Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
cyberagent
PDF, PPTX
1,717 views
Presto on YARNの導入・運用
2017/12/22(金)開催 「Data Engineering and Data Analysis Workshop #3」登壇資料
Technology
◦
Read more
5
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 31
2
/ 31
3
/ 31
4
/ 31
5
/ 31
6
/ 31
7
/ 31
8
/ 31
9
/ 31
10
/ 31
11
/ 31
12
/ 31
13
/ 31
14
/ 31
15
/ 31
16
/ 31
17
/ 31
18
/ 31
19
/ 31
20
/ 31
21
/ 31
22
/ 31
23
/ 31
24
/ 31
25
/ 31
26
/ 31
27
/ 31
28
/ 31
29
/ 31
30
/ 31
31
/ 31
More Related Content
PDF
Hadoop入門
by
Preferred Networks
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PDF
NetflixにおけるPresto/Spark活用事例
by
Amazon Web Services Japan
PPTX
はじめてのElasticsearchクラスタ
by
Satoyuki Tsukano
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
PPTX
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
Hadoop入門
by
Preferred Networks
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
NetflixにおけるPresto/Spark活用事例
by
Amazon Web Services Japan
はじめてのElasticsearchクラスタ
by
Satoyuki Tsukano
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
What's hot
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
PDF
KafkaとAWS Kinesisの比較
by
Yoshiyasu SAEKI
PDF
Hive on Tezのベストプラクティス
by
Yahoo!デベロッパーネットワーク
PDF
AWSのログ管理ベストプラクティス
by
Akihiro Kuwano
PDF
Cassandra導入事例と現場視点での苦労したポイント cassandra summit2014jpn
by
haketa
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PDF
HDFSのスケーラビリティの限界を突破するためのさまざまな取り組み | Hadoop / Spark Conference Japan 2019 #hc...
by
Yahoo!デベロッパーネットワーク
PDF
Apache Bigtop3.2 (仮)(Open Source Conference 2022 Online/Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
PPTX
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
PDF
Data platformdesign
by
Ryoma Nagata
PDF
MapReduce/YARNの仕組みを知る
by
日本ヒューレット・パッカード株式会社
PPTX
コンテナネットワーキング(CNI)最前線
by
Motonori Shindo
PPTX
DockerコンテナでGitを使う
by
Kazuhiro Suga
PDF
ビッグデータ処理データベースの全体像と使い分け
by
Recruit Technologies
PDF
噛み砕いてKafka Streams #kafkajp
by
Yahoo!デベロッパーネットワーク
PDF
爆速クエリエンジン”Presto”を使いたくなる話
by
Kentaro Yoshida
PDF
Apache Sparkにおけるメモリ - アプリケーションを落とさないメモリ設計手法 -
by
Yoshiyasu SAEKI
PDF
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス
by
Amazon Web Services Japan
PDF
Apache Kafka 0.11 の Exactly Once Semantics
by
Yoshiyasu SAEKI
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
KafkaとAWS Kinesisの比較
by
Yoshiyasu SAEKI
Hive on Tezのベストプラクティス
by
Yahoo!デベロッパーネットワーク
AWSのログ管理ベストプラクティス
by
Akihiro Kuwano
Cassandra導入事例と現場視点での苦労したポイント cassandra summit2014jpn
by
haketa
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
HDFSのスケーラビリティの限界を突破するためのさまざまな取り組み | Hadoop / Spark Conference Japan 2019 #hc...
by
Yahoo!デベロッパーネットワーク
Apache Bigtop3.2 (仮)(Open Source Conference 2022 Online/Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
Data platformdesign
by
Ryoma Nagata
MapReduce/YARNの仕組みを知る
by
日本ヒューレット・パッカード株式会社
コンテナネットワーキング(CNI)最前線
by
Motonori Shindo
DockerコンテナでGitを使う
by
Kazuhiro Suga
ビッグデータ処理データベースの全体像と使い分け
by
Recruit Technologies
噛み砕いてKafka Streams #kafkajp
by
Yahoo!デベロッパーネットワーク
爆速クエリエンジン”Presto”を使いたくなる話
by
Kentaro Yoshida
Apache Sparkにおけるメモリ - アプリケーションを落とさないメモリ設計手法 -
by
Yoshiyasu SAEKI
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス
by
Amazon Web Services Japan
Apache Kafka 0.11 の Exactly Once Semantics
by
Yoshiyasu SAEKI
Similar to Presto on YARNの導入・運用
PDF
僕とヤフーと時々Teradata #prestodb
by
Yahoo!デベロッパーネットワーク
PDF
Presto in Yahoo! JAPAN #yjdsnight
by
Yahoo!デベロッパーネットワーク
PPTX
Service Fabric での高密度配置
by
Takekazu Omi
PDF
AWS で Presto を徹底的に使いこなすワザ
by
Noritaka Sekiyama
PDF
最新版Hadoopクラスタを運用して得られたもの
by
cyberagent
PDF
Start of a New era: Apache YARN 3.1 and Apache HBase 2.0
by
DataWorks Summit
PDF
Apache Hadoop and YARN, current development status
by
NTT DATA OSS Professional Services
PPTX
ノンコーディング・超高速のApi 開発・運用基盤「cdata api server」のご紹介
by
CData Software Japan
PDF
Spring3.1概要x di
by
Yuichi Hasegawa
PDF
20120423 hbase勉強会
by
Toshiaki Toyama
PDF
Apache Big Data Miami 2017 - Hadoop Source Code Reading #23 #hadoopreading
by
Yahoo!デベロッパーネットワーク
PDF
Prestoで実現するインタラクティブクエリ - dbtech showcase 2014 Tokyo
by
Treasure Data, Inc.
