Download to read offline


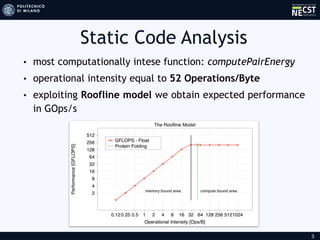



This document discusses hardware acceleration through profiling code to find bottlenecks, implementing the bottleneck function in hardware using Vivado HLS, and optimizing the implementation through loop pipelining, reduction, and memory access. The most computationally intensive function was found to be computePairEnergy. Hardware implementation and optimizations allowed for exploiting the Roofline model to achieve expected performance gains in implementing the bottleneck function in hardware.













![Bootstrapping a ML platform at Bluevine [Airflow Summit 2020]](https://cdn.slidesharecdn.com/ss_thumbnails/airflowsummit20201-200716055944-thumbnail.jpg?width=640&height=640&fit=bounds)































































