Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
KI
Uploaded by
Kenta IDA
PPTX, PDF
2,038 views
PSoC4 BLEで作る簡単無線センサーユニット
PSoCまつり2016で発表した、PSoC4 BLEで交流電流測定を行うお話です。
Technology
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Downloaded 15 times
1
/ 36
2
/ 36
3
/ 36
4
/ 36
5
/ 36
6
/ 36
7
/ 36
8
/ 36
9
/ 36
10
/ 36
11
/ 36
12
/ 36
13
/ 36
14
/ 36
15
/ 36
16
/ 36
17
/ 36
18
/ 36
19
/ 36
20
/ 36
21
/ 36
22
/ 36
23
/ 36
24
/ 36
25
/ 36
26
/ 36
27
/ 36
28
/ 36
29
/ 36
30
/ 36
31
/ 36
32
/ 36
33
/ 36
34
/ 36
35
/ 36
36
/ 36
More Related Content
PDF
Reflow Oven for SMT line E8
by
Mark Tung
PDF
PSoC4 ことはじめ -BLE版-
by
Tetsuya Noguchi
PPTX
PYNQ単体でUIを表示してみる(PYNQまつり)
by
Kenta IDA
PPTX
PSoCまつり「PSoCの美味しい料理法」
by
betaEncoder
PPTX
PYNQで○○してみた!
by
aster_ism
PPTX
Windows10 IoT CoreとBLE
by
Kenta IDA
PPTX
おそらく明日から役にたつC++11新機能
by
Kenta IDA
PPTX
PSoC Powered Human Powered Airplane
by
HirakuTOIDA
Reflow Oven for SMT line E8
by
Mark Tung
PSoC4 ことはじめ -BLE版-
by
Tetsuya Noguchi
PYNQ単体でUIを表示してみる(PYNQまつり)
by
Kenta IDA
PSoCまつり「PSoCの美味しい料理法」
by
betaEncoder
PYNQで○○してみた!
by
aster_ism
Windows10 IoT CoreとBLE
by
Kenta IDA
おそらく明日から役にたつC++11新機能
by
Kenta IDA
PSoC Powered Human Powered Airplane
by
HirakuTOIDA
Viewers also liked
PDF
手抜き大好きPSoC
by
hatris
PPTX
PYNQ 祭り: Pmod のプログラミング
by
ryos36
PDF
5 Social Media Mistakes Your Brand Should Avoid
by
Spyglass Digital
PPT
Sanipatin j. caracteristicas del director de proyecto
by
Jonathan Sanipatin
PDF
Innovations™ Magazine Q4 2014 - Chinese
by
T.D. Williamson
PPTX
αρκούδα, λύκος, ελάφι
by
kaloudizoi
PDF
Microscopia de fibras
by
Paola Ivana Giordanino
PDF
Finding an Escape from the Digital World - It's Importance & Why You Should T...
by
Thomas Wall
PPTX
πλανητες και ηλιακο συστημα
by
kaloudizoi
PPTX
Virtual coach situacion del problema, etc
by
Jonathan Sanipatin
PDF
SyNTHEMA multimedia content enrichment
by
Siro Massaria
PDF
Mahabharata Bahasa Indonesia
by
Aditya Hanif
PPTX
Knowledge 2 artifact
by
bildenw
PPTX
Virtual coach arbol de objetivos
by
Jonathan Sanipatin
PPT
οι εποχές
by
nellydom
PDF
Innovations™ Magazine July - September 2014
by
T.D. Williamson
PDF
2016 Fair Book Revised
by
Smooth Sailing Online Support
PPT
Commerce Classes in Chandigarh
by
chdcommerce1
PPTX
Marco logico virtual coachbb
by
Jonathan Sanipatin
手抜き大好きPSoC
by
hatris
PYNQ 祭り: Pmod のプログラミング
by
ryos36
5 Social Media Mistakes Your Brand Should Avoid
by
Spyglass Digital
Sanipatin j. caracteristicas del director de proyecto
by
Jonathan Sanipatin
Innovations™ Magazine Q4 2014 - Chinese
by
T.D. Williamson
αρκούδα, λύκος, ελάφι
by
kaloudizoi
Microscopia de fibras
by
Paola Ivana Giordanino
Finding an Escape from the Digital World - It's Importance & Why You Should T...