PDF
[db tech showcase Tokyo 2014] D33: Prestoで実現するインタラクティブクエリ by トレジャーデータ株式会社 斉藤太郎
by
Insight Technology, Inc.
PPTX
JSUG SpringOnePlatform 2016報告会 Case study2 - feed back - springoneplatform
by
Takahiro Fujii
PPTX
The future of Apache Hadoop YARN
by
Seiya Mizuno
PDF
クラウド開発に役立つ OSS あれこれ
by
Masataka MIZUNO
PPTX
20170510 タウンwi fixlifull_スマホアプリ開発の実例 (1)
by
LIFULL Co., Ltd.
PDF
Pyramid入門
by
Atsushi Odagiri
PDF
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall
by
Shinpei Ohtani
PPTX
Parquetはカラムナなのか?
by
Yohei Azekatsu
僕とヤフーと時々Teradata #prestodb
by
Yahoo!デベロッパーネットワーク
Presto in Yahoo! JAPAN #yjdsnight
by
Yahoo!デベロッパーネットワーク
Service Fabric での高密度配置
by
Takekazu Omi
AWS で Presto を徹底的に使いこなすワザ
by
Noritaka Sekiyama
最新版Hadoopクラスタを運用して得られたもの
by
cyberagent
Start of a New era: Apache YARN 3.1 and Apache HBase 2.0
by
DataWorks Summit
Apache Hadoop and YARN, current development status
by
NTT DATA OSS Professional Services
ノンコーディング・超高速のApi 開発・運用基盤「cdata api server」のご紹介
by
CData Software Japan
Spring3.1概要x di
by
Yuichi Hasegawa
20120423 hbase勉強会
by
Toshiaki Toyama
Apache Big Data Miami 2017 - Hadoop Source Code Reading #23 #hadoopreading
by
Yahoo!デベロッパーネットワーク
Prestoで実現するインタラクティブクエリ - dbtech showcase 2014 Tokyo
by
Treasure Data, Inc.
[db tech showcase Tokyo 2014] D33: Prestoで実現するインタラクティブクエリ by トレジャーデータ株式会社 斉藤太郎
by
Insight Technology, Inc.
JSUG SpringOnePlatform 2016報告会 Case study2 - feed back - springoneplatform
by
Takahiro Fujii
The future of Apache Hadoop YARN
by
Seiya Mizuno
クラウド開発に役立つ OSS あれこれ
by
Masataka MIZUNO
20170510 タウンwi fixlifull_スマホアプリ開発の実例 (1)
by
LIFULL Co., Ltd.
Pyramid入門
by
Atsushi Odagiri
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall
by
Shinpei Ohtani
Parquetはカラムナなのか?
