Downloaded 59 times

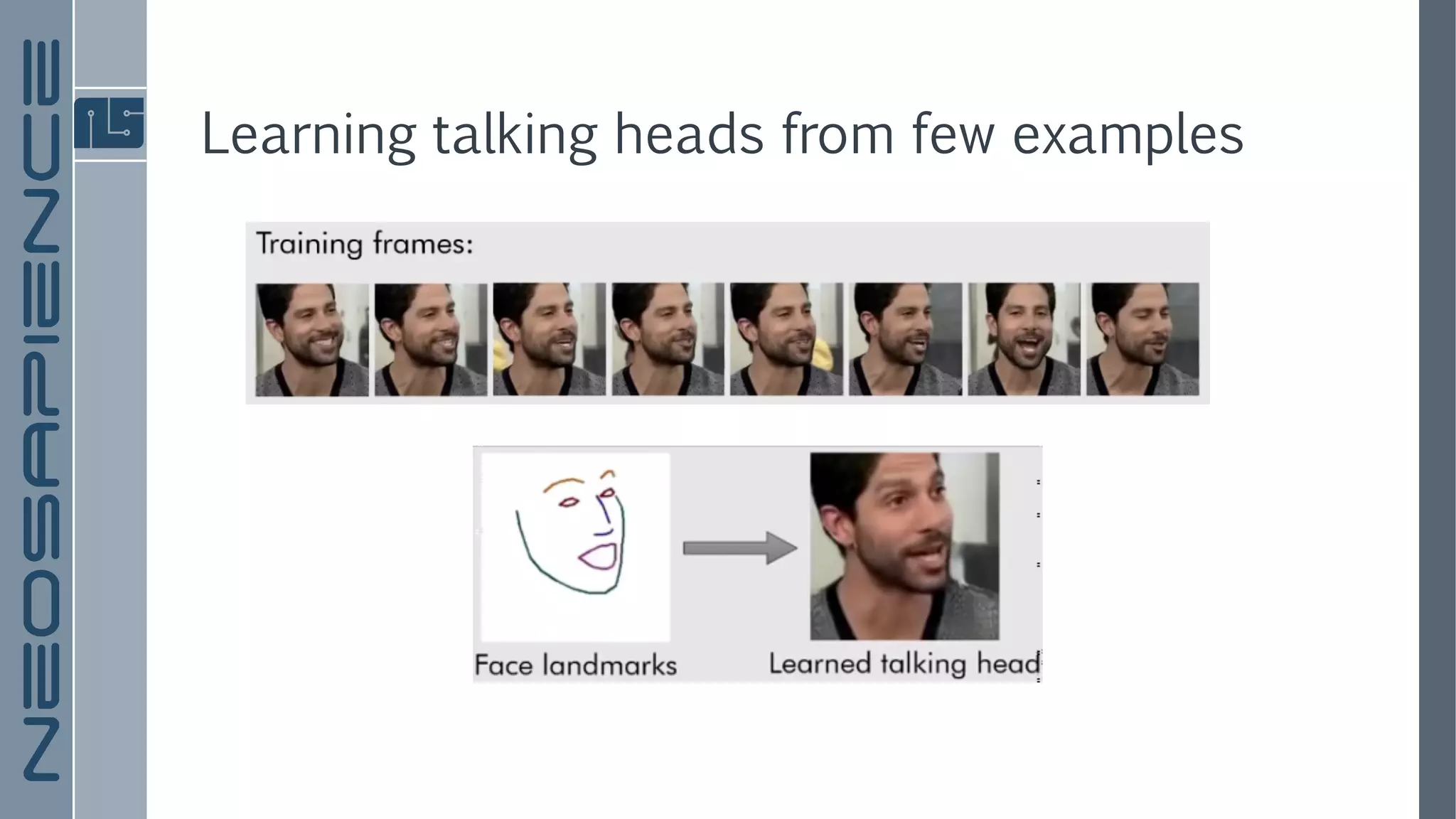
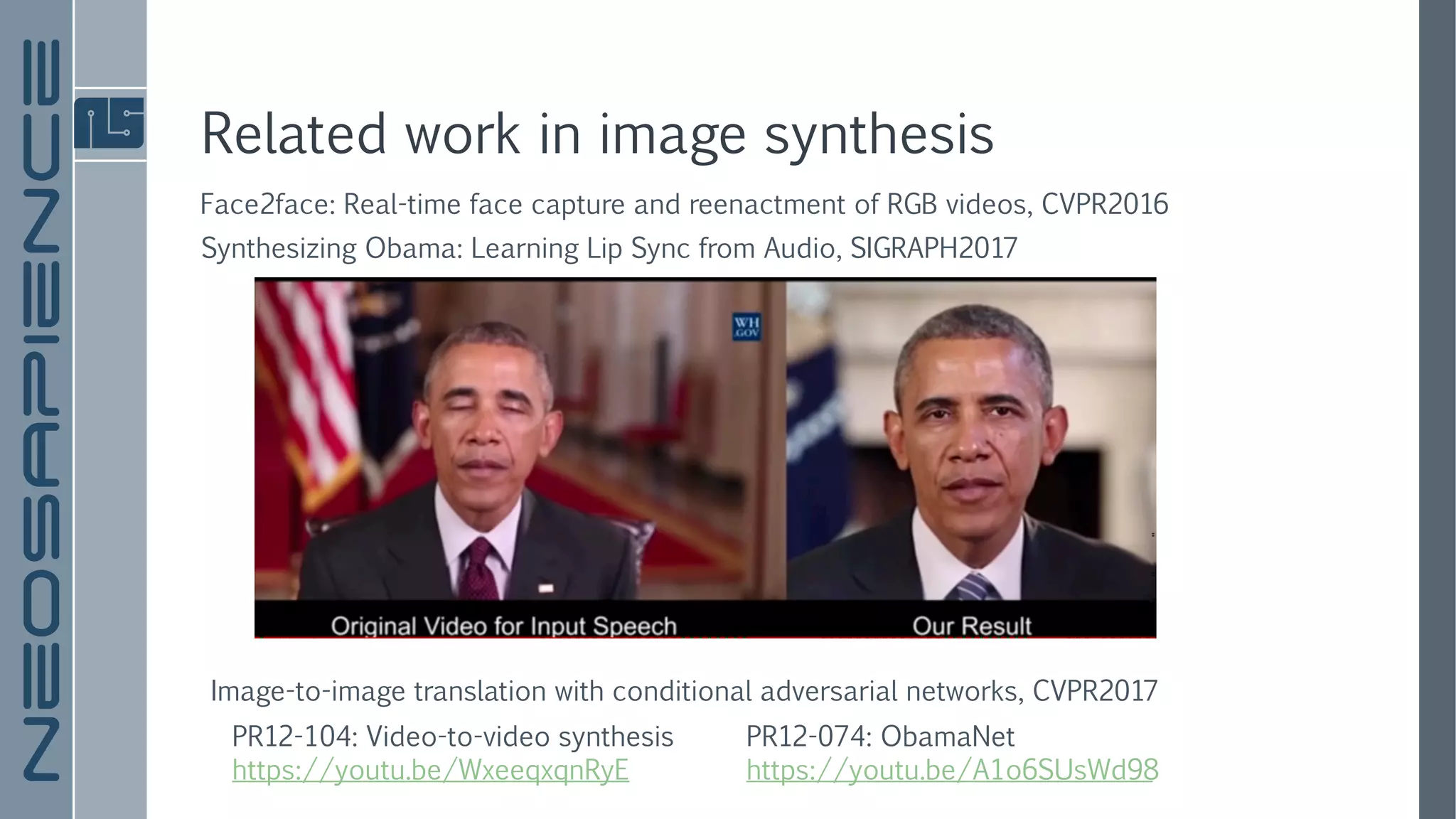
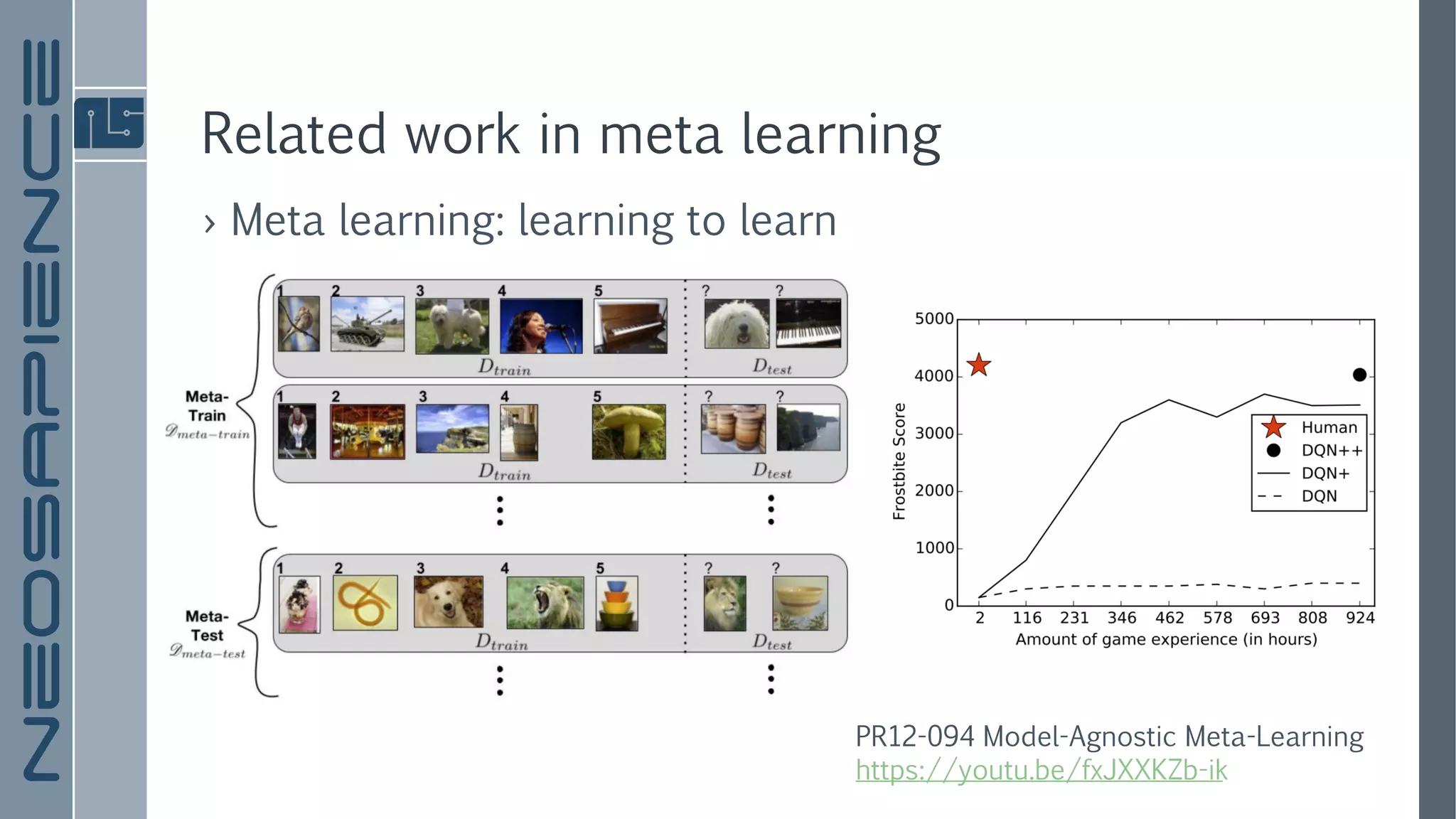
