Download to read offline



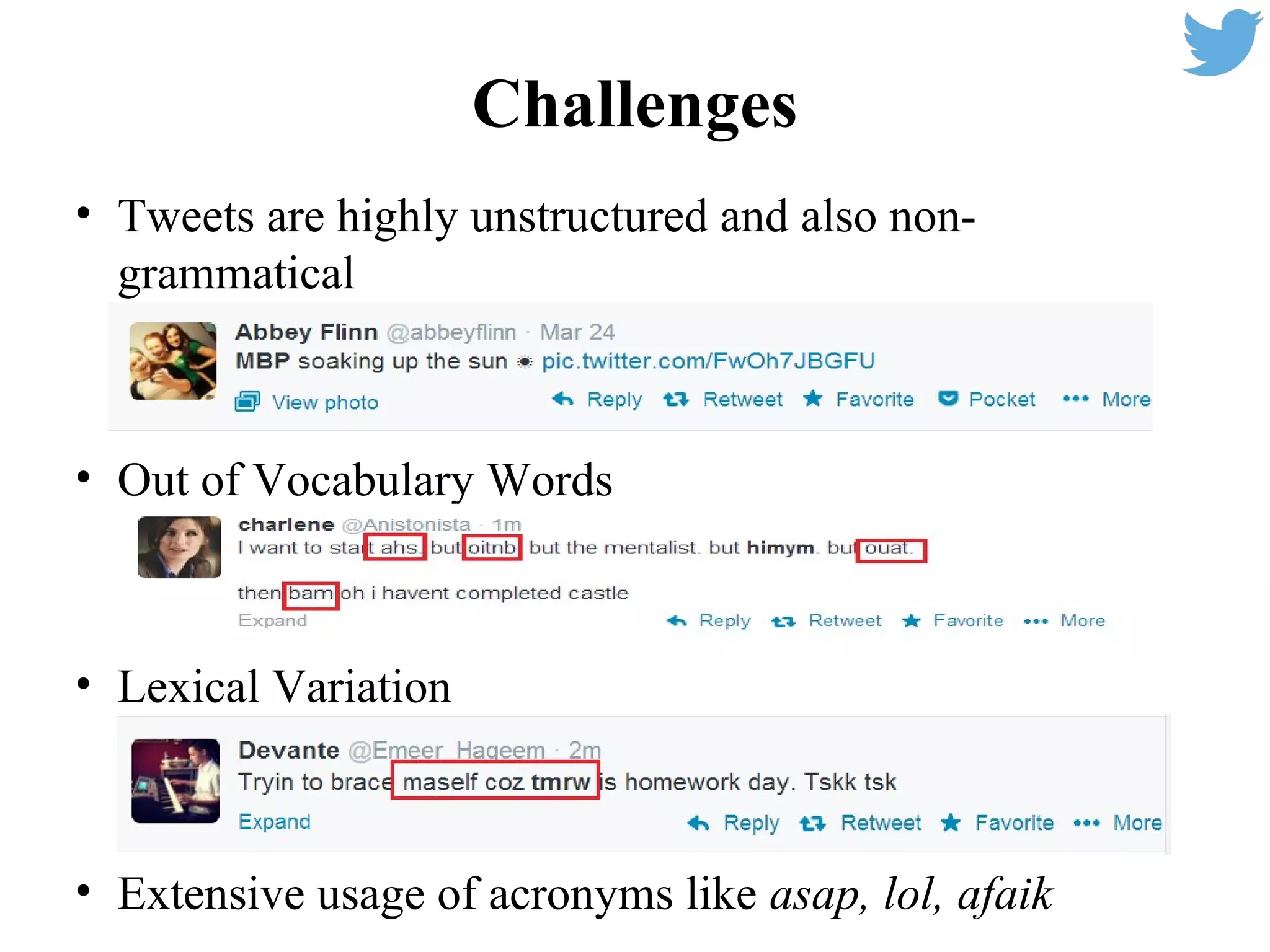
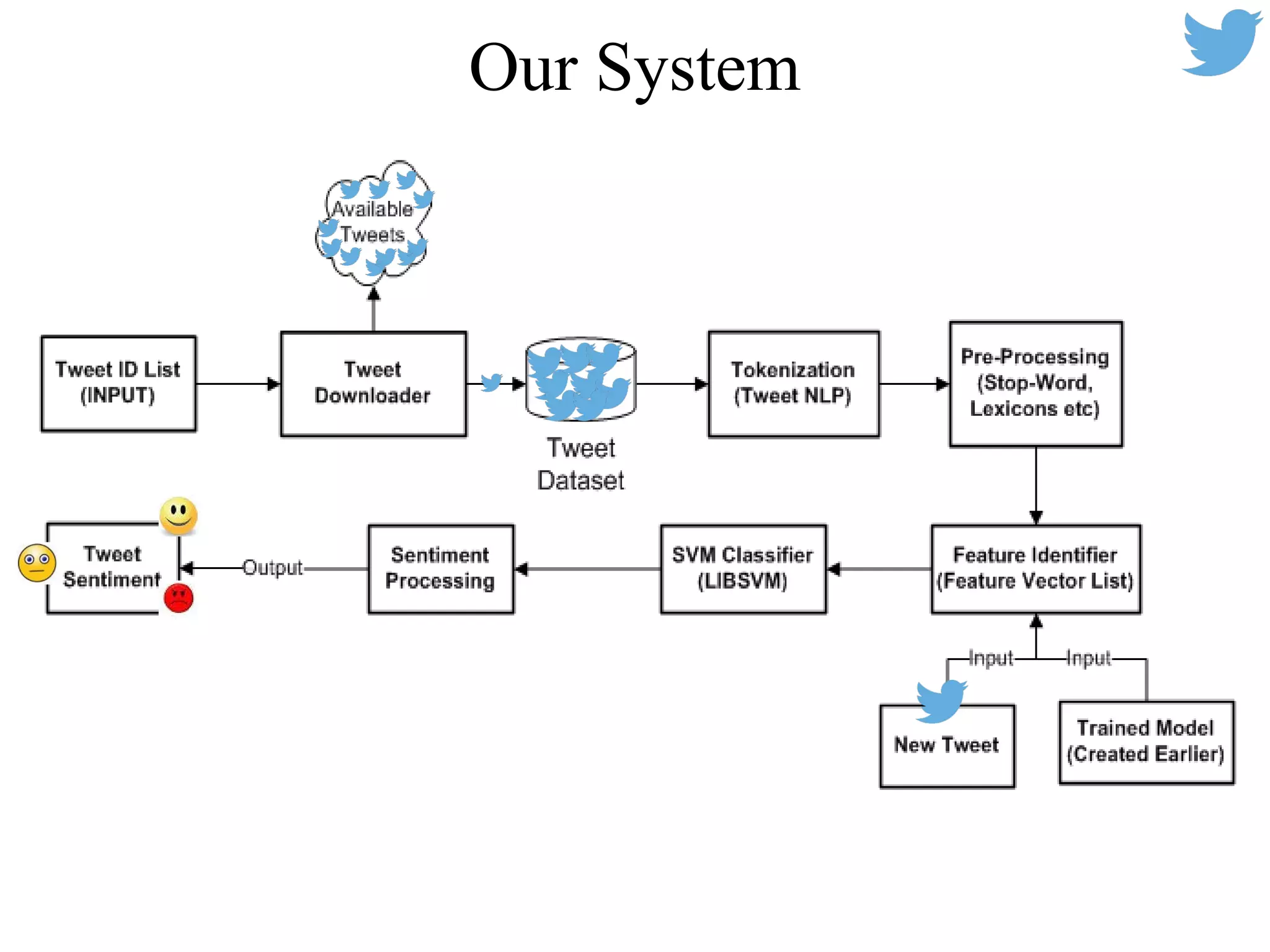





This document summarizes work on sentiment analysis for Twitter data. It outlines the challenges of analyzing tweets, which are informal and use slang. The described system downloads tweets, preprocesses them by handling emoticons, hashtags, URLs and repeated characters. It then extracts unigram and bigram features, polarity scores of words and emoticons, and feeds these into an SVM classifier to predict sentiment. Evaluating on a sentence-level task, the system using these features achieved an F1 score of 61.17%, outperforming a baseline model using only unigrams.

