by
Thomas Wall
πλανητες και ηλιακο συστημα
by
kaloudizoi
Virtual coach situacion del problema, etc
by
Jonathan Sanipatin
SyNTHEMA multimedia content enrichment
by
Siro Massaria
Mahabharata Bahasa Indonesia
by
Aditya Hanif
Knowledge 2 artifact
by
bildenw
Virtual coach arbol de objetivos
by
Jonathan Sanipatin
οι εποχές
by
nellydom
Innovations™ Magazine July - September 2014
by
T.D. Williamson
2016 Fair Book Revised
by
Smooth Sailing Online Support
Commerce Classes in Chandigarh
by
chdcommerce1
Marco logico virtual coachbb
by
Jonathan Sanipatin
More from Kenta IDA
PPTX
M5StackにFPGAをつないでみた
by
Kenta IDA
PPTX
ESP32特集の内容紹介
by
Kenta IDA
PPTX
カスタムブロックで自作モジュールをUIFlow対応にする
by
Kenta IDA
PPTX
Using SORACOM 3G Module From MicroPython
by
Kenta IDA
PPTX
M5StackをRustで動かす
by
Kenta IDA
PPTX
MicroPythonのCモジュールを作ってみる
by
Kenta IDA
PPTX
ESP32開発環境まとめ2
by
Kenta IDA
PPTX
ESP32開発環境まとめ
by
Kenta IDA
PPTX
EC2 F1 Virtual JTAG
by
Kenta IDA
M5StackにFPGAをつないでみた
by
Kenta IDA
ESP32特集の内容紹介
by
Kenta IDA
カスタムブロックで自作モジュールをUIFlow対応にする
by
Kenta IDA
Using SORACOM 3G Module From MicroPython
by
Kenta IDA
M5StackをRustで動かす
by
Kenta IDA
MicroPythonのCモジュールを作ってみる
by
Kenta IDA
ESP32開発環境まとめ2
by
Kenta IDA
ESP32開発環境まとめ
by
Kenta IDA
EC2 F1 Virtual JTAG
by
Kenta IDA
PSoC4 BLEで作る簡単無線センサーユニット
1.
PSoC4 BLEで作る 簡単無線センサーユニット PSoCまつり2016 2016/09/17 Kenta IDA
(@ciniml)
2.
自己紹介 •Kenta IDA (@ciniml) •仕事:ワイヤボンダのソフト開発 •
組み込みCPU用とWindows用 •使用言語:C#, C++, 時々VHDL, 仕方なくC •使用回路CAD:KiCad PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17 2
3.
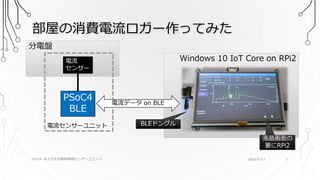
Windows 10 IoT
Core on RPi2 部屋の消費電流ロガー作ってみた PSoC4 BLEで作る簡単無線センサーユニット 分電盤 BLEドングル 液晶画面の 裏にRPi2 2016/9/17 3 電流 センサー PSoC4 BLE 電流センサーユニット 電流データ on BLE
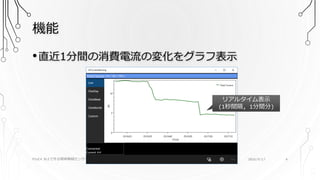
4.
機能 PSoC4 BLEで作る簡単無線センサーユニット •直近1分間の消費電流の変化をグラフ表示 リアルタイム表示 (1秒間隔, 1分間分) 2016/9/17
4
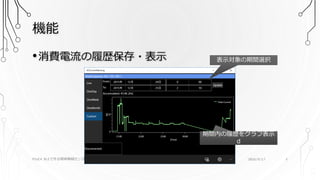
5.