by
Yohei Azekatsu
More from cyberagent
PDF
WWW2019で見るモバイルコンピューティングの技術と動向 山本悠ニ
by
cyberagent
PDF
Web フィルタリング最前線: 「「検閲回避」回避」 角田孝昭
by
cyberagent
PDF
WebにおけるHuman Dynamics 武内慎
by
cyberagent
PDF
Webと経済学 數見拓朗
by
cyberagent
PDF
Data Engineering Meetup #1 持続可能なデータ基盤のためのデータの多様性に対する取り組み
by
cyberagent
PDF
継続的な開発スタイル AbemaTVのiOSアプリを週1でリリースしている話
by
cyberagent
PDF
AbemaTVにおける推薦システム
by
cyberagent
PDF
AbemaTV レコメンド開発エンジニアによる RecSys 2018 参加レポート
by
cyberagent
PDF
機械学習エンジニアを見せたAWSの再:発明とは? 〜re:Invent 2018 参加レポート〜
by
cyberagent
PPTX
インターネットテレビ局「AbemaTV」プロダクトの変遷
by
cyberagent
PDF
番組宣伝に関するAbemaTV分析事例の紹介
by
cyberagent
PDF
WWW2018 論文読み会 Webと経済学
by
cyberagent
PDF
WWW2018 論文読み会 WebにおけるHuman Dynamics
by
cyberagent
PDF
WWW2018 論文読み会 Web Search and Mining
by
cyberagent
PDF
サイバーエージェントの機械学習エンジニアが体験したGoogle I/O 2018
by
cyberagent
PDF
ログ解析基盤におけるストリーム処理パイプラインについて
by
cyberagent
PDF
Orion an integrated multimedia content moderation system for web services
by
cyberagent
PDF
Orion an integrated multimedia content moderation system for web services
by
cyberagent
PDF
「これ危ない設定じゃないでしょうか」とヒアリングするための仕組み @AWS Summit Tokyo 2018
by
cyberagent
PPTX
"マルチメディア機械学習" の取り組み
by
cyberagent
WWW2019で見るモバイルコンピューティングの技術と動向 山本悠ニ
by
cyberagent
Web フィルタリング最前線: 「「検閲回避」回避」 角田孝昭
by
cyberagent
WebにおけるHuman Dynamics 武内慎
by
cyberagent
Webと経済学 數見拓朗
by
cyberagent
Data Engineering Meetup #1 持続可能なデータ基盤のためのデータの多様性に対する取り組み
by
cyberagent
継続的な開発スタイル AbemaTVのiOSアプリを週1でリリースしている話
by
cyberagent
AbemaTVにおける推薦システム
by
cyberagent
AbemaTV レコメンド開発エンジニアによる RecSys 2018 参加レポート
by
cyberagent
機械学習エンジニアを見せたAWSの再:発明とは? 〜re:Invent 2018 参加レポート〜
by
cyberagent
インターネットテレビ局「AbemaTV」プロダクトの変遷
by
cyberagent
番組宣伝に関するAbemaTV分析事例の紹介
by
cyberagent
WWW2018 論文読み会 Webと経済学
by
cyberagent
WWW2018 論文読み会 WebにおけるHuman Dynamics
by
cyberagent
WWW2018 論文読み会 Web Search and Mining
by
cyberagent
サイバーエージェントの機械学習エンジニアが体験したGoogle I/O 2018
by
cyberagent
ログ解析基盤におけるストリーム処理パイプラインについて
by
cyberagent
Orion an integrated multimedia content moderation system for web services
by
cyberagent