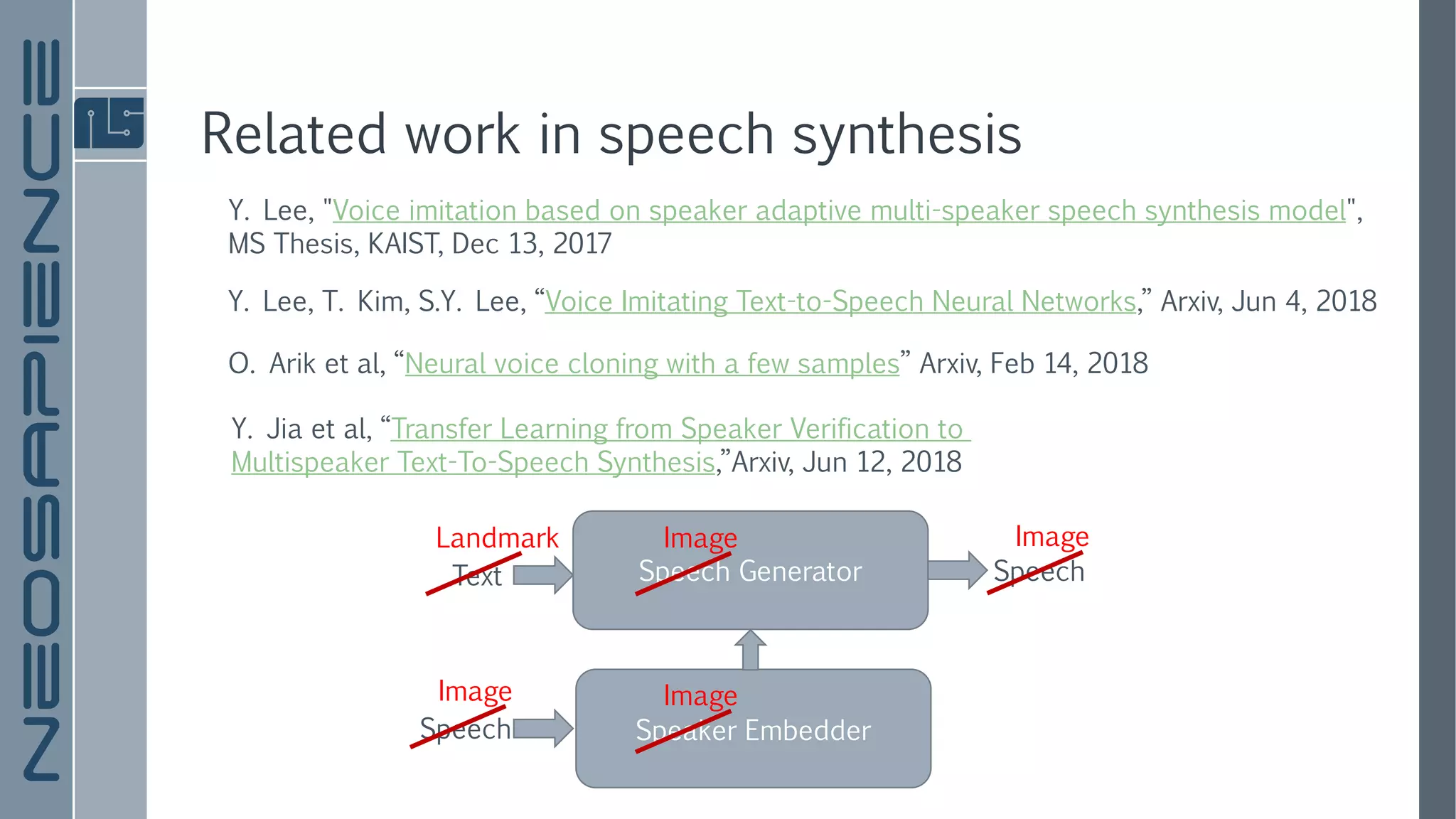
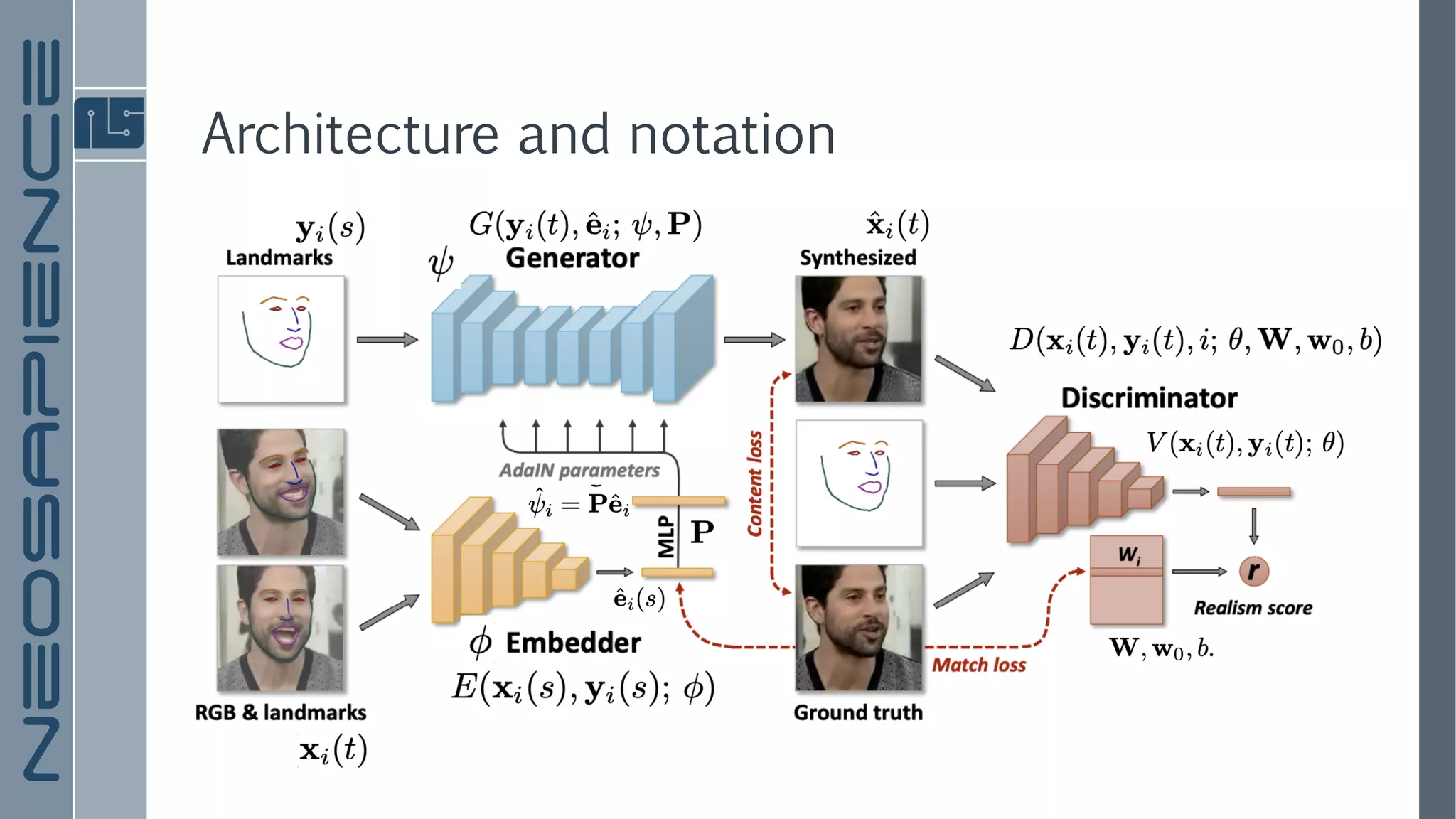



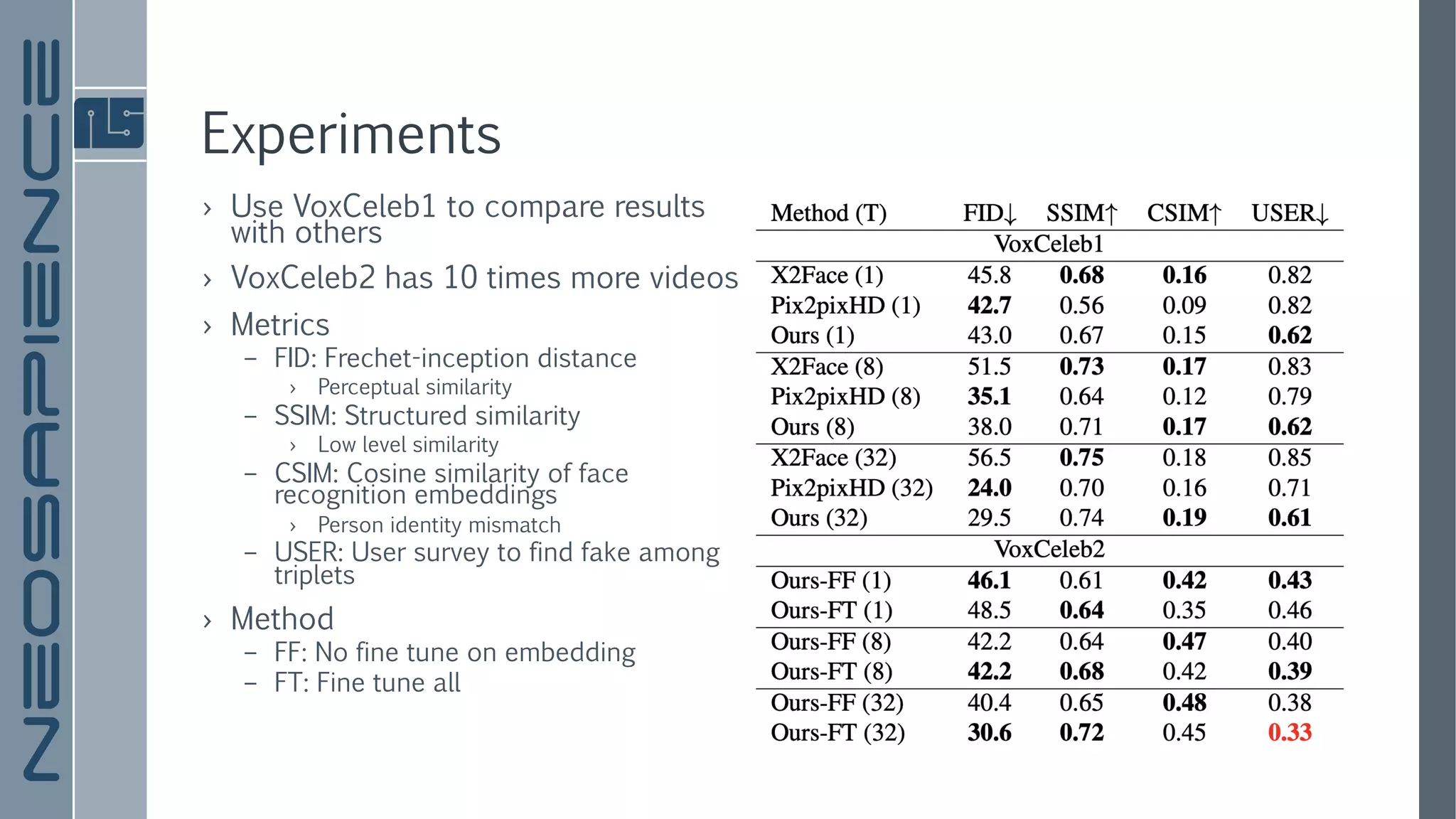






The document discusses a framework for few-shot adversarial learning to create realistic neural talking head models using minimal photographic input. It details various related works in image synthesis and meta learning, and describes the architecture and methodology utilized in their approach along with experimental results. The findings suggest that high levels of realism and personalization can be achieved with as few as one image, although it acknowledges limitations regarding representation and gaze adaptation.






































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)














