Downloaded 10 times


![19/03/2014 4Daniel Vila-Suero
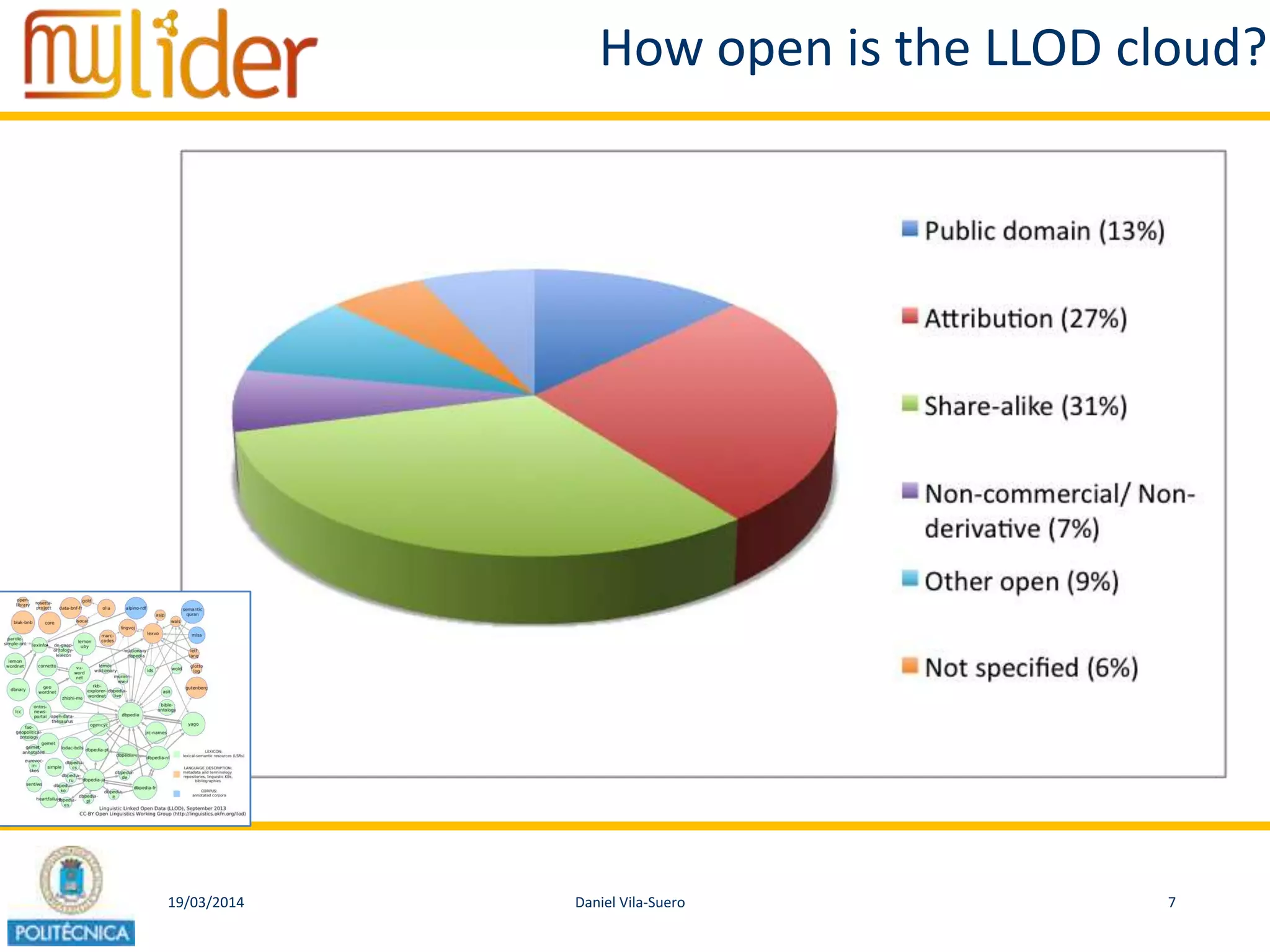
How open is the LOD cloud?