機能 PSoC4 BLEで作る簡単無線センサーユニット •消費電流の履歴保存・表示 表示対象の期間選択 期間内の履歴をグラフ表示 d 2016/9/17
5
6.
センサーユニット構成 2016/9/17PSoC4 BLEで作る簡単無線センサーユニット 6
7.
センサーユニットの構成 PSoC4 BLEで作る簡単無線センサーユニット カレント トランス PSoC4 BLE (CY8CKIT-142 /EZBLE
PSoC) 2016/9/17 7 電池 (CR2032) •カレントトランス • 交流電流測定 •電池 • CR2032 (コイン電池) •PSoC4 BLE • センサ処理 • BLE通信
8.
カレントトランスの信号 PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
8 • カレントトランス • センサ内に通した導線の交流電流を測定 • 導線の1/nの電流が流れる • 抵抗で電圧に変換 • あまり大きく出来ない(10Ωとか) • 線形でなくなる →10 [mV/A]くらいの出力 →増幅しないとADC辛い…
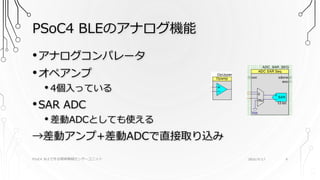
9.
PSoC4 BLEのアナログ機能 PSoC4 BLEで作る簡単無線センサーユニット
2016/9/17 9 •アナログコンパレータ •オペアンプ • 4個入っている •SAR ADC • 差動ADCとしても使える →差動アンプ+差動ADCで直接取り込み
10.
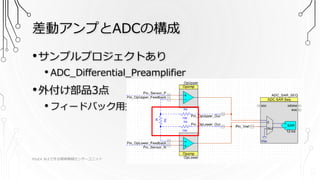
差動アンプとADCの構成 PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
10 •サンプルプロジェクトあり • ADC_Differential_Preamplifier •外付け部品3点 • フィードバック用抵抗
11.
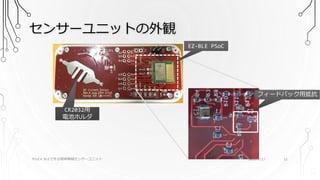
センサーユニットの外観 PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
11 CR2032用 電池ホルダ EZ-BLE PSoC フィードバック用抵抗
12.
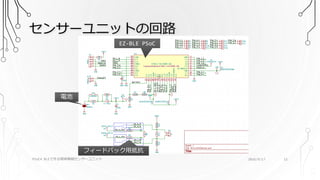
センサーユニットの回路 PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
12 EZ-BLE PSoC フィードバック用抵抗 電池
13.
最終的なPSoCの内部設定 2016/9/17PSoC4 BLEで作る簡単無線センサーユニット 13
14.
開発環境 2016/9/17PSoC4 BLEで作る簡単無線センサーユニット 14
15.
開発用キット PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
15 •CY8CKIT-042-BLE Bluetooth Low Energy Pioneer Kit • BLEユニット開発に必要な物一式揃う • Kitprog(デバッガ)付きベースボード • CY8CKIT-142 PSoC4 BLEモジュール • CySmart BLE (BLE通信テストモジュール) • 工事設計認証済み
16.
開発用キット PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
16 CY8CKIT-042-BLE ベースボード CY8CKIT-142 電流検出ジャンパ
17.
開発用キット PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
17 •余談:新しいやつ出てる • CY8CKIT-042-BLE-A • CY8CKIT-143Aが付属 • CY8CKIT-142ではない →工事設計認証(MIC)どころかFCC/CEすら通ってない →気を付けよう。
18.
CySmart PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
18 •BLE通信テスト用のモジュール • Windows用ソフト(CySmart)から使う •BLE通信の一通りの確認が可能 • スキャン、接続 • キャラクタリスティックの読み書き •セントラル・ペリフェラルの問題切り分けに便利 • WindowsのBLEスタックがアレだったりもするので。
19.
CySmart PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
19
20.