Orion an integrated multimedia content moderation system for web services
by
cyberagent
「これ危ない設定じゃないでしょうか」とヒアリングするための仕組み @AWS Summit Tokyo 2018
by
cyberagent
"マルチメディア機械学習" の取り組み
by
cyberagent
Recently uploaded
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
Presto on YARNの導入・運用
1.
2017 Dec 22 CyberAgent,
Inc. All Rights Reserved Presto on YARNの導入・運用
2.
飯島 賢志 ● 2012年3月入社 ● 技術本部 秋葉原ラボ ●
データ解析基盤Patriotまわりの開発・運用 ● 運用してきたOSS ○ Hadoop, Spark, Presto, Hive, HBase, Flume, Ignite, Zeppelin, Elasticsearch etc... 自己紹介
3.
● データ解析基盤Patriotの紹介 ● Presto
on YARN ○ 概要 ○ 構成要素 (Presto, Slider) ○ 導入・設定 ○ 運用 ● 今回紹介しなかった取り組み 本日の内容
4.
● データ解析基盤Patriotの紹介 ● Presto
on YARN ○ 概要 ○ 構成要素 (Presto, Slider) ○ 導入・設定 ○ 運用 ● 今回紹介しなかった取り組み 本日の内容
5.
● Hadoopベースのデータ解析基盤 ○ HDFS,
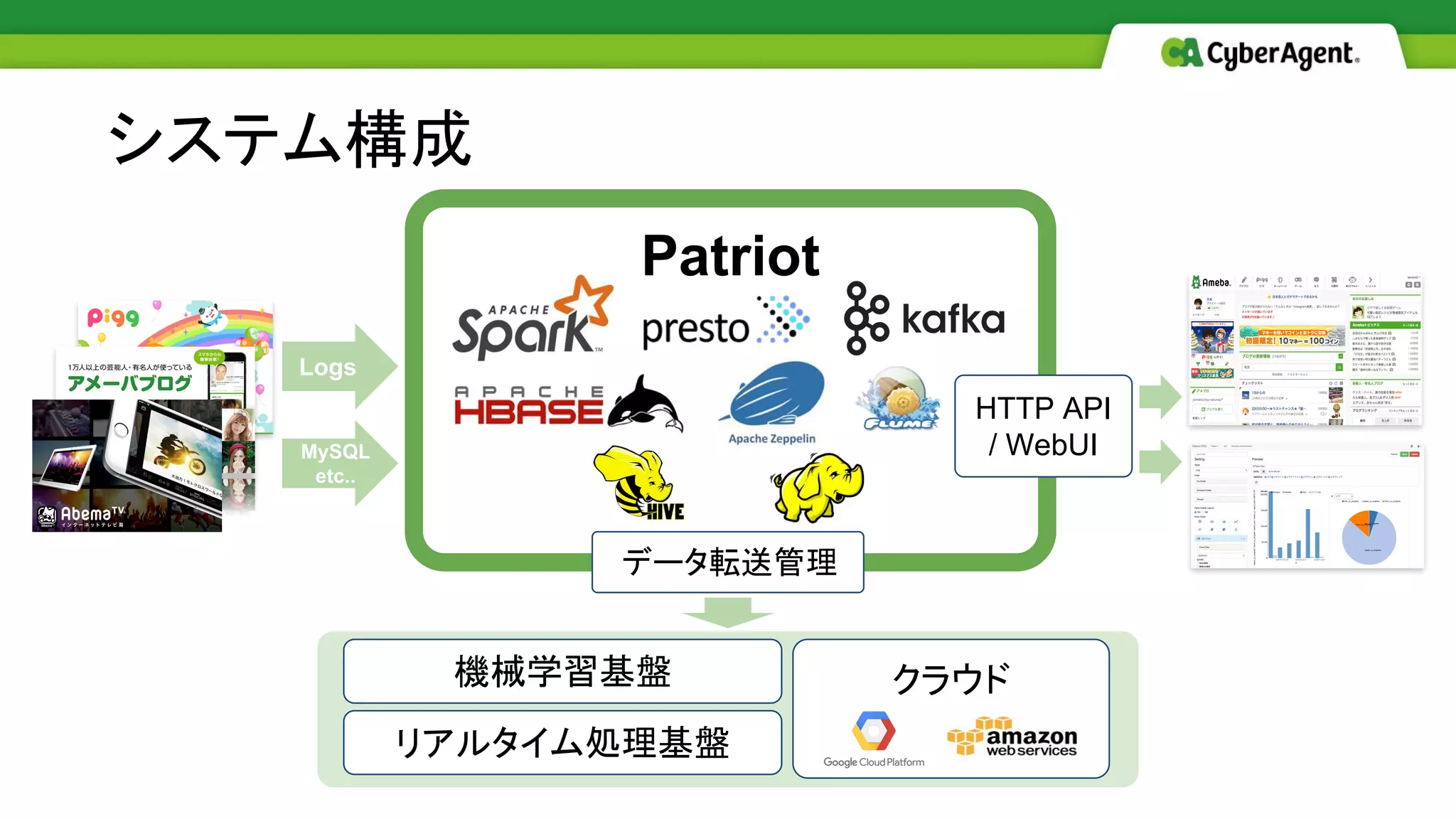
YARN, Hive, HBase, Flume, Spark, etc ○ Bigtopで内製化したパッケージを使用 ● メディアサービスのデータを集約 ○ 2.5 PB / 5.0 PB (3 replica) ■ 5〜7 TB / day ○ 約700テーブル、12,000,000パーティション ○ 6000スケジュールジョブ + アドホックジョブ データ解析基盤Patriot
6.
クラウド機械学習基盤 システム構成 Patriot データ転送管理 リアルタイム処理基盤 HTTP API / WebUIMySQL etc.. Logs
7.
● Hadoop 2.7.3
+ patch → 2.8.1 + patch ● Spark 2.1.0 + patch ● Hive 2.1.1 + patch ● HBase 1.3.0 → 1.3.1 + patch ● Zookeeper 3.4.6 ● Flume 1.8.0 (trunk) + patch ● Presto YARN 1.5 ○ Presto 0.179 + patch (kafka対応) → 0.190 ○ Slider 0.92.0 ● Kafka 0.11.0 ● Zeppelin 0.7.3 利用中のパッケージ New! New!
8.
● データ解析基盤Patriotの紹介 ● Presto
on YARN ○ 概要 ○ 構成要素 (Presto, Slider) ○ 導入・設定 ○ 運用 ● 今回紹介しなかった取り組み 本日の内容
9.
● Presto YARN
Integration ○ Prestoが入ったコンテナをYARN上で起動 ○ Patriotでは運用始めて5ヶ月 ○ "Presto YARN", "presto-yarn"ともいう ● セットアップ ○ GUI:Ambari Slider Views in HDP ○ 手動:Apache Slider ● Git ○ 最新:v1.5 ○ https://github.com/prestodb/presto-yarn Presto on YARN
10.
● YARNの上にのってるだけで動作はnativeなPrestoと同じ Architecture HDFS YARN Presto Coordinator Presto Worker : Presto Worker Presto Worker User
11.
● リソース管理 ○ Spark,
Hiveなど含めYARNで一元管理できる ● デプロイ ○ Ansibleなどで何十台に設定反映が不要 ○ コンテナの起動と同時にパッケージ配布するので アップグレードも容易 ● オペレーション ○ 一斉再起動が手軽にできる ● 自動再起動 ○ プロセスが落ちてもリトライする なぜ Presto YARN か
12.
