Download as PDF, PPTX





















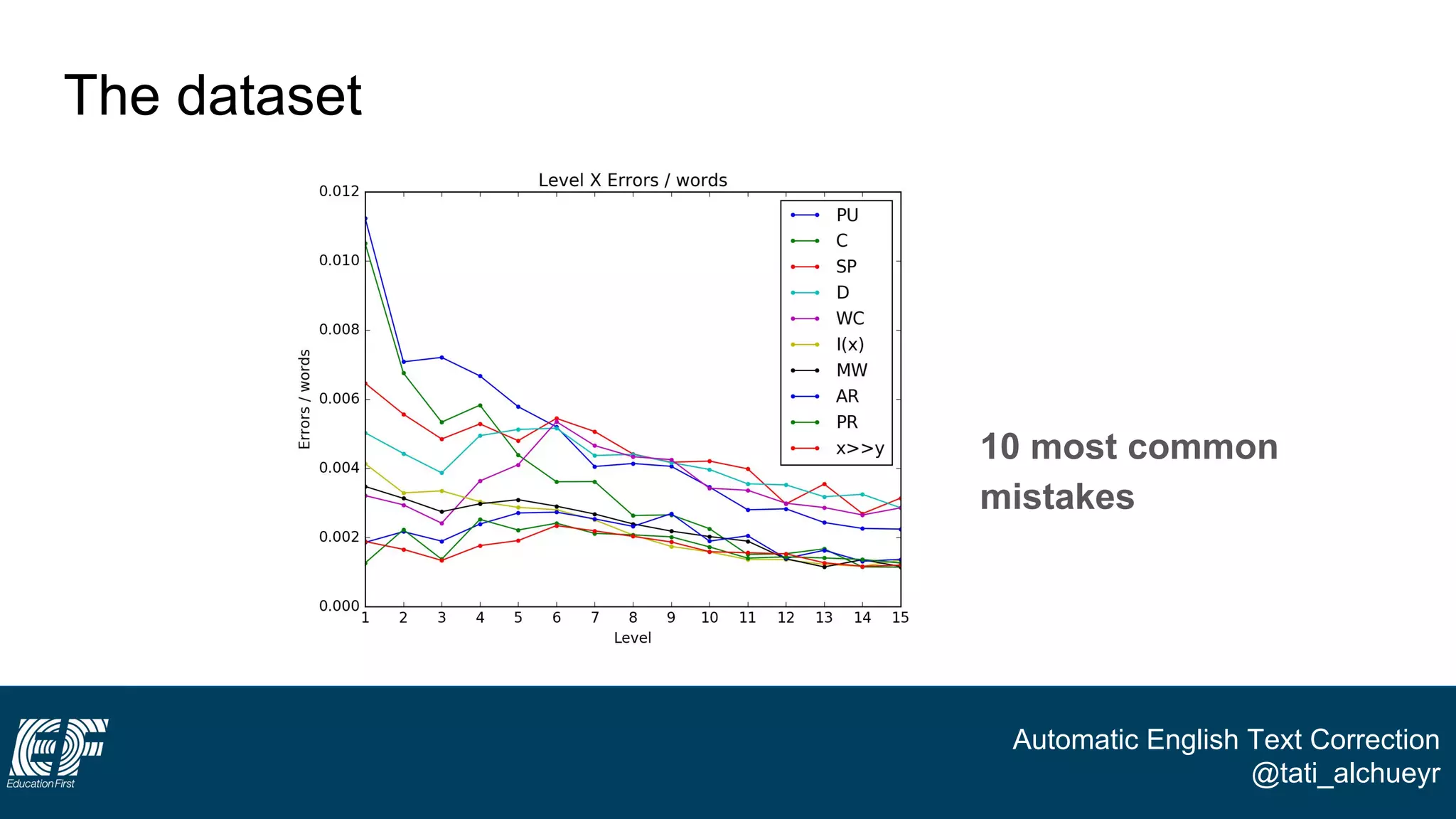

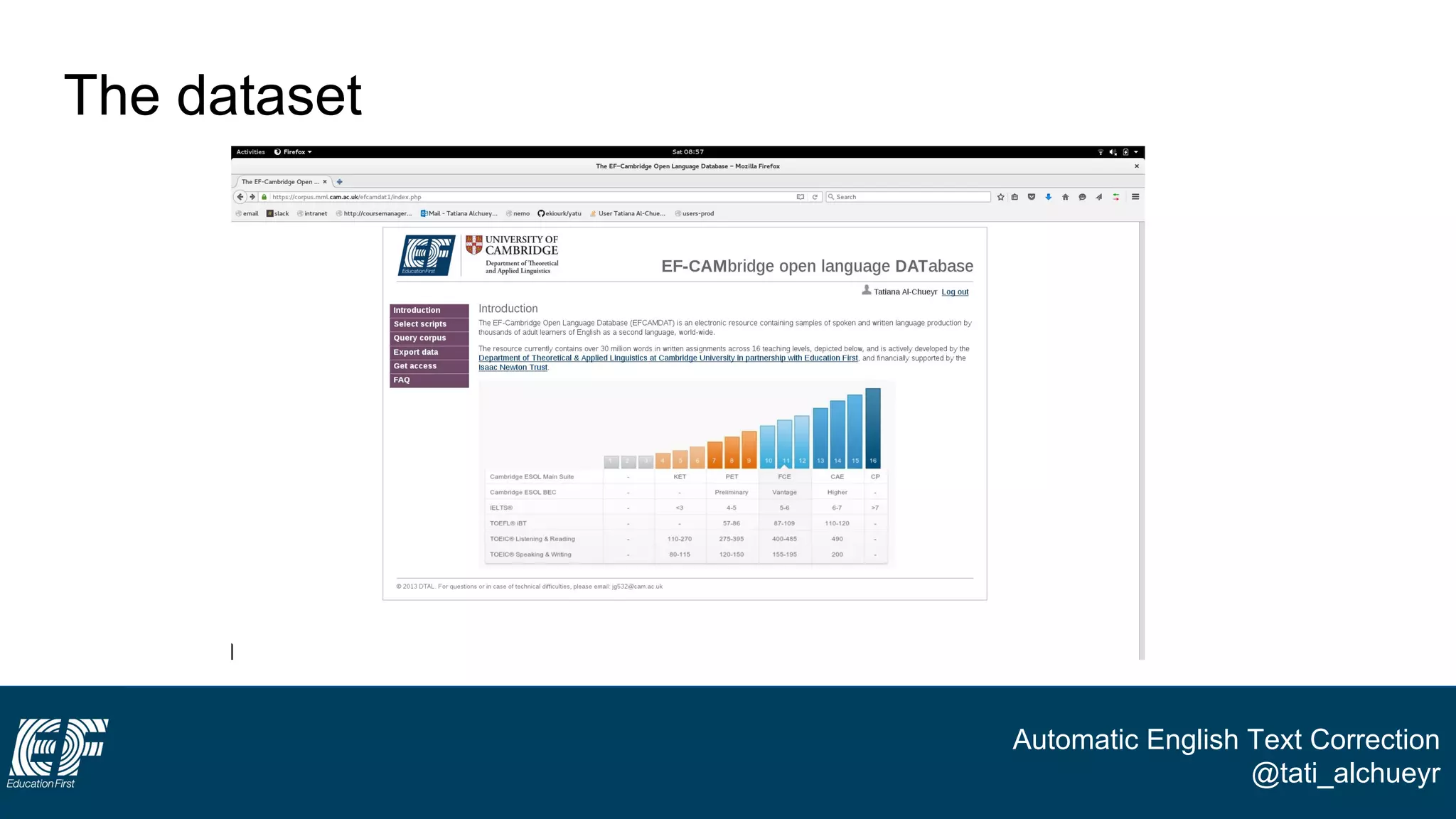
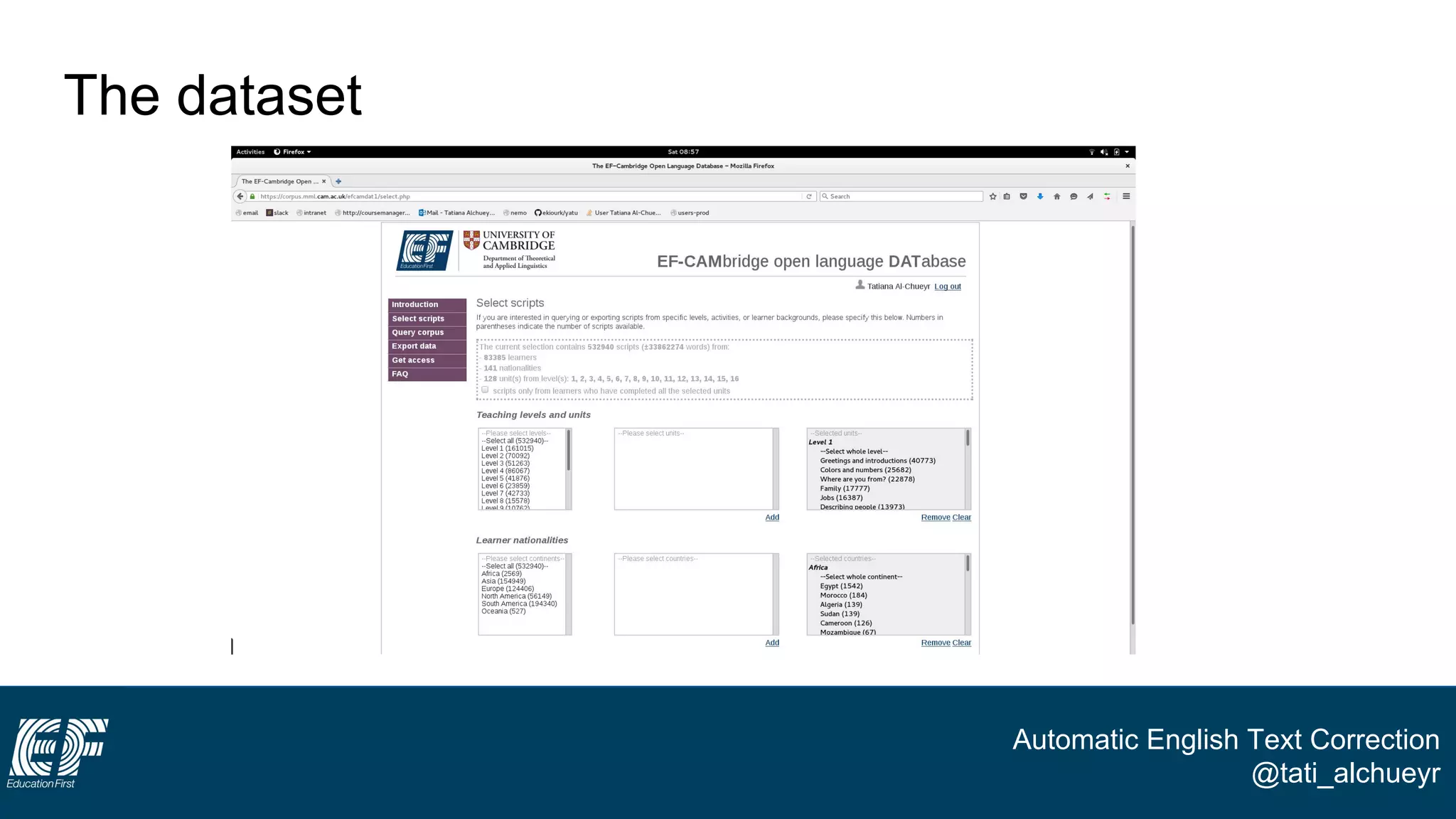

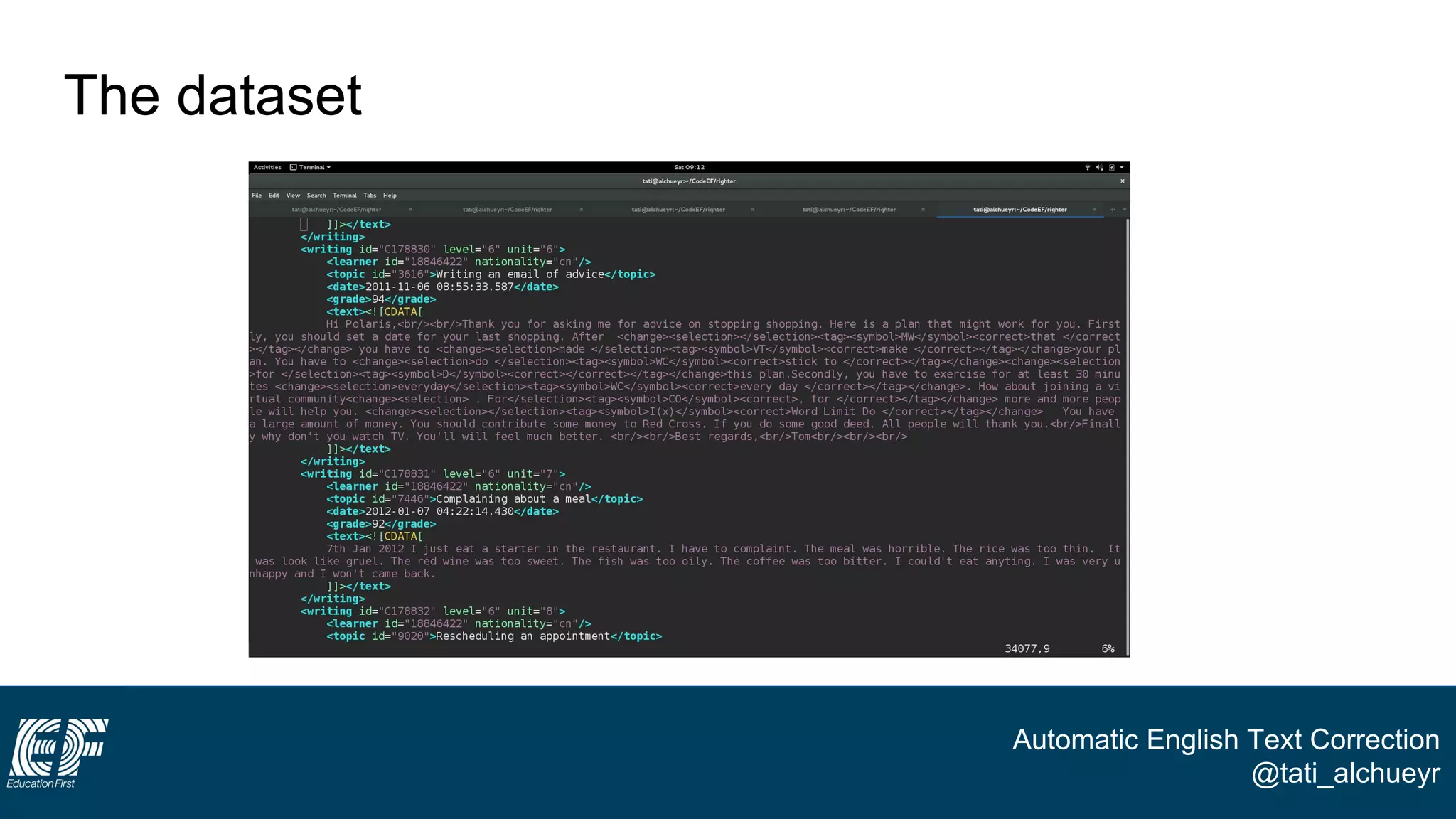







