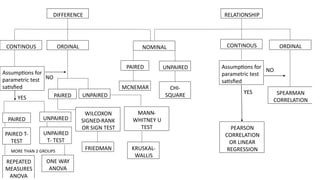
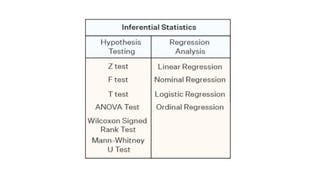
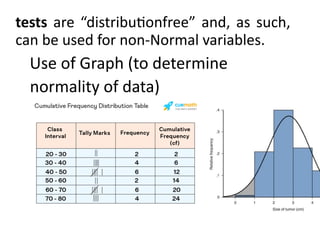
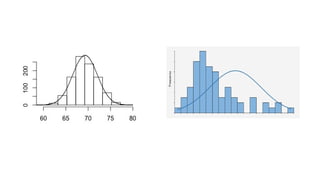
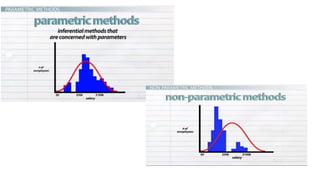
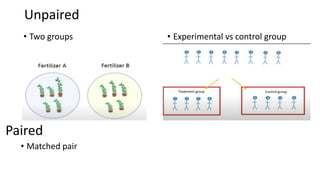
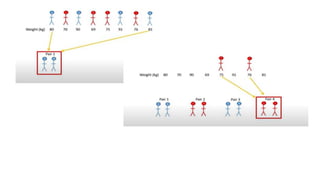
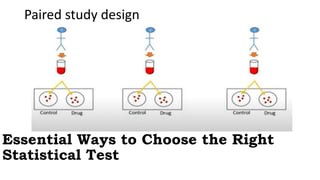
The document provides an overview of statistical tools and methods, including the concepts of data collection, descriptive and inferential statistics, and the selection of appropriate statistical tests based on research questions and data types. It elaborates on measures of central tendency and variability, as well as the differences between parametric and non-parametric tests. Additionally, it emphasizes the importance of representative sampling techniques and formulating null hypotheses in statistical analysis.