● データ解析基盤Patriotの紹介 ● Presto
on YARN ○ 概要 ○ 構成要素 (Presto, Slider) ○ 導入・設定 ○ 運用 ● 今回紹介しなかった取り組み 本日の内容
13.
● Facebookが開発した分散SQLエンジ ン ●
インメモリ ○ 中間データをディスクに書かないので高速 ● コネクター ○ 色々な外部データソースに接続できる ■ e.g. Hive, Kafka, Accumulo, Cassandra ● バージョン ○ 最新 v0.191 Presto
14.
Apache Slider ● YARNに分散Applicationをデプロイできる ○
c.g. HBase, Storm, Accumulo ● HDPだと ○ Ambariから使う方が一般的 ● YARNに取り込まれた ○ YARN-4692 [Umbrella] Simplified and first-class support for services in YARN ○ YARN-5079 [Umbrella] Native YARN framework layer for services and beyond ○ Gitの階層だとココ hadoop-yarn-project > hadoop-yarn > hadoop-yarn-applications > hadoop-yarn-services > hadoop-yarn-services-core
15.
Slider Deploy App
Flow Slider Client ① Launch HDFS YARN Resource Manager② Container (Application Master) HDFS YARN Node Manager Slider App Master ③ Zookeeper YARN Service Registry ⑤ Container HDFS YARN Node Manager App Slider Agent : ④ Container HDFS YARN Node Manager App Slider Agent
16.
● データ解析基盤Patriotの紹介 ● Presto
on YARN ○ 概要・構成要素 (Presto, Slider) ○ 導入・設定 ○ 運用 ● 今回紹介しなかった取り組み 本日の内容
17.
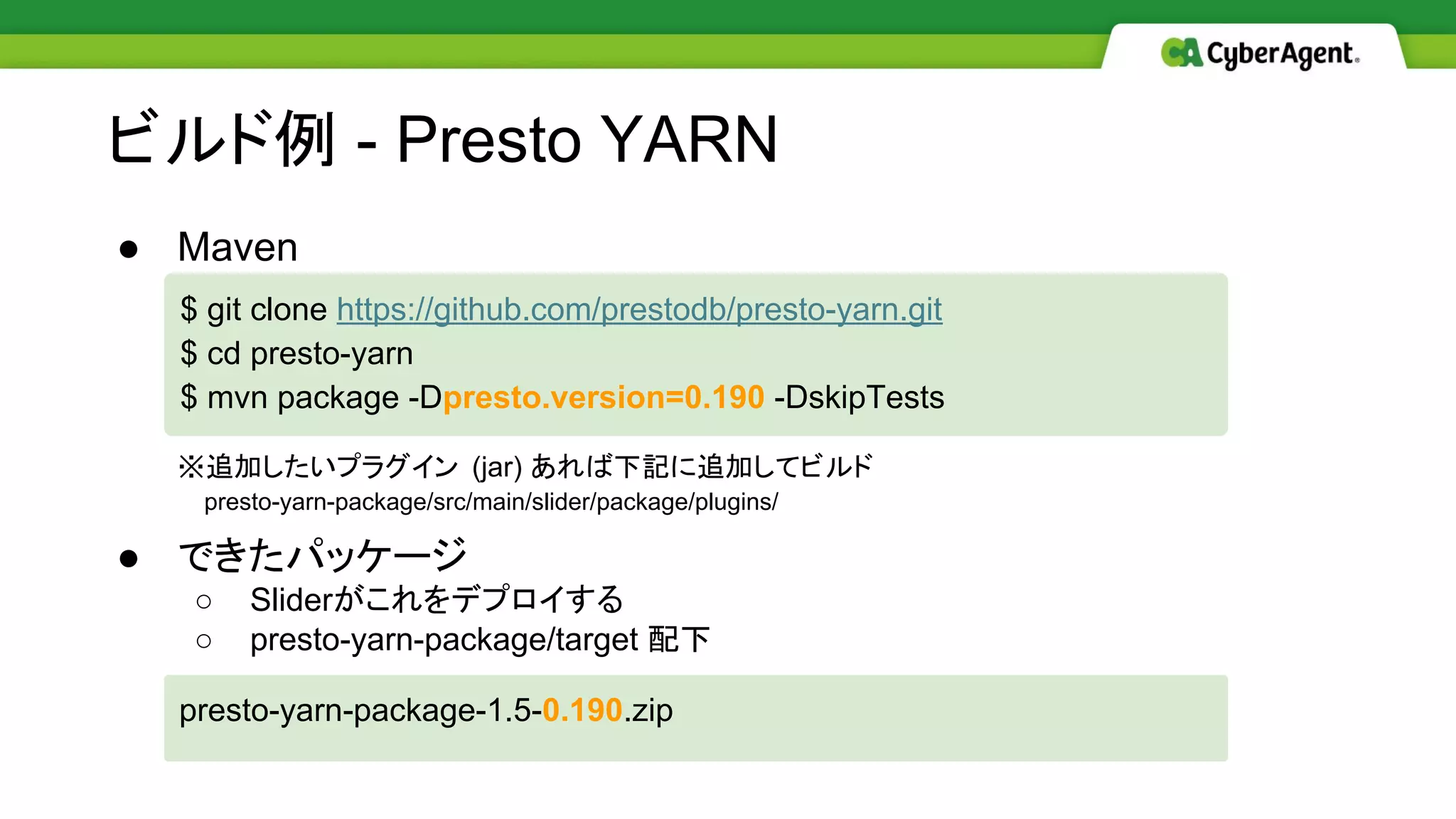
ビルド例 - Presto
YARN ● Maven ※追加したいプラグイン (jar) あれば下記に追加してビルド presto-yarn-package/src/main/slider/package/plugins/ ● できたパッケージ ○ Sliderがこれをデプロイする ○ presto-yarn-package/target 配下 $ git clone https://github.com/prestodb/presto-yarn.git $ cd presto-yarn $ mvn package -Dpresto.version=0.190 -DskipTests presto-yarn-package-1.5-0.190.zip
18.