[1] Rodriguez-Doncel, Victor et al., 2013. Rights declaration in Linked Data.
in Proc. of the 3rd Int. W. on Consuming Linked Data O. Hartig et al. (Eds) CEUR vol. 1034 (2013)](https://image.slidesharecdn.com/edf-140319075755-phpapp02/75/3LD-Towards-high-quality-industry-ready-Linguistic-Linked-Licensed-Data-4-2048.jpg)
![19/03/2014 5Daniel Vila-Suero
How open is the LOD cloud?
• 338 datasets in :
[1] Rodriguez-Doncel, Victor et al., 2013. Rights declaration in Linked Data.
in Proc. of the 3rd Int. W. on Consuming Linked Data O. Hartig et al. (Eds) CEUR vol. 1034 (2013)](https://image.slidesharecdn.com/edf-140319075755-phpapp02/75/3LD-Towards-high-quality-industry-ready-Linguistic-Linked-Licensed-Data-5-2048.jpg)
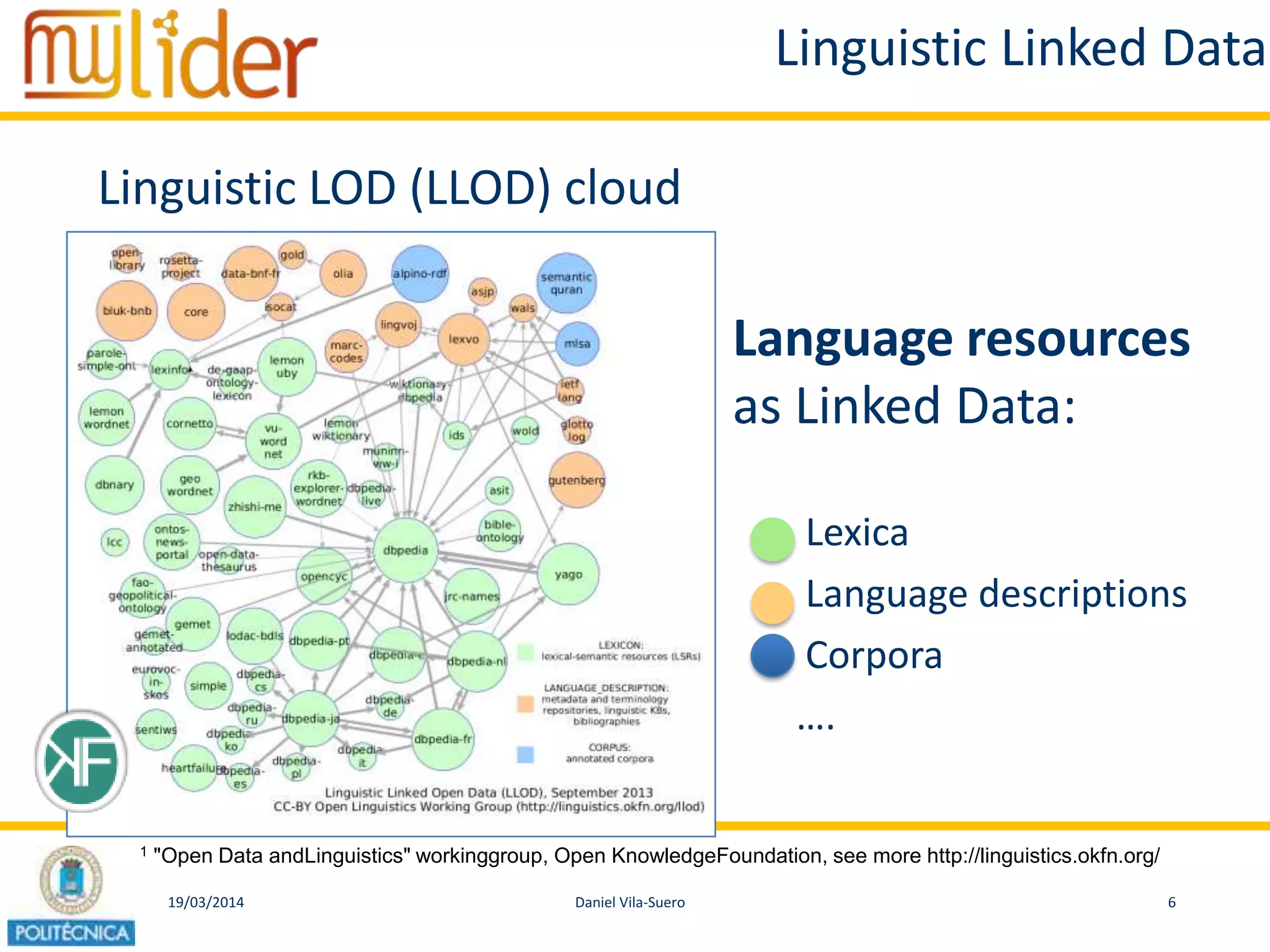












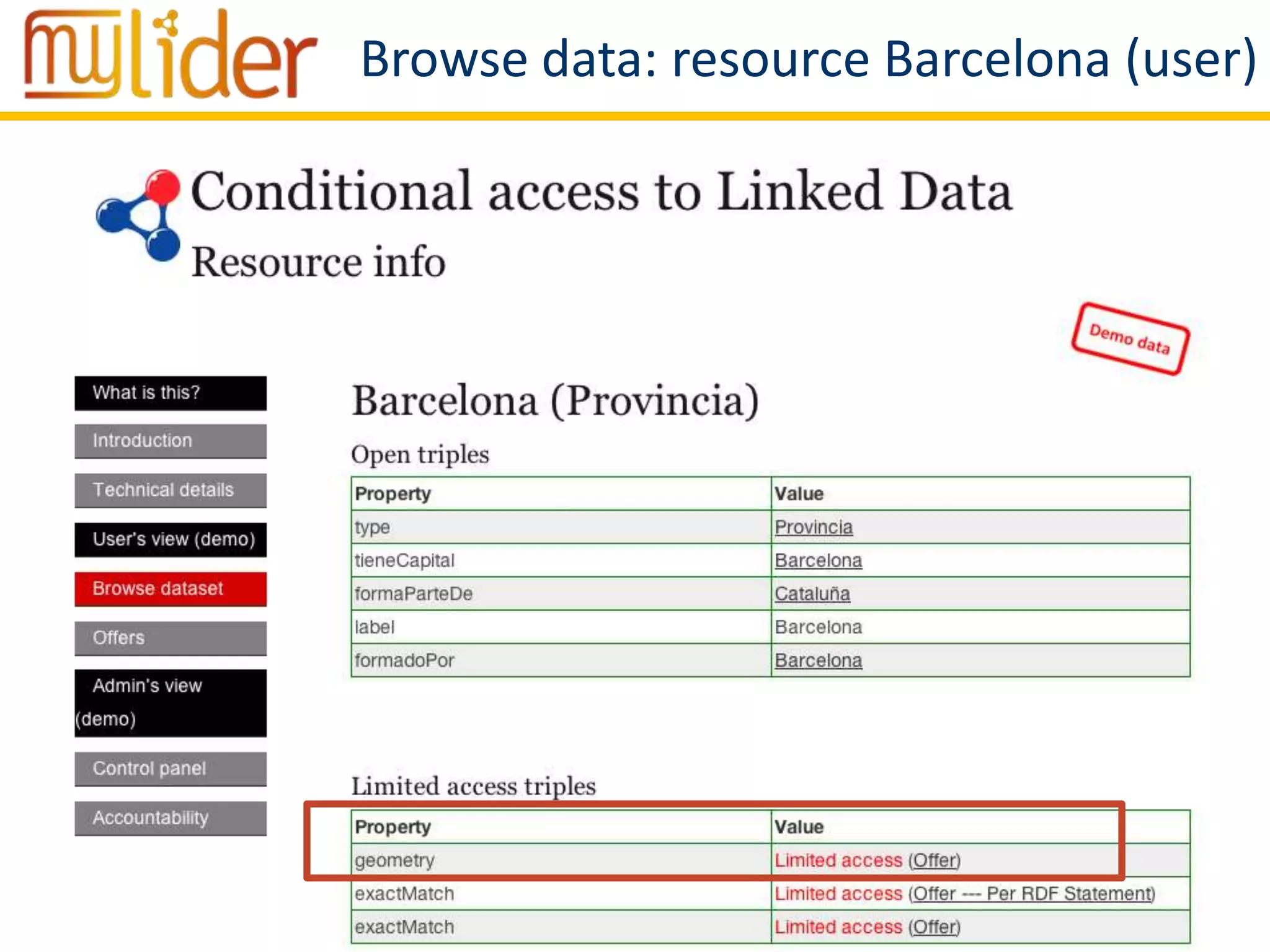

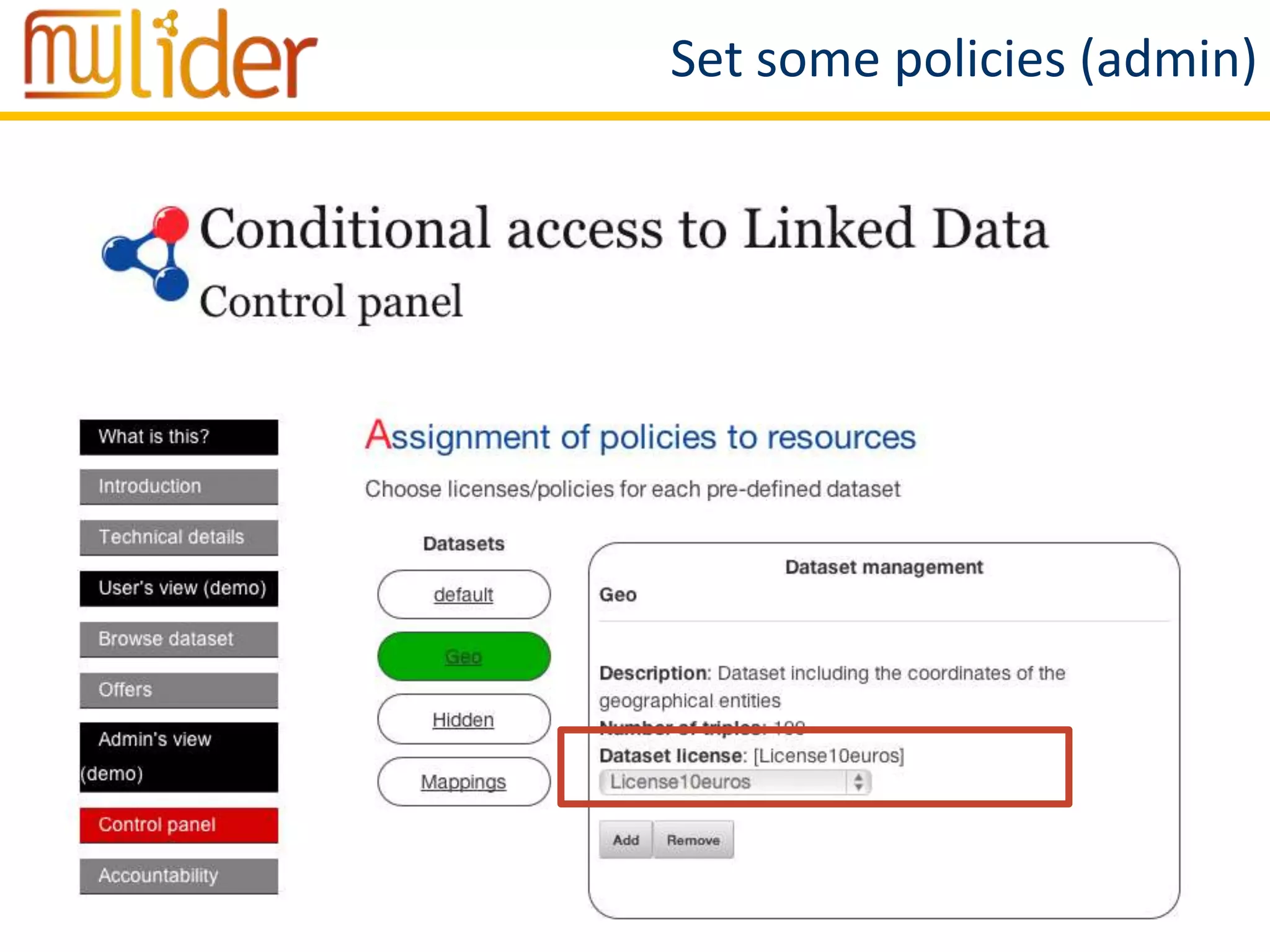
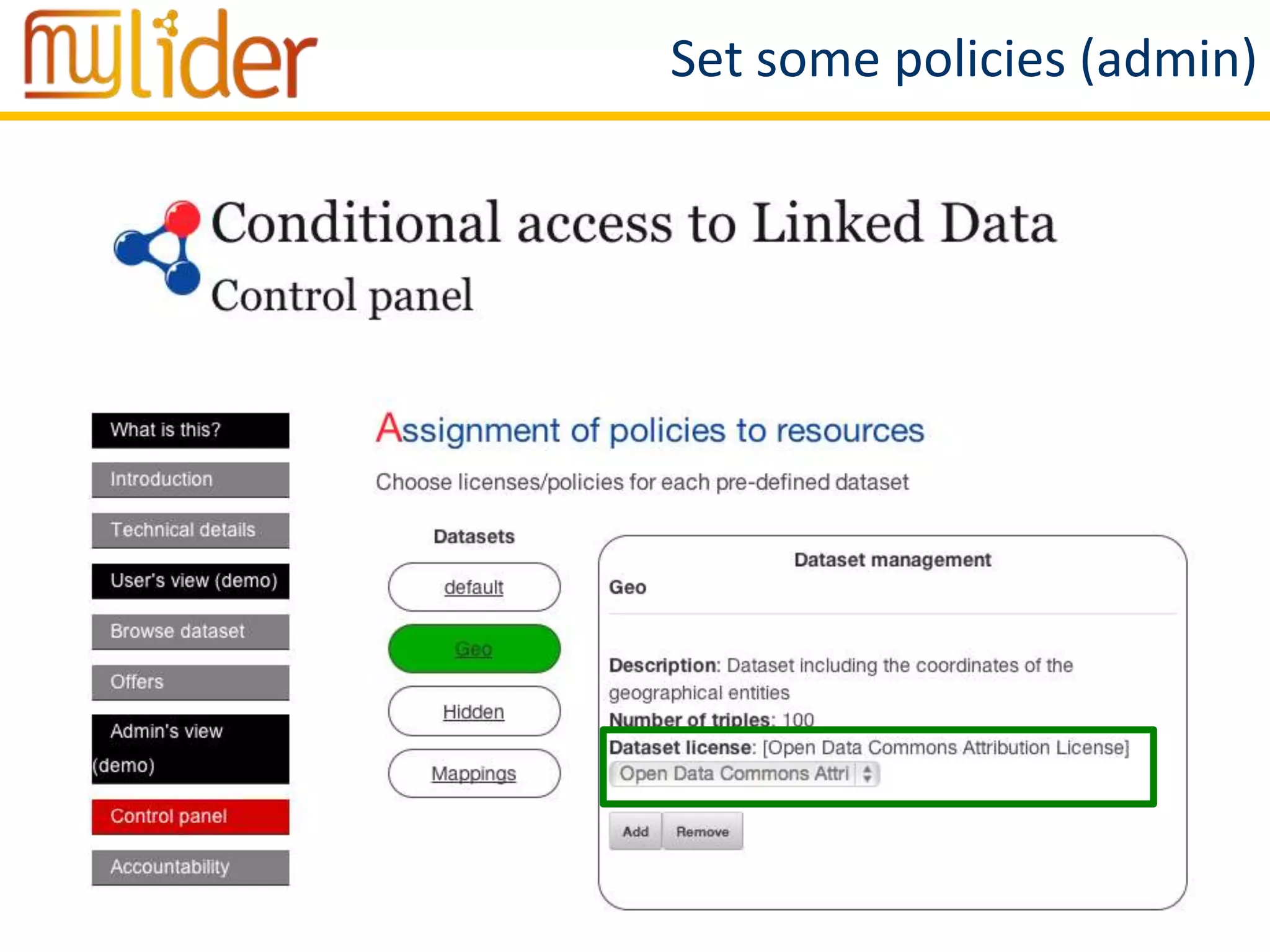
