Download to read offline






![• Bigtable: A Distributed Storage System for
Structured Data [Google, Inc.]
– Chang et al., OSDI, 2006
– Provides record-oriented access to very large tables
– Lacks geographic replication
– Lacks rich database functionalities
• Secondary indexes
• Materialized views
• Create multiple tables
• Hash-organized tables
Existing Database Management Systems
7](https://image.slidesharecdn.com/pnutsslide-180531202051/85/PNUTS-Yahoo-s-Hosted-Data-Serving-Platform-7-320.jpg)







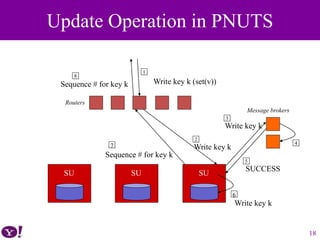









![• Yahoo! Message Broker (YMB) [redo log]
– Topic-based publish/subscribe system
– Data is considered “committed” when they have been published to YMB
– At some point after being committed, the update will be asynchronously
propagated to different regions and applied to their replicas
• Recovery via YMB
– The tablet controller requests a copy from a particular remote replica (the
“source tablet”)
– A “checkpoint message” is published to YMB to ensure that any in-flight
updates at the time the copy is initiated are applied to the source tablet
– The source tablet is copied to the destination region
– Backup is used in practice
30
Recovery via YMB](https://image.slidesharecdn.com/pnutsslide-180531202051/85/PNUTS-Yahoo-s-Hosted-Data-Serving-Platform-30-320.jpg)










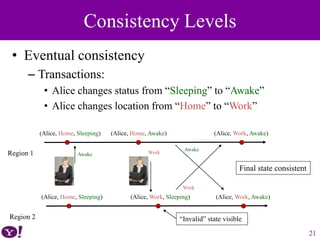
PNUTS is Yahoo!'s distributed database system designed for modern web applications, emphasizing scalability, low latency, and asynchronous geographic replication. It supports flexible consistency models, allowing applications to operate under eventual and timeline consistency, and utilizes a message broker for replication and transaction logs. The evaluation demonstrates PNUTS' ability to handle high workloads while addressing the limitations of existing database management systems.




















![[PR12] categorical reparameterization with gumbel softmax](https://cdn.slidesharecdn.com/ss_thumbnails/pr12categoricalreparameterizationwithgumbel-softmax-180304131005-thumbnail.jpg?width=640&height=640&fit=bounds)































