BLE通信処理 2016/9/17PSoC4 BLEで作る簡単無線センサーユニット 20
21.
BLEの通信処理 PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
21 •基本 • 値(キャラクタリスティック)の読み書き • 値の集まり(サービス)で機能を識別 →サービスを定義する必要あり •定義済みサービス • 広く使われる物は定義済み • Bluetooth SIGが管理
22.
カスタムサービスの定義 PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
22 •カスタムサービス • 定義済みでないものは自分で定義 • 当然、PSoC Creatorでもサポート • アプリケーションノートあり • AN91162 - Creating a BLE Custom Profile
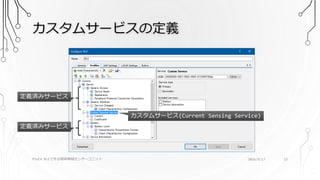
23.
カスタムサービスの定義 PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
23 カスタムサービス(Current Sensing Service) 定義済みサービス 定義済みサービス
24.
カスタムサービスの定義 PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
24 カスタムサービス (Current Sensing Service) •Current Sensing Service • 2つのキャラクタリスティック • Current • センサの生の測定値 • Coefficient • センサ測定値を[A]単位に変換するための係数 • PSoC4 BLEにはFPUが無いのでセントラル側で変換
25.
消費電力 2016/9/17PSoC4 BLEで作る簡単無線センサーユニット 25
26.
消費電力の削減 PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
26 •電源:CR2032 • 定格容量 220[mAh] •目標:1ヶ月連続動作 • 24[h]*30[d] = 720[h] • 220[mAh]/720[h] ≒ 0.31[mA] →平均消費電流 0.31[mA]以下
27.
消費電力の削減 PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
27 •極力寝る • =CPU、周辺回路を止める (DEEP SLEEP) •3つのクロック • ECO:BLE用 外部水晶発振子(24[MHz]) • IMO:内蔵発振回路(48[MHz]) CPU用 • WCO:外部水晶発振子(32.768[kHz]) →BLE、CPUを極力止める
28.
BLEの通信間隔 PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
28 •BLE通信 • CPU+BLE回路が必要 • かなり消費電流大きい • 定常5[mA]、ピーク~20[mA] • 極力通信しない →通信パラメータで1[s]間隔に設定 Connection interval
29.
BLE通信時の電流波形 PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
29 •簡易電流プローブ • 10[mV]=1[mA] •ピーク18[mA] •積分値26.3[uAs]
30.
交流電流の測定 PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
30 • 3.2[kSPS]、64点 • 50[Hz]の1周期分 • CPU+ADC • IMO(48[MHz])が必要 • ADCが終われば寝られる • 1/3.2[ms]で割り込み • WDT使用 • DEEP SLEEPからタイマ割り込みでは 起きられない →BLE同様1[s]間隔で測定 20[ms]
31.
交流電流計測時の電流波形 PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
31 •3.2[kSPS]、64点 • 50[Hz]の1周期分 •ピーク5.3[mA] •積分値33.8[uAs]
32.
BLE通信時の注意点 PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
32 •データ送信時はBLEの状態を確認 • BLEが起きている時に送信要求 • でないと次の送信タイミングまで寝なくなる • Cypressリポジトリのサンプルコードを確認 • GitHubのcypresssemiconductorco/BLE BLE状態取得関数 ECO安定=送信タイミングなので起きた
33.
BLE通信時の注意点 PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
33 •計測後に無駄な時間 • CPU+BLEが起きたまま • 積分値:258[uAs] •ADCタイミング依存 • 場合によりもっと増える • 5[mAs]とか 計測 無駄 計測結果送信要求 BLE起動 BLE送信 タイミング
34.
まとめ PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
34 •PSoC4 BLEは • オペアンプとか内蔵されてて便利 • EZ-BLE PSoCなら数点の外付け部品のみで センサユニットが作れる •まずはCY8CKIT-042-BLE買うと良い
35.
ソースコード PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
35 •GitHub • ciniml/ACCurrentSensor_PSoC4 • 興味がある方はどうぞ。
36.
