Download to read offline





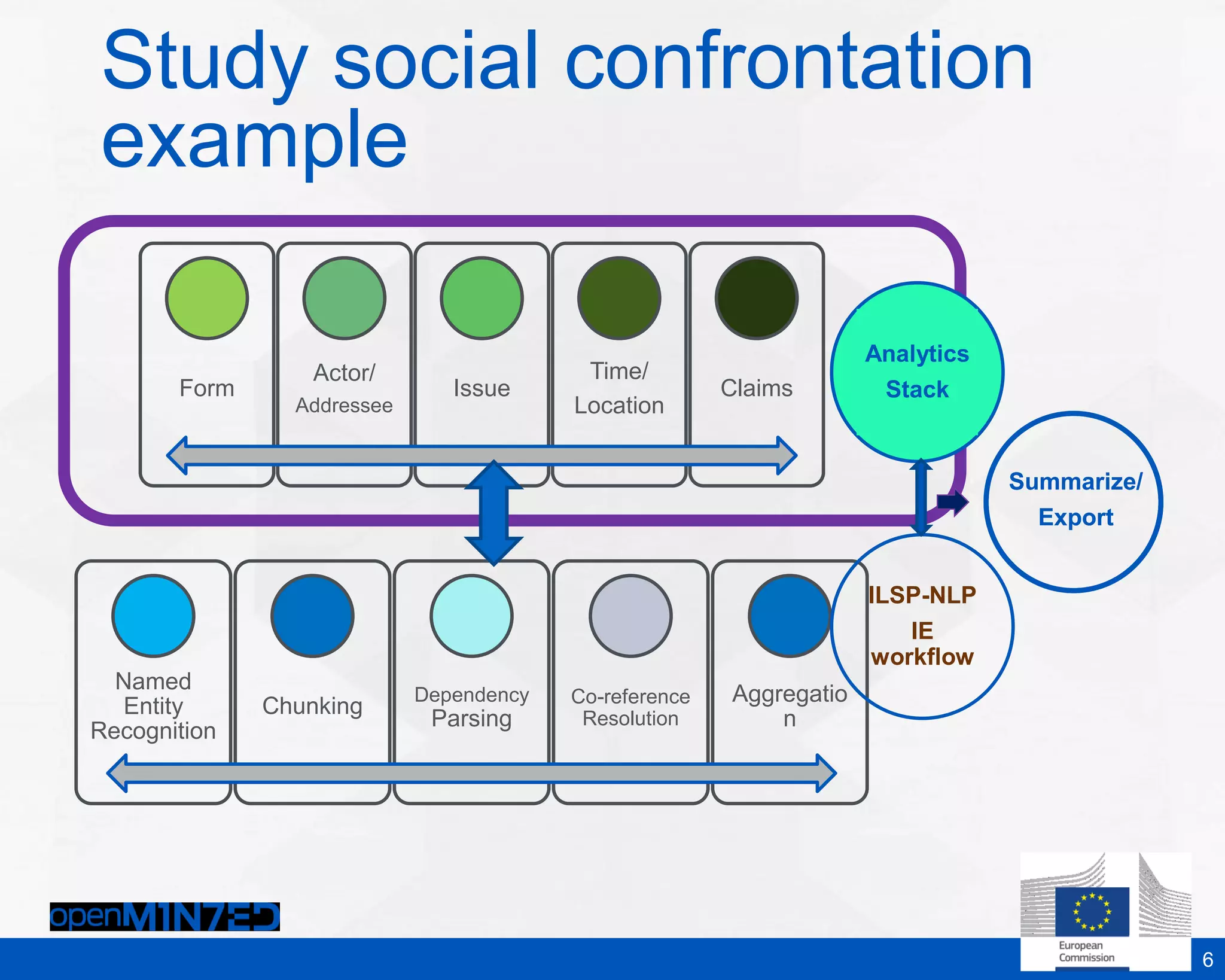
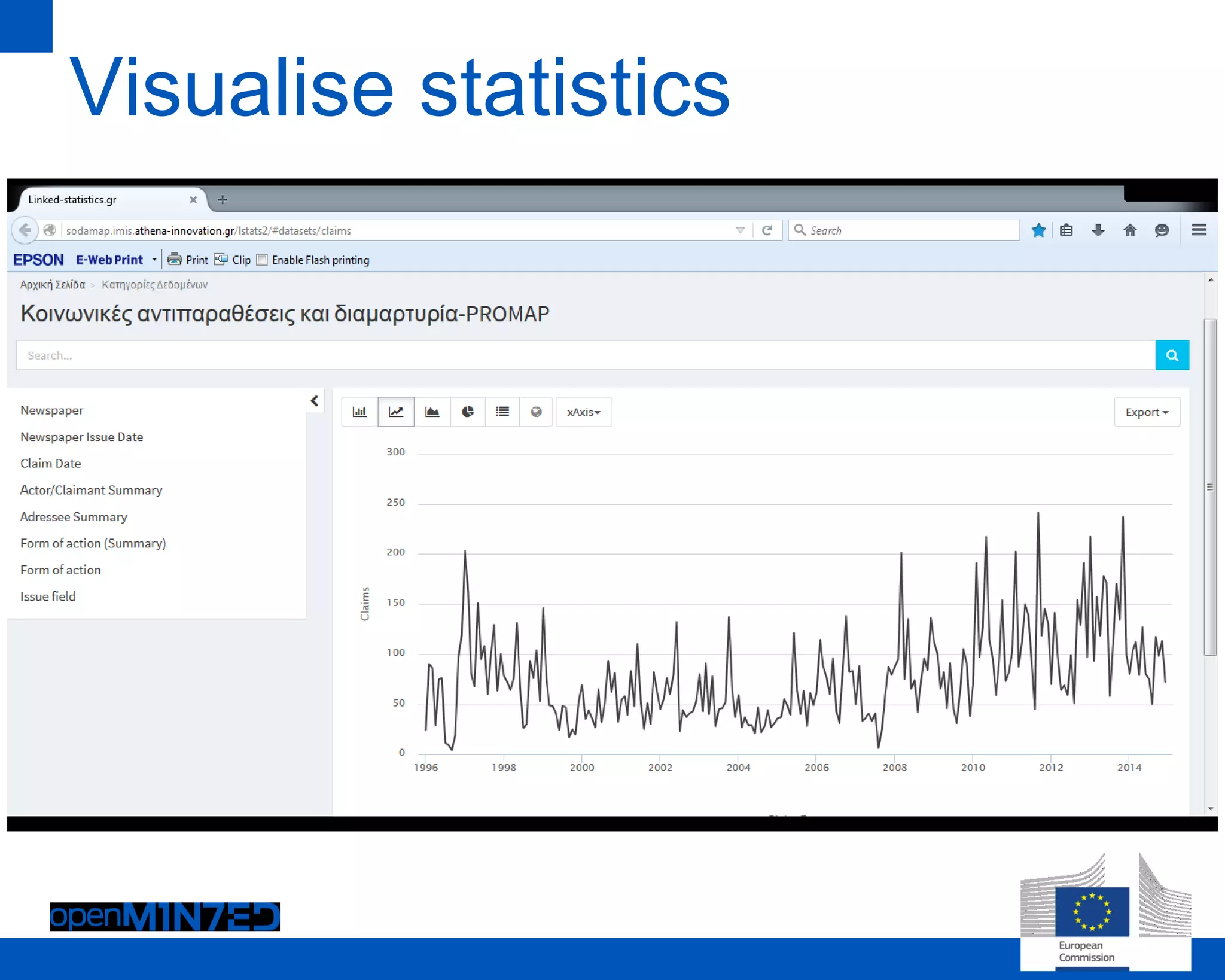



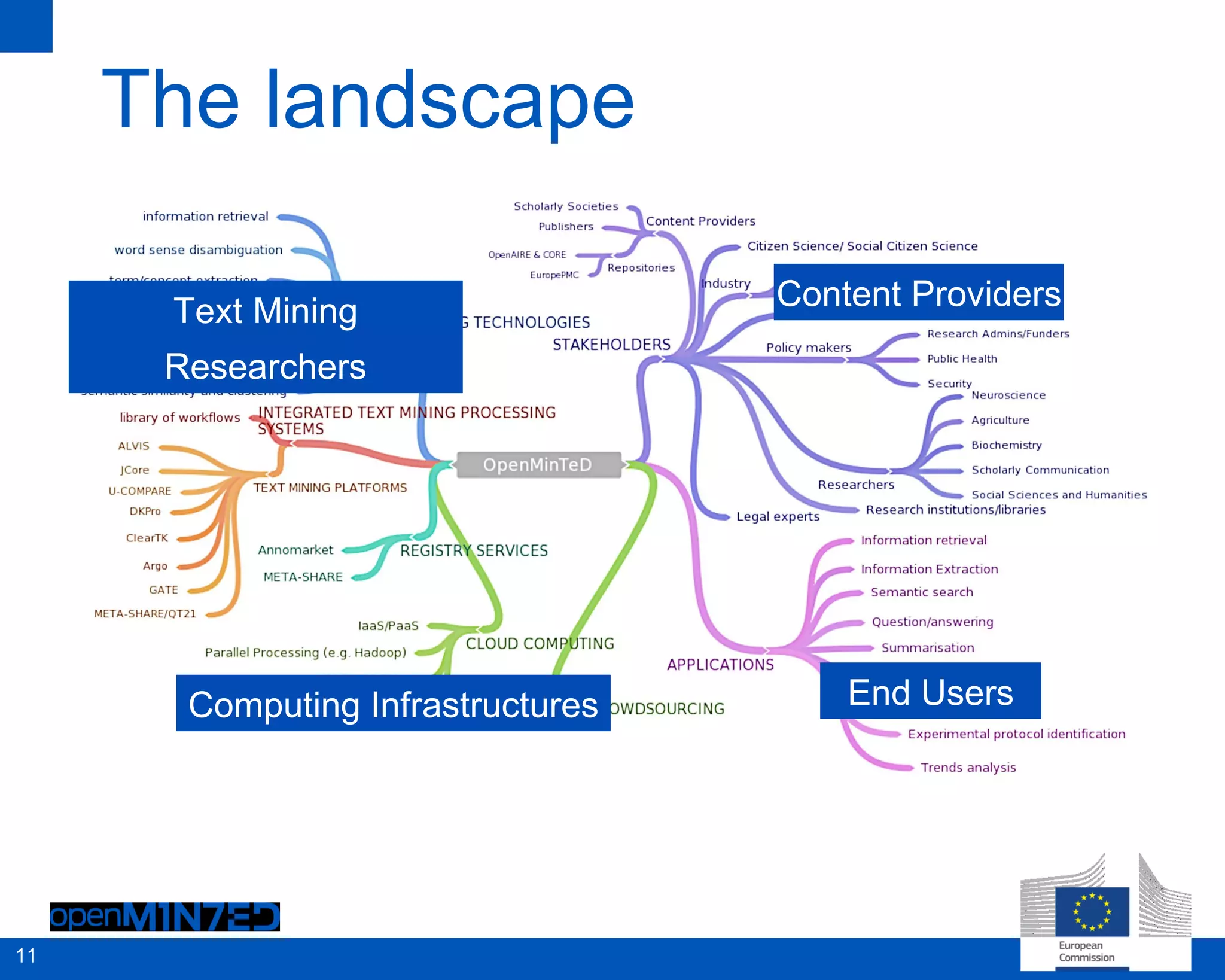


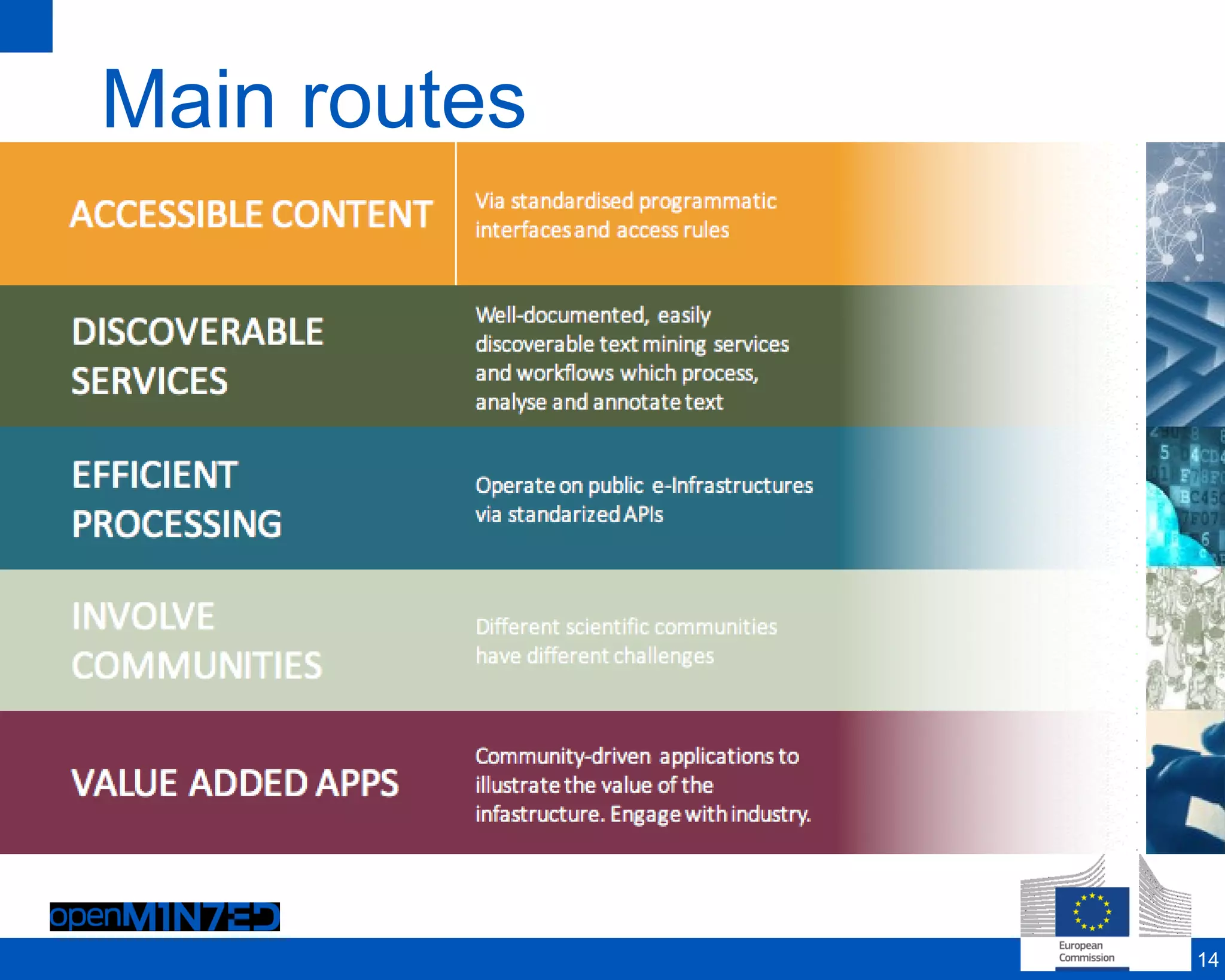







The document discusses making scientific content more accessible and useful through text and data mining. It notes that the global research community generates over 1.5 million new articles per year but many are never read or cited. Emerging solutions like machine reading, understanding and predicting can help structure and mine textual data to extract meaningful insights. The OpenMinted project aims to establish an open text and data mining platform and infrastructure for researchers to collaboratively work with scientific sources. It outlines challenges around content, services and processing as well as main routes to make content more accessible through metadata, transfer protocols and licensing. The project involves various partners and use cases across domains like scholarly communication, life sciences, agriculture and social sciences.




























































![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)