Download to read offline


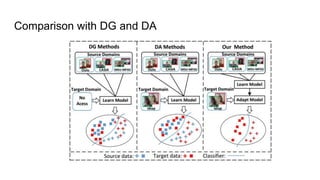
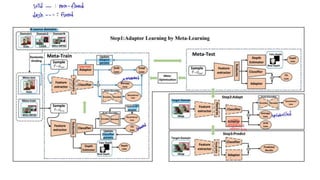
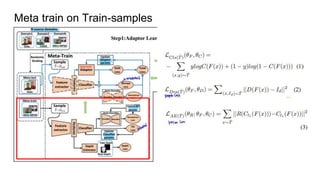
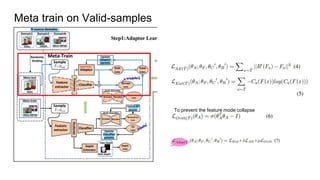


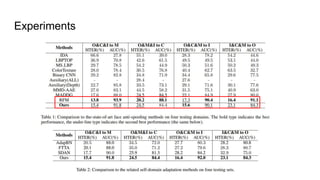




The document proposes a self-domain adaptation framework that utilizes unlabeled target data at inference time. It introduces meta-learning based adaptor learning for training, where the adaptor is initialized using multiple source domains and meta-learning. During testing, the adaptor is further trained using only the unlabeled target data while keeping other parameters fixed, allowing adaptation to the target domain. The conclusions are that this approach introduces effective adaptor learning and loss functions under unsupervised learning conditions.
![[Pr12] dann jaejun yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12dann-jaejunyoo-170604150015-thumbnail.jpg?width=640&height=640&fit=bounds)











![[2A4]DeepLearningAtNAVER](https://cdn.slidesharecdn.com/ss_thumbnails/2a4deeplearningatnaver-140929210707-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






![[ECCV2022] Generative Domain Adaptation for Face Anti-Spoofing](https://cdn.slidesharecdn.com/ss_thumbnails/eccv2022generativedomainadaptationforfaceanti-spoofing-230404070519-3d92c871-thumbnail.jpg?width=640&height=640&fit=bounds)
![[CVPR'22] Domain Generalization via Shuffled Style Assembly for Face Anti-Spo...](https://cdn.slidesharecdn.com/ss_thumbnails/cvpr22domaingeneralizationviashuffledstyleassemblyforfaceanti-spoofing-230404065903-720fcc8d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TIFS'22] Learning Meta Pattern for Face Anti-Spoofing](https://cdn.slidesharecdn.com/ss_thumbnails/tifs22learningmetapatternforfaceanti-spoofing-230404065519-012efd84-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AAAI'23]Learning Polysemantic Spoof Trace](https://cdn.slidesharecdn.com/ss_thumbnails/aaai23learningpolysemanticspooftrace1-230404065205-9701b422-thumbnail.jpg?width=640&height=640&fit=bounds)

![[CVPRW2021]FReTAL: Generalizing Deepfake detection using Knowledge Distillati...](https://cdn.slidesharecdn.com/ss_thumbnails/cvprwfretalpresentfeacherrepresentationtransferlearning-220409091913-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NeuralIPS 2020]filter in filter pruning](https://cdn.slidesharecdn.com/ss_thumbnails/filterinfilterpruningpaperreview2-220409090549-thumbnail.jpg?width=640&height=640&fit=bounds)


![“zero-shot” super-resolution using deep internal learning [CVPR2018]](https://cdn.slidesharecdn.com/ss_thumbnails/cvpr2018zero-shotsuper-resolutionusingdeepinternallearning-210903045317-thumbnail.jpg?width=640&height=640&fit=bounds)
![[CVPRW 2020]Real world Super-Resolution via Kernel Estimation and Noise Injec...](https://cdn.slidesharecdn.com/ss_thumbnails/seminarforpresentcvprw2020real-worldsuper-resolutionviakernelestimationandnoiseinjection-210830124632-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Seminar arxiv]fake face detection via adaptive residuals extraction network](https://cdn.slidesharecdn.com/ss_thumbnails/seminararxivfakefacedetectionviaadaptiveresidualsextractionnetwork-210521190205-thumbnail.jpg?width=640&height=640&fit=bounds)





