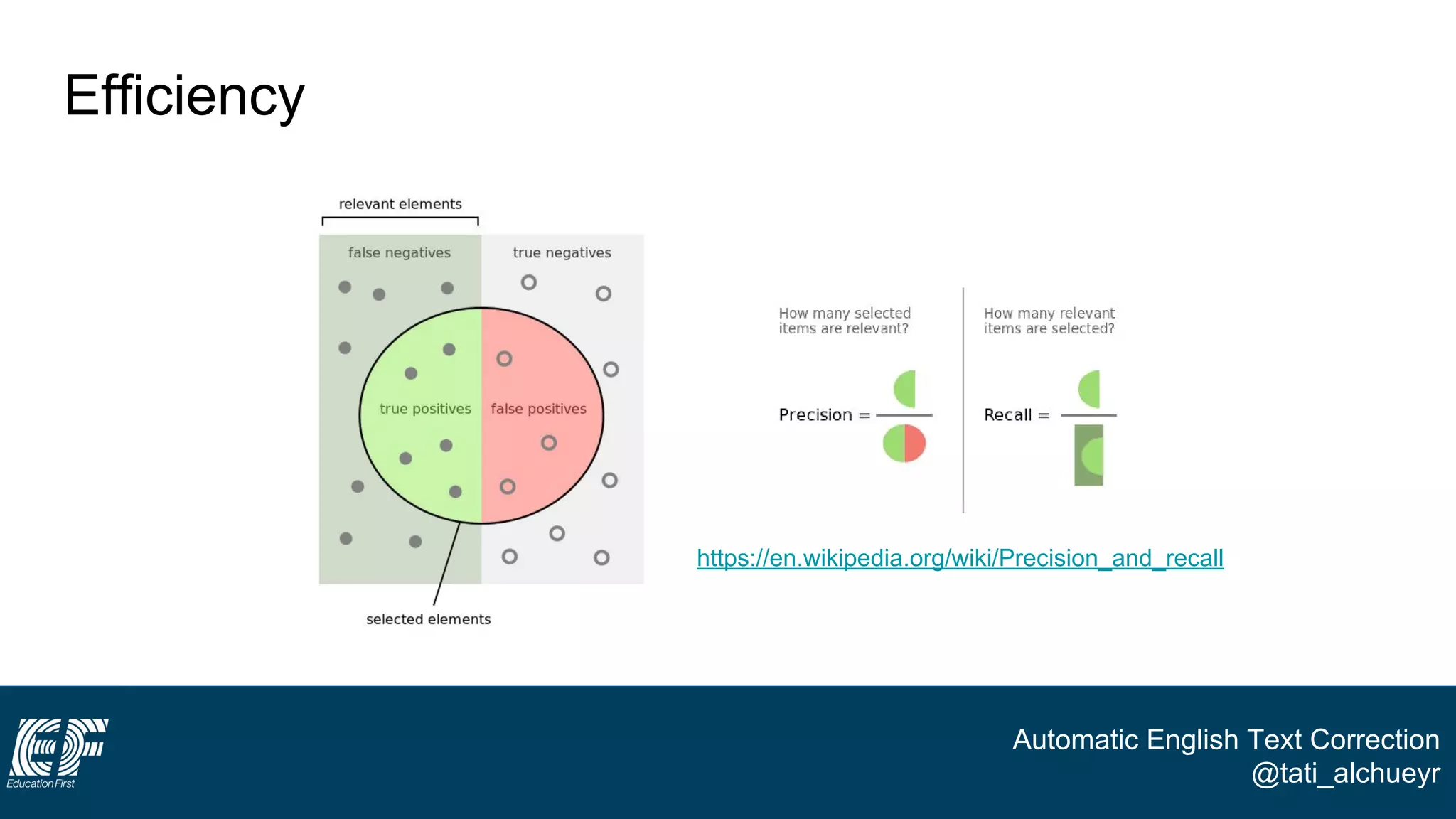




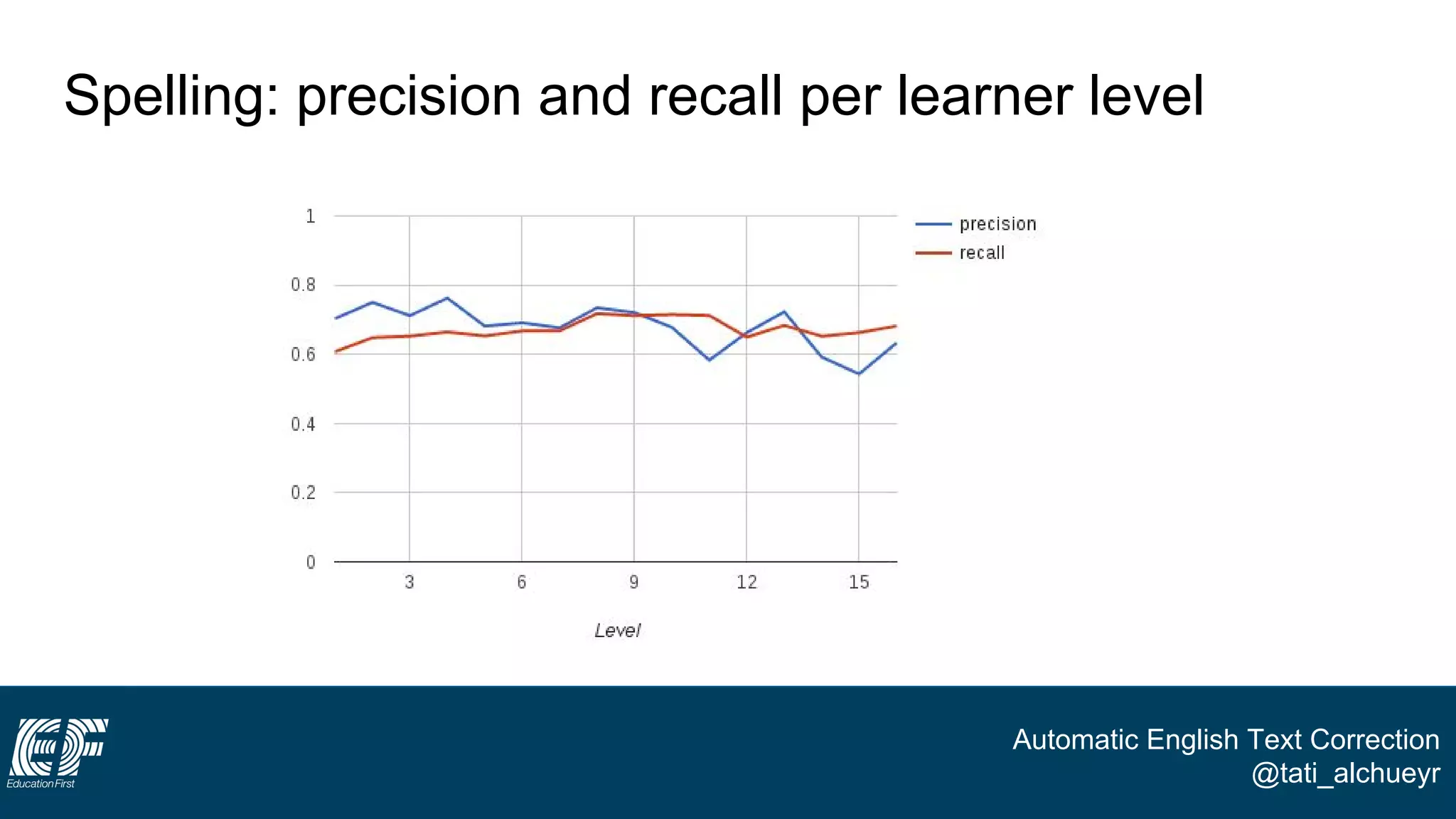
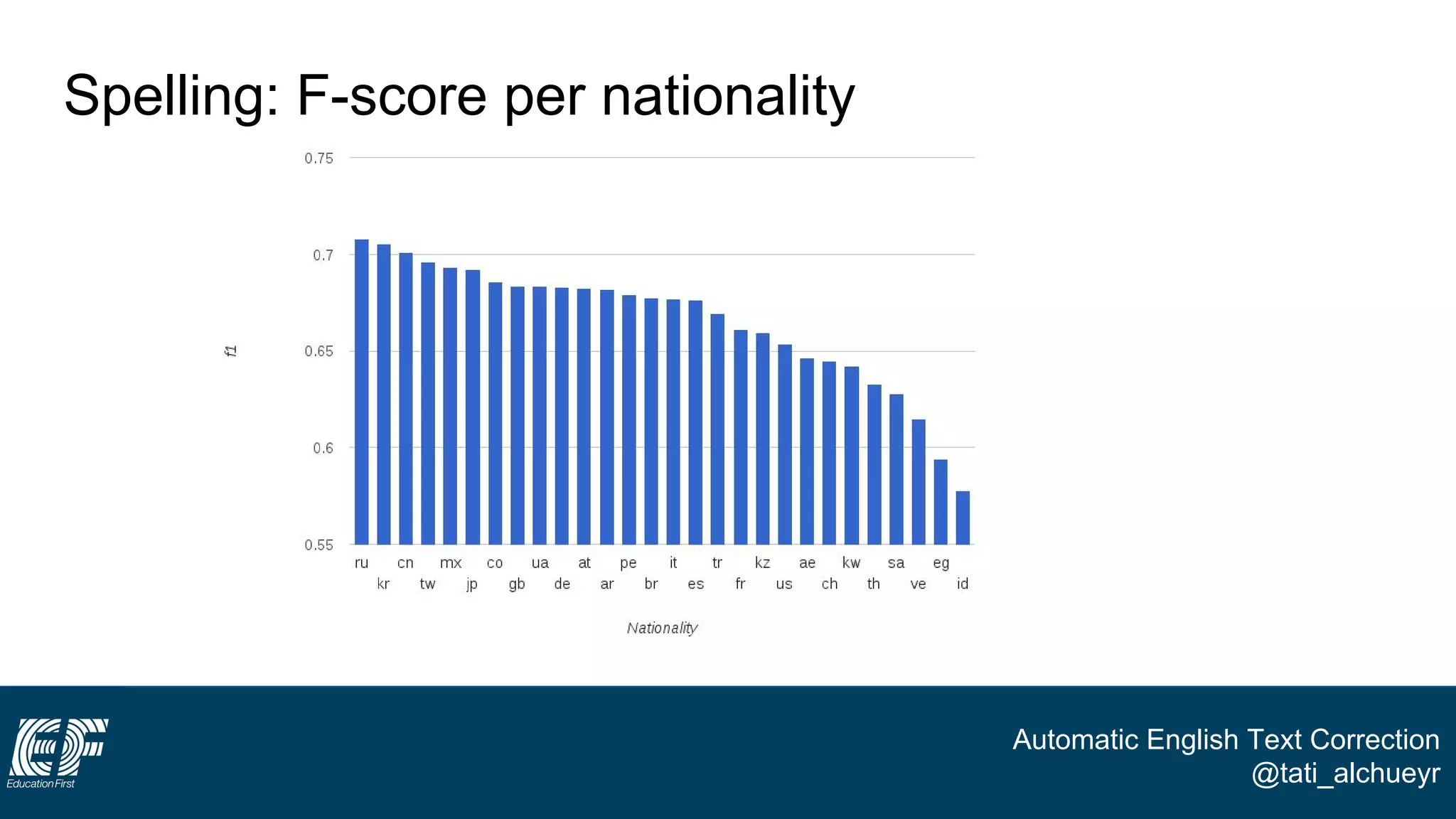



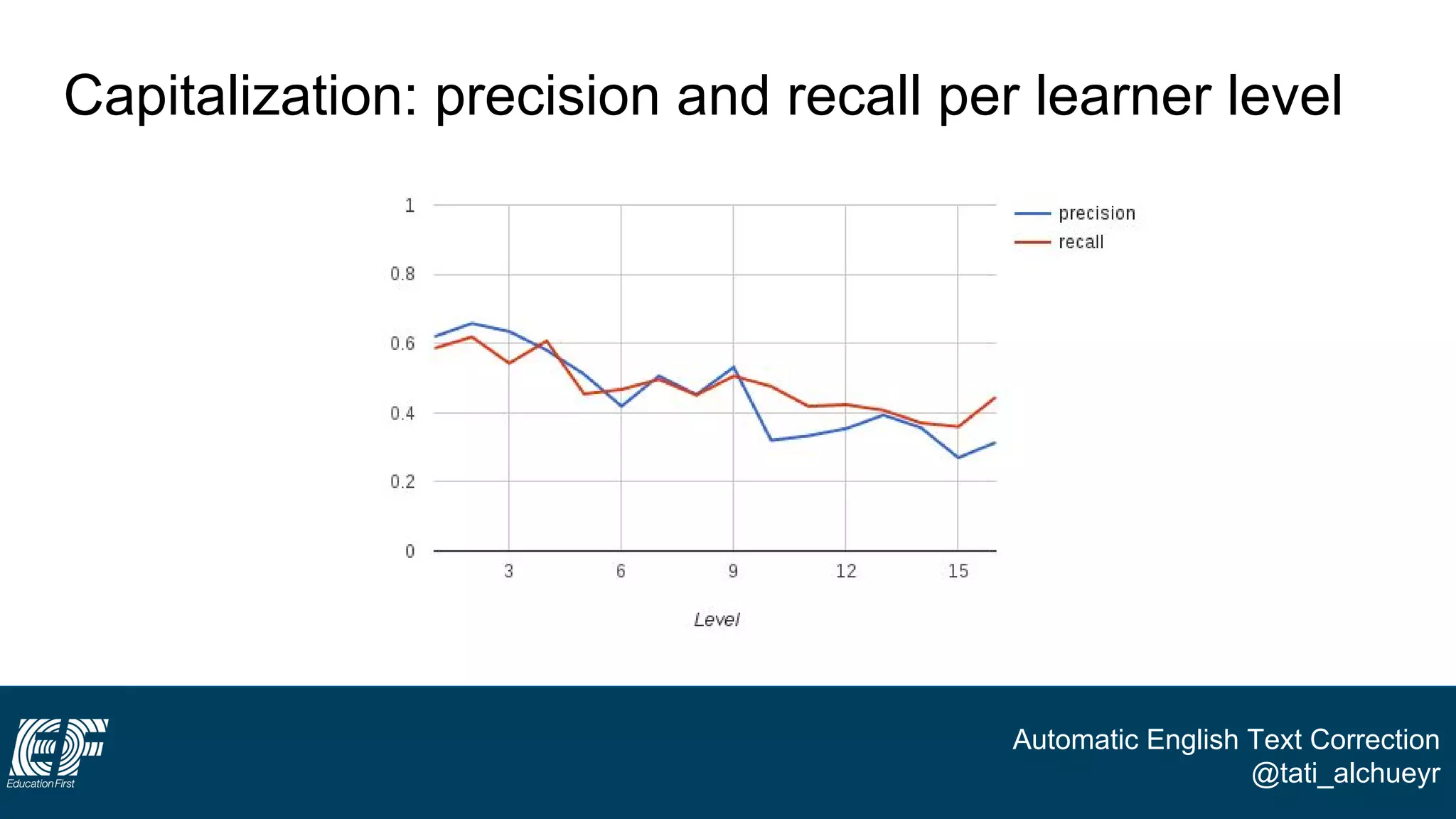