● Slider applicationとして起動 起動
- Presto YARN $ slider package --install --name PRESTO --replacepkg --package presto-yarn-package-1.5-0.190.zip …… Slider clientの起動 (local) $ slider create presto-yarn --template appConfig.json --resources resources-multinode.json …………… Presto YARNの起動 (yarn) ※設定ファイルは後述
19.
● AppConfig.json 設定例 -
Presto YARN ………………………………… ラベル (インスタンスの種類) ……………………… 起動の順番 … 配置ポリシー (ANTI_AFFINITY) ………… インスタンス数 ………………………… コア数 …………………… メモリ(MB) "global": { "site.global.app_user": "yarn", "site.global.user_group": "hadoop", "site.global.data_dir": "/var/tmp/presto-yarn/data/", …………… ログなどのパス "site.global.config_dir": "/var/tmp/presto-yarn/conf/", ………… 設定ファイルのパス "site.global.app_name": "presto-server-0.190", "site.global.singlenode": "false", ………………………………… 1ホストに共存させるか "site.global.coordinator_host": "{{ coordinator.host }}", "site.global.presto_query_max_memory": "800G", …………… 1クエリの最大メモリ "site.global.presto_query_max_memory_per_node": "10G", … 1ノードの最大メモリ "site.global.presto_server_port": "9010", "site.global.jvm_args": "['-Xmx20G', … ]", ……………………… JVM設定 :
20.
● AppConfig.json (続き) 設定例
- Presto YARN "global": { : "site.global.catalog ": "{'hive': ['hive.metastore.uri= … ]}", ………… カタログ設定 "site.global.plugin": "{'patriot': ['patriot-udf.jar', … ]}", ………………… 追加するプラグイン "site.global.app_pkg_plugin": "${AGENT_WORK_ROOT} …/plugins", …… プラグインのコピー元 "site.global.log_properties": "['com.facebook.presto=INFO', … ]", ……………………………… ログレベル "site.global.additional_config_properties": "['query.max-run-time=15m', … ]", …………………………………… プロパティ設定 "application.def": ".slider/package/PRESTO/presto-yarn-package-1.5-0.190.zip", … 展開するパッケージ "java_home": "/usr/java/latest" },
21.
● resources-multinode.json "global": { "yarn.container.failure.threshold"
: "0" ……… 失敗のリトライ回数 (無制限) }, "components": { "COORDINATOR": { ………………………… ラベル (インスタンス種類) "yarn.role.priority": "1", ……………………… 起動の順番 "yarn.component.placement.policy": "4", … 配置ポリシー (ANTI_AFFINITY) "yarn.component.instances": "1", ………… インスタンス数 "yarn.vcores": "8", …………………………… コア数 "yarn.memory": "20480" …………………… メモリ(MB) }, : 設定例 - Presto YARN
22.
● resources-multinode.json (続き) : "components":
{ : "WORKER": { ………………………………… ラベル (インスタンス種類) "yarn.role.priority": "2", ……………………… 起動の順番 "yarn.component.placement.policy": "4", … 配置ポリシー (ANTI_AFFINITY) "yarn.component.instances": "84", ………… インスタンス数 "yarn.vcores": "16", ………………………… コア数 "yarn.memory": "20480" …………………… メモリ(MB) } } 設定例 - Presto YARN
23.
● slider-site.xml ※別途 YARN
service registry 設定 (yarn-site.xml) も必要 設定例 - Slider ………………………………… ラベル (インスタンスの種類) ……………………… 起動の順番 … 配置ポリシー (ANTI_AFFINITY) ………… インスタンス数 ………………………… コア数 …………………… メモリ(MB) <configuration> <property> <name>yarn.resourcemanager.address</name> … ResourceManagerのホスト <value>{{ resouceManager.host }}:8088</value> </property> <property> <name>slider.zookeeper.quorum</name> ………… YARN Service RegistryのZookeeper <value>{{ zookeeper.host1 }}:2181, ...</value> </property> </configuration>
24.
