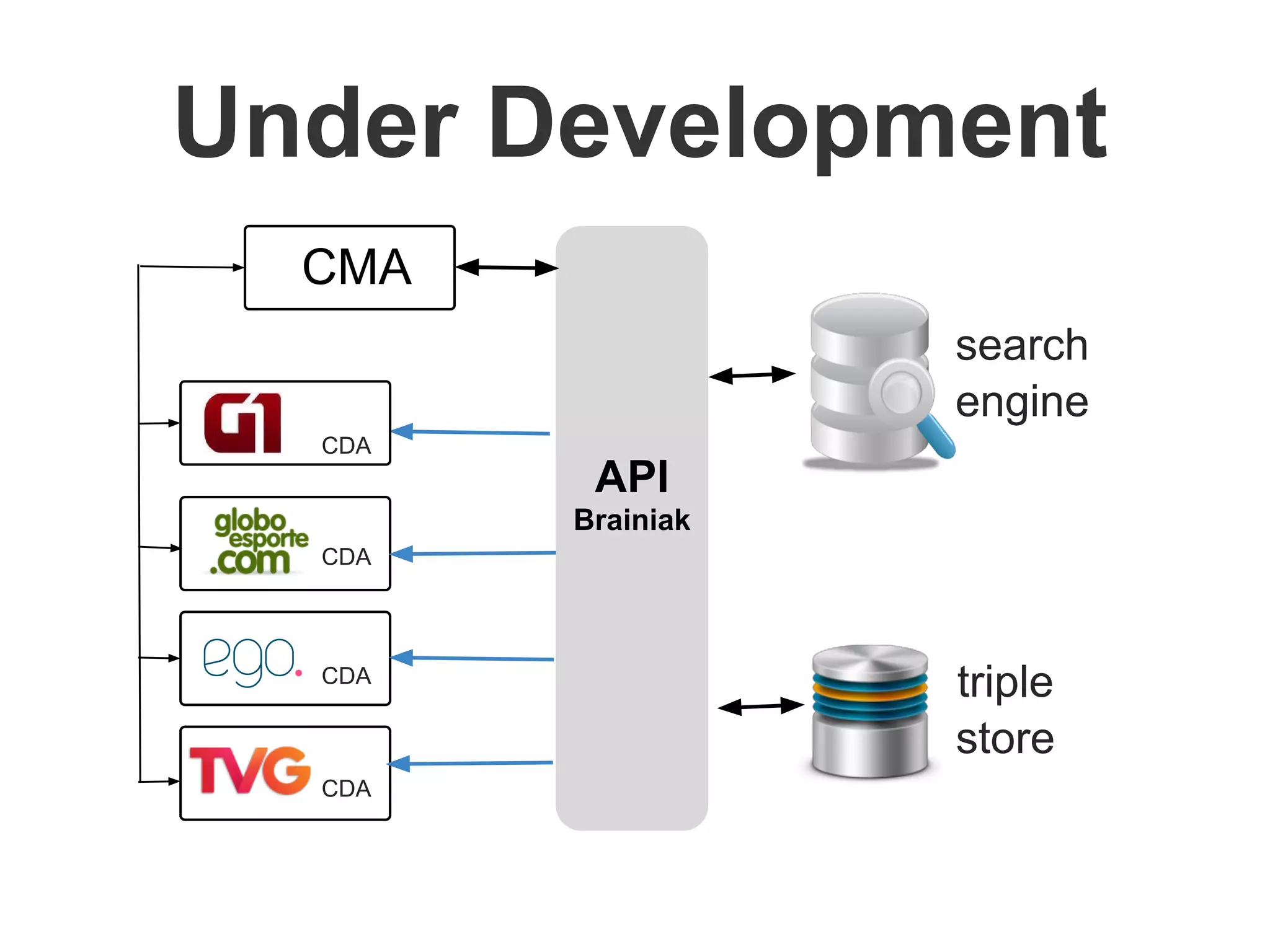


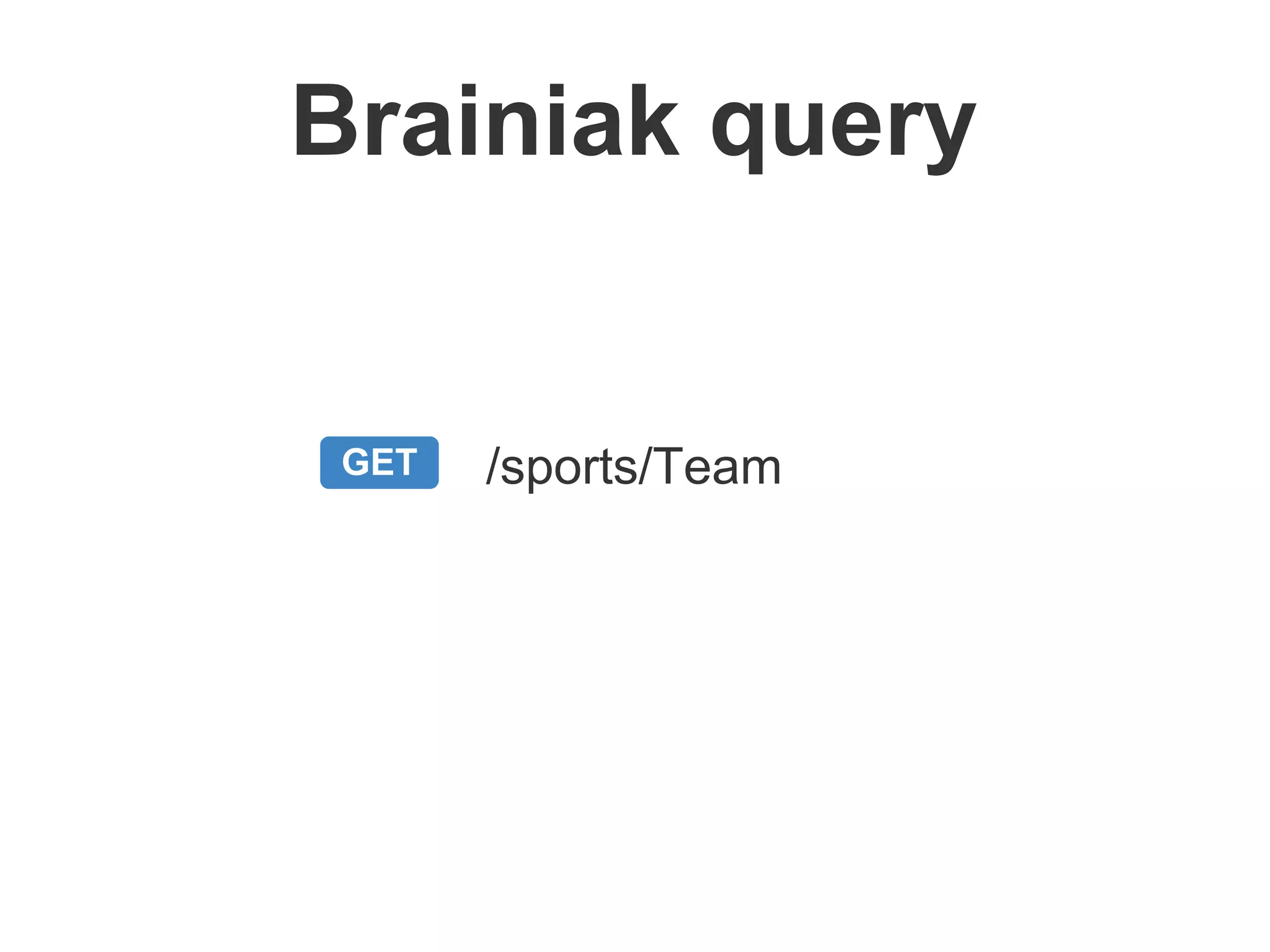





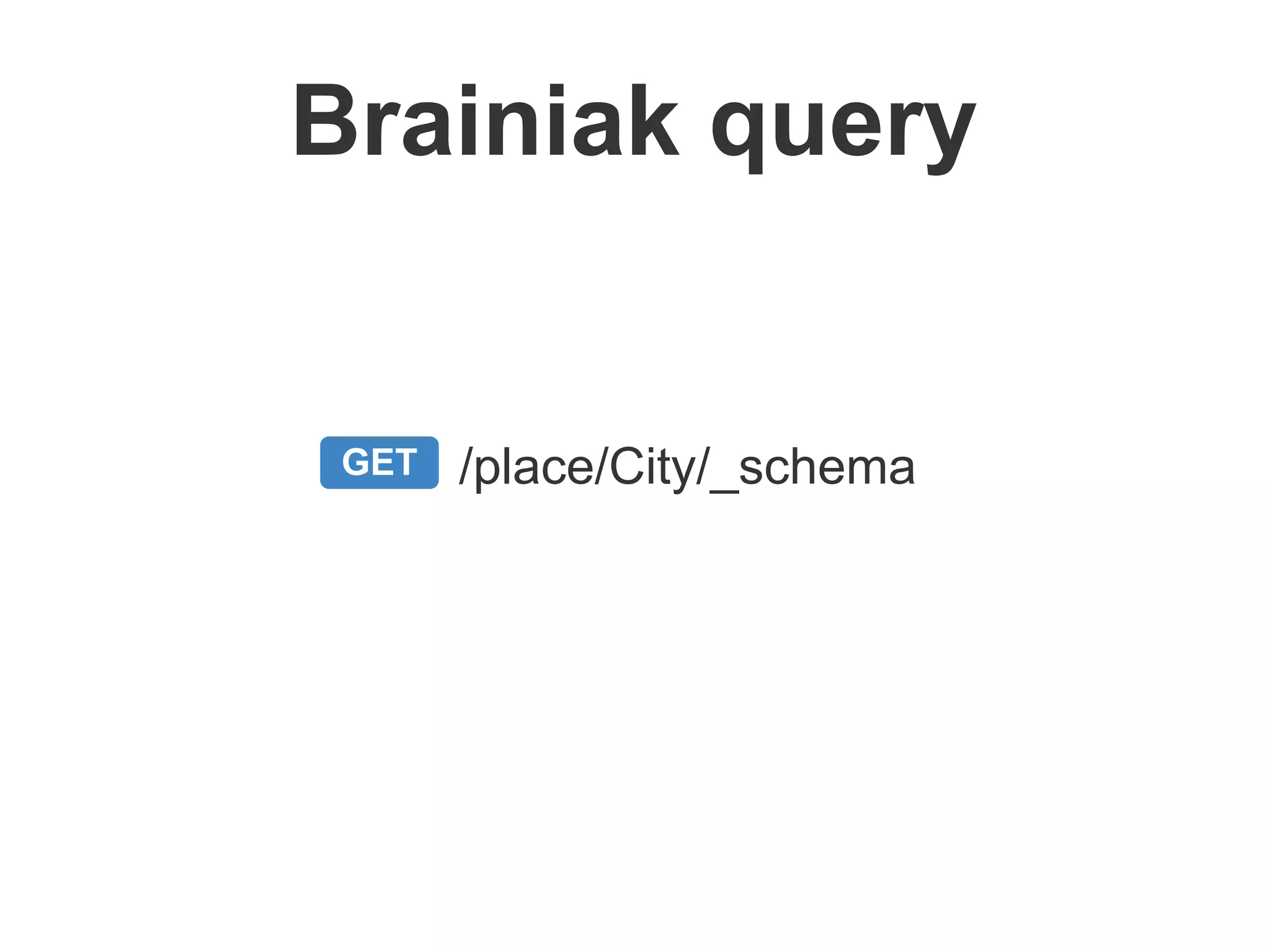





Brainiak is a new semantic data management platform being developed by Globo to address problems with their legacy linked data architecture. It features a RESTful API to access and manage semantic data. This decouples applications from the triplestore and improves performance. Brainiak will enable Globo to enrich search, improve annotation and content relationships, and link data to external sources like DBPedia. It has the potential to enhance the user experience on Globo's websites.














![PythonBrasil[8] closing](https://cdn.slidesharecdn.com/ss_thumbnails/pythonbrasil8closing-130219054907-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










![[Conference] Cognitive Graph Analytics on Company Data and News](https://cdn.slidesharecdn.com/ss_thumbnails/texas-data-day18-kiryakov-180131105058-thumbnail.jpg?width=640&height=640&fit=bounds)

























![PythonBrasil[8] - CPython for dummies](https://cdn.slidesharecdn.com/ss_thumbnails/cpythonfordummies-170610060108-thumbnail.jpg?width=640&height=640&fit=bounds)