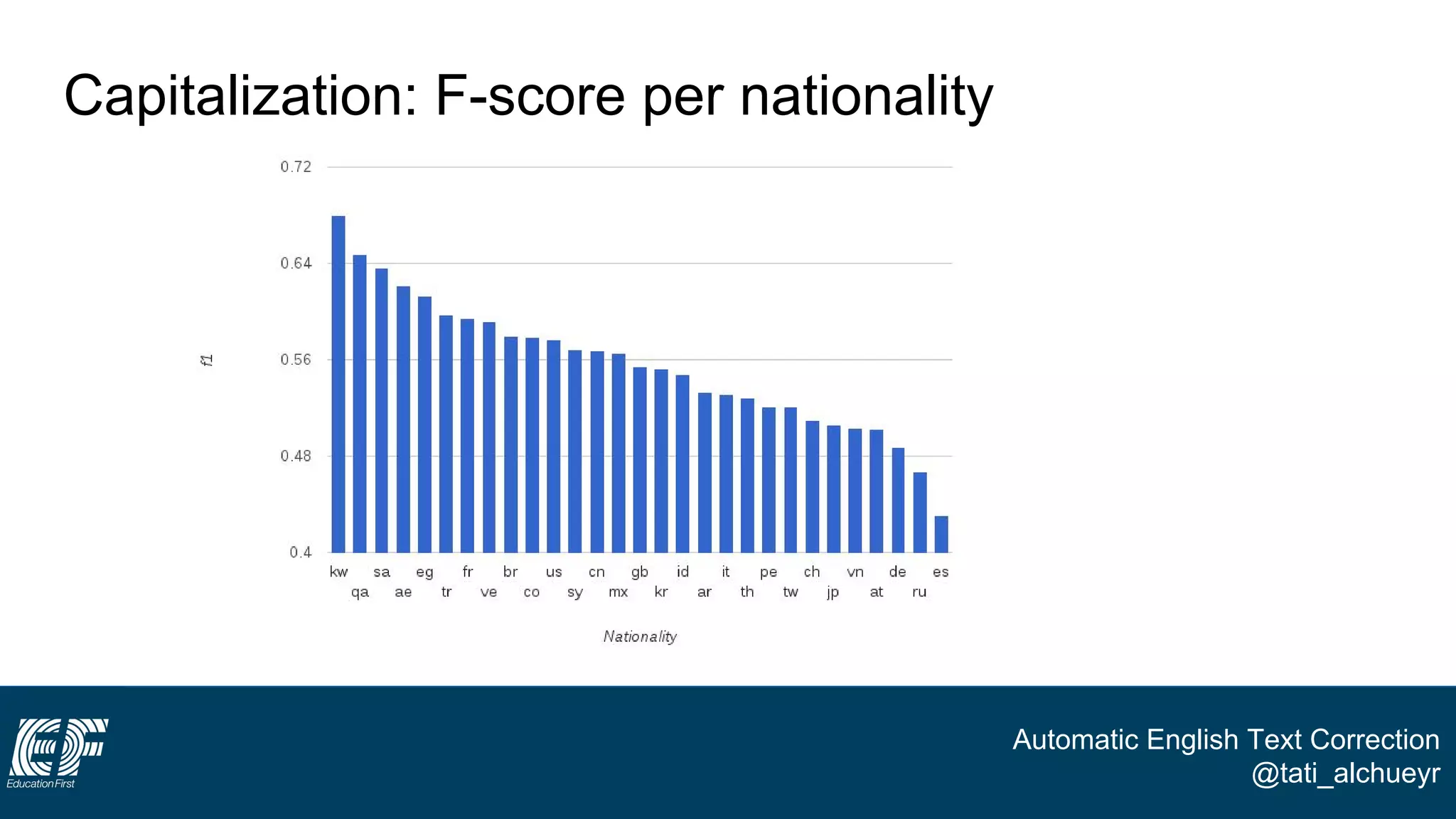




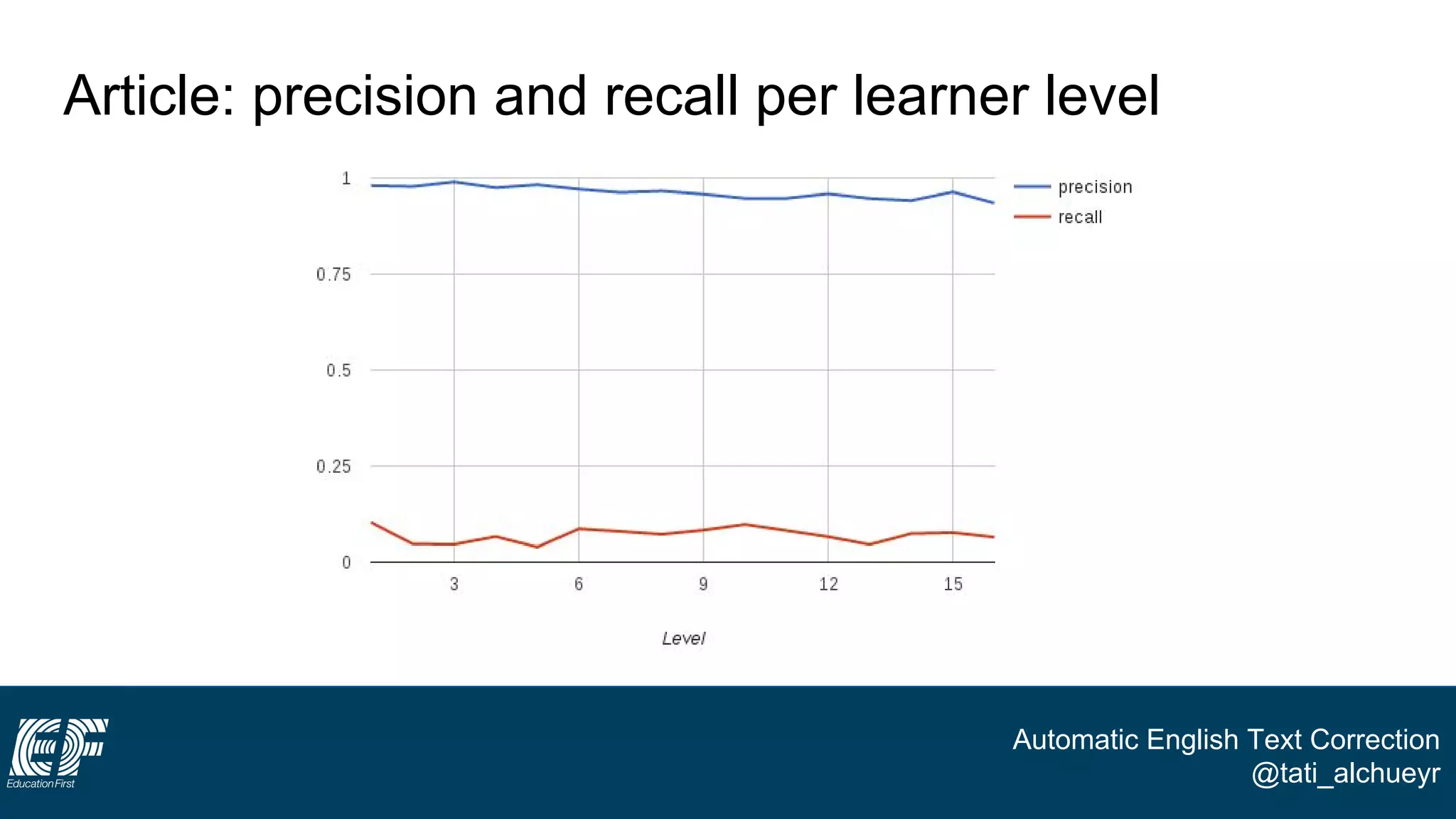
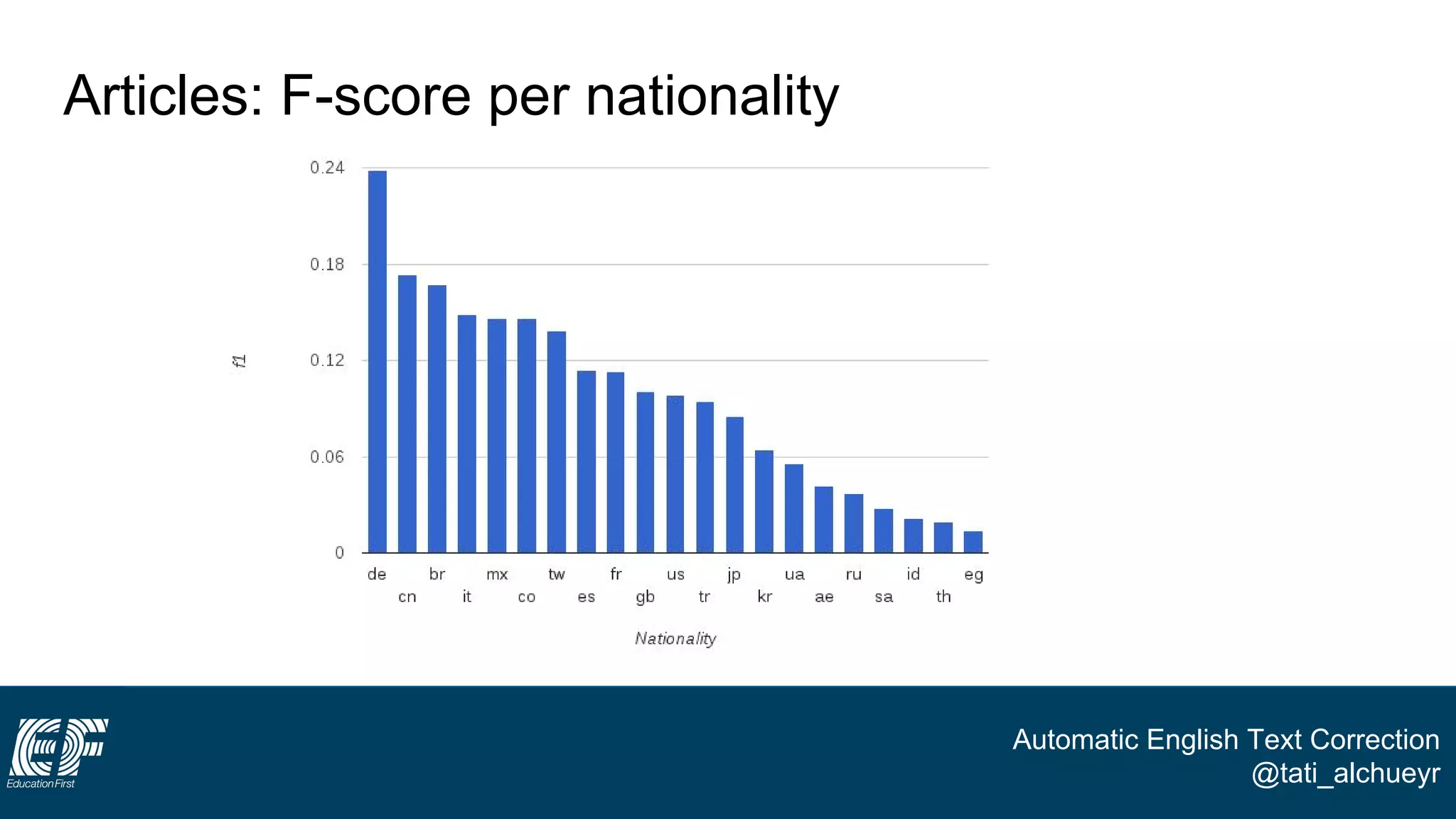










The document discusses a project led by Tatiana Al-Chueyr at EF Education First aimed at improving English essay evaluations through automated text correction tools. It outlines the challenges faced by teachers in assessing essays, introduces a large dataset of annotated learner essays, and describes the development of Python scripts that utilize heuristics to identify common mistakes such as spelling and capitalization. The presentation also touches on future improvements and the integration of user feedback to enhance the algorithm's effectiveness.



























![PythonBrasil[8] closing](https://cdn.slidesharecdn.com/ss_thumbnails/pythonbrasil8closing-130219054907-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






























![PythonBrasil[8] - CPython for dummies](https://cdn.slidesharecdn.com/ss_thumbnails/cpythonfordummies-170610060108-thumbnail.jpg?width=640&height=640&fit=bounds)



![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)



![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