● データ解析基盤Patriotの紹介 ● Presto
on YARN ○ 概要・構成要素 (Presto, Slider) ○ 導入・設定 ○ 運用 ● 今回紹介しなかった取り組み 本日の内容
25.
● Slider should
not allow to allocate twice containers on the same node ○ placement: ANTI_AFFINITYにしても解決せず ■ 現象: CoordinatorとWorkerを同じホストで起動しようとして どちらかがエラーになる ■ 対応: CoordinatorだけPresto YARNとは別立てにした Workaround https://github.com/prestodb/presto-yarn/issues/22
26.
カラムナーフォーマット ● Apache ORC ○
カラムの統計をもちIndexに利用 ■ count, min, max, sum… ○ Spark 2.3.0でHive依存のORCから脱却 ※SPARK-20682 ● Apache Parquet ○ ネスト構造を効率よく扱える ○ 実はIndex headerが実装されてない (昔からRoadMapにはある) https://github.com/apache/parquet-format/blob/master/src/main/thrift/parquet.thrift#L505-L507 ORC fileの構造
27.
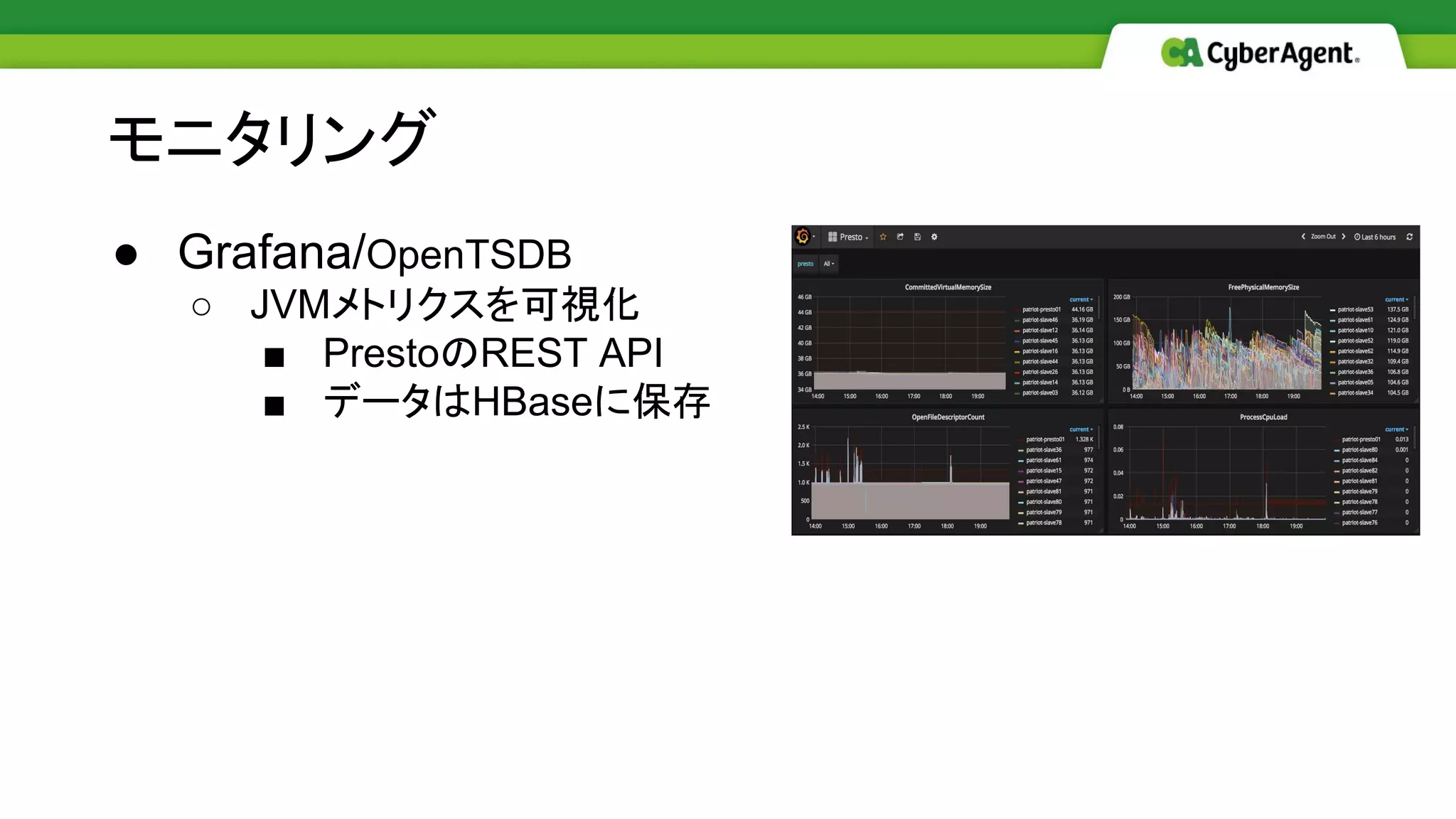
● Grafana/OpenTSDB ○ JVMメトリクスを可視化 ■
PrestoのREST API ■ データはHBaseに保存 モニタリング
28.