おしまい PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17
36
Download




![カレントトランスの信号
PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17 8
• カレントトランス
• センサ内に通した導線の交流電流を測定
• 導線の1/nの電流が流れる
• 抵抗で電圧に変換
• あまり大きく出来ない(10Ωとか)
• 線形でなくなる
→10 [mV/A]くらいの出力
→増幅しないとADC辛い…](https://image.slidesharecdn.com/psoc4ble-160917111512/85/PSoC4-BLE-8-320.jpg)








![カスタムサービスの定義
PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17 24
カスタムサービス
(Current Sensing Service)
•Current Sensing Service
• 2つのキャラクタリスティック
• Current
• センサの生の測定値
• Coefficient
• センサ測定値を[A]単位に変換するための係数
• PSoC4 BLEにはFPUが無いのでセントラル側で変換](https://image.slidesharecdn.com/psoc4ble-160917111512/85/PSoC4-BLE-24-320.jpg)

![消費電力の削減
PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17 26
•電源:CR2032
• 定格容量 220[mAh]
•目標:1ヶ月連続動作
• 24[h]*30[d] = 720[h]
• 220[mAh]/720[h] ≒ 0.31[mA]
→平均消費電流 0.31[mA]以下](https://image.slidesharecdn.com/psoc4ble-160917111512/85/PSoC4-BLE-26-320.jpg)
![消費電力の削減
PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17 27
•極力寝る
• =CPU、周辺回路を止める (DEEP SLEEP)
•3つのクロック
• ECO:BLE用 外部水晶発振子(24[MHz])
• IMO:内蔵発振回路(48[MHz]) CPU用
• WCO:外部水晶発振子(32.768[kHz])
→BLE、CPUを極力止める](https://image.slidesharecdn.com/psoc4ble-160917111512/85/PSoC4-BLE-27-320.jpg)
![BLEの通信間隔
PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17 28
•BLE通信
• CPU+BLE回路が必要
• かなり消費電流大きい
• 定常5[mA]、ピーク~20[mA]
• 極力通信しない
→通信パラメータで1[s]間隔に設定
Connection interval](https://image.slidesharecdn.com/psoc4ble-160917111512/85/PSoC4-BLE-28-320.jpg)
![BLE通信時の電流波形
PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17 29
•簡易電流プローブ
• 10[mV]=1[mA]
•ピーク18[mA]
•積分値26.3[uAs]](https://image.slidesharecdn.com/psoc4ble-160917111512/85/PSoC4-BLE-29-320.jpg)
![交流電流の測定
PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17 30
• 3.2[kSPS]、64点
• 50[Hz]の1周期分
• CPU+ADC
• IMO(48[MHz])が必要
• ADCが終われば寝られる
• 1/3.2[ms]で割り込み
• WDT使用
• DEEP SLEEPからタイマ割り込みでは
起きられない
→BLE同様1[s]間隔で測定
20[ms]](https://image.slidesharecdn.com/psoc4ble-160917111512/85/PSoC4-BLE-30-320.jpg)
![交流電流計測時の電流波形
PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17 31
•3.2[kSPS]、64点
• 50[Hz]の1周期分
•ピーク5.3[mA]
•積分値33.8[uAs]](https://image.slidesharecdn.com/psoc4ble-160917111512/85/PSoC4-BLE-31-320.jpg)

![BLE通信時の注意点
PSoC4 BLEで作る簡単無線センサーユニット 2016/9/17 33
•計測後に無駄な時間
• CPU+BLEが起きたまま
• 積分値:258[uAs]
•ADCタイミング依存
• 場合によりもっと増える
• 5[mAs]とか
計測 無駄
計測結果送信要求
BLE起動
BLE送信
タイミング](https://image.slidesharecdn.com/psoc4ble-160917111512/85/PSoC4-BLE-33-320.jpg)






































