Download to read offline






![Give It All [the PIDs] You Got
Assign a DOI to DMP of record (i.e.,
submitted with grant proposal)
Leverage other PIDS to populate DMP
over time:
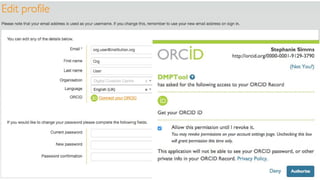
● Researcher IDs (ORCIDs)
● Funder IDs (FundRef)
● Resource IDs (RRIDs)
● Projects, instruments, protocols,
ethics, physical samples, etc.
Afro-Rican | Give It All You Got](https://image.slidesharecdn.com/pids-in-dmps-simms-161114172345/85/PIDs-in-DMPs-Spinning-tracks-with-syntax-11-320.jpg)





The document discusses the state of dynamic and machine-actionable Data Management Plans (DMPs), focusing on the integration of Persistent Identifiers (PIDs) to enhance their usability and efficiency. It emphasizes the need for collaboration among researchers, institutions, and stakeholders to develop effective DMPs that facilitate smoother workflows and data sharing. The document also highlights upcoming events and encourages input on various aspects of DMP design and functionality.












































