● 利用者を広げる ● 利用状況の統計などもっと取る ○
System Connector ● 稀に一部Workerが動かなくなる事象 ○ チューニングして解消した(?) ■ https://github.com/prestodb/presto/issues/4292 ● exchange.http-client.request-timeout=120sなど ○ 引き続き確認 今後のタスク
29.
● データ解析基盤Patriotの紹介 ● Presto
on YARN ○ 概要・構成要素 (Presto, Slider) ○ 導入・設定 ○ 運用 ● 今回紹介しなかった取り組み 本日の内容
30.
今回紹介しなかった取り組み ● Kudu ○ Fast
Data 処理向けに検証中 ● Zeppelin ○ Sparkなど分散処理環境へのアクセシビリティ向上 ○ 解析方法・結果の共有を容易に ● TensorFlow ○ GPUマシン環境 ○ Hadoop環境 - TensorFlow on Spark
31.
● Kafka ○ ストリーム処理のハブとして ●
Hadoopクラスタ管理ツールの開発 ○ 各プロセスの開始・停止、Rolling Restart/Upgrade ○ Zookeeper経由でGitと連携し設定変更など ● Prometeus ○ 監視まわりの置き換えで検証中 今回紹介しなかった取り組み
Download











![Apache Slider
● YARNに分散Applicationをデプロイできる
○ c.g. HBase, Storm, Accumulo
● HDPだと
○ Ambariから使う方が一般的
● YARNに取り込まれた
○ YARN-4692 [Umbrella] Simplified and first-class support for services in YARN
○ YARN-5079 [Umbrella] Native YARN framework layer for services and beyond
○ Gitの階層だとココ
hadoop-yarn-project > hadoop-yarn > hadoop-yarn-applications >
hadoop-yarn-services > hadoop-yarn-services-core](https://image.slidesharecdn.com/20171222labworkshopiijima-171226073251/75/Presto-on-YARN-14-2048.jpg)



![● AppConfig.json
設定例 - Presto YARN
………………………………… ラベル (インスタンスの種類)
……………………… 起動の順番
… 配置ポリシー (ANTI_AFFINITY)
………… インスタンス数
………………………… コア数
…………………… メモリ(MB)
"global": {
"site.global.app_user": "yarn",
"site.global.user_group": "hadoop",
"site.global.data_dir": "/var/tmp/presto-yarn/data/", …………… ログなどのパス
"site.global.config_dir": "/var/tmp/presto-yarn/conf/", ………… 設定ファイルのパス
"site.global.app_name": "presto-server-0.190",
"site.global.singlenode": "false", ………………………………… 1ホストに共存させるか
"site.global.coordinator_host": "{{ coordinator.host }}",
"site.global.presto_query_max_memory": "800G", …………… 1クエリの最大メモリ
"site.global.presto_query_max_memory_per_node": "10G", … 1ノードの最大メモリ
"site.global.presto_server_port": "9010",
"site.global.jvm_args": "['-Xmx20G', … ]", ……………………… JVM設定
:](https://image.slidesharecdn.com/20171222labworkshopiijima-171226073251/75/Presto-on-YARN-19-2048.jpg)
![● AppConfig.json (続き)
設定例 - Presto YARN
"global": {
:
"site.global.catalog ": "{'hive': ['hive.metastore.uri= … ]}", ………… カタログ設定
"site.global.plugin": "{'patriot': ['patriot-udf.jar', … ]}", ………………… 追加するプラグイン
"site.global.app_pkg_plugin": "${AGENT_WORK_ROOT} …/plugins", …… プラグインのコピー元
"site.global.log_properties":
"['com.facebook.presto=INFO', … ]", ……………………………… ログレベル
"site.global.additional_config_properties":
"['query.max-run-time=15m', … ]", …………………………………… プロパティ設定
"application.def":
".slider/package/PRESTO/presto-yarn-package-1.5-0.190.zip", … 展開するパッケージ
"java_home": "/usr/java/latest"
},](https://image.slidesharecdn.com/20171222labworkshopiijima-171226073251/75/Presto-on-YARN-20-2048.jpg)





































![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)













![[db tech showcase Tokyo 2014] D33: Prestoで実現するインタラクティブクエリ by トレジャーデータ株式会社 斉藤太郎](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014d33presto-141120012543-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
































