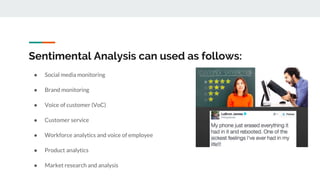
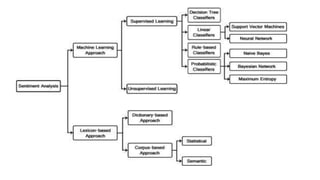
This document discusses sentiment analysis, particularly in the context of triple talaq, an Islamic divorce practice in India, and uses Twitter data from 2002 to 2019 to analyze public sentiment on the topic. It employs natural language processing and machine learning techniques, specifically utilizing lexicon-based approaches through APIs like TextBlob and SpaCy, to categorize sentiments as positive, negative, or neutral. The paper outlines the process of sentiment analysis and highlights its applications, advantages, and step-by-step methodologies involved.








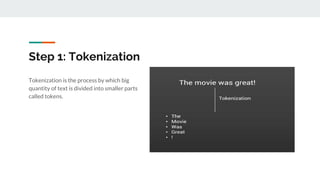





![What is TextBlob?
TextBlob is a python library and offers a simple API to access its methods and perform basic
NLP tasks.
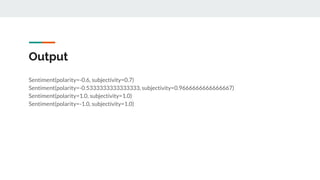
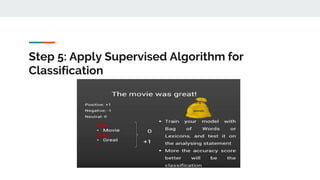
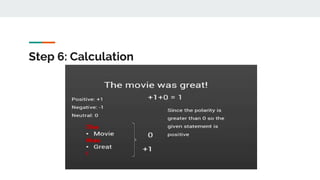
The sentiment function of textblob returns two properties, polarity, and subjectivity.
Polarity is float which lies in the range of [-1,1] where 1 means positive statement and -1 means
a negative statement. Subjective sentences generally refer to personal opinion, emotion or
judgment whereas objective refers to factual information. Subjectivity is also a float which lies
in the range of [0,1].](https://image.slidesharecdn.com/sentimentanalysis-230828123907-eb6f66d8/85/Sentiment-Analysis-using-Machine-Learning-pdf-23-320.jpg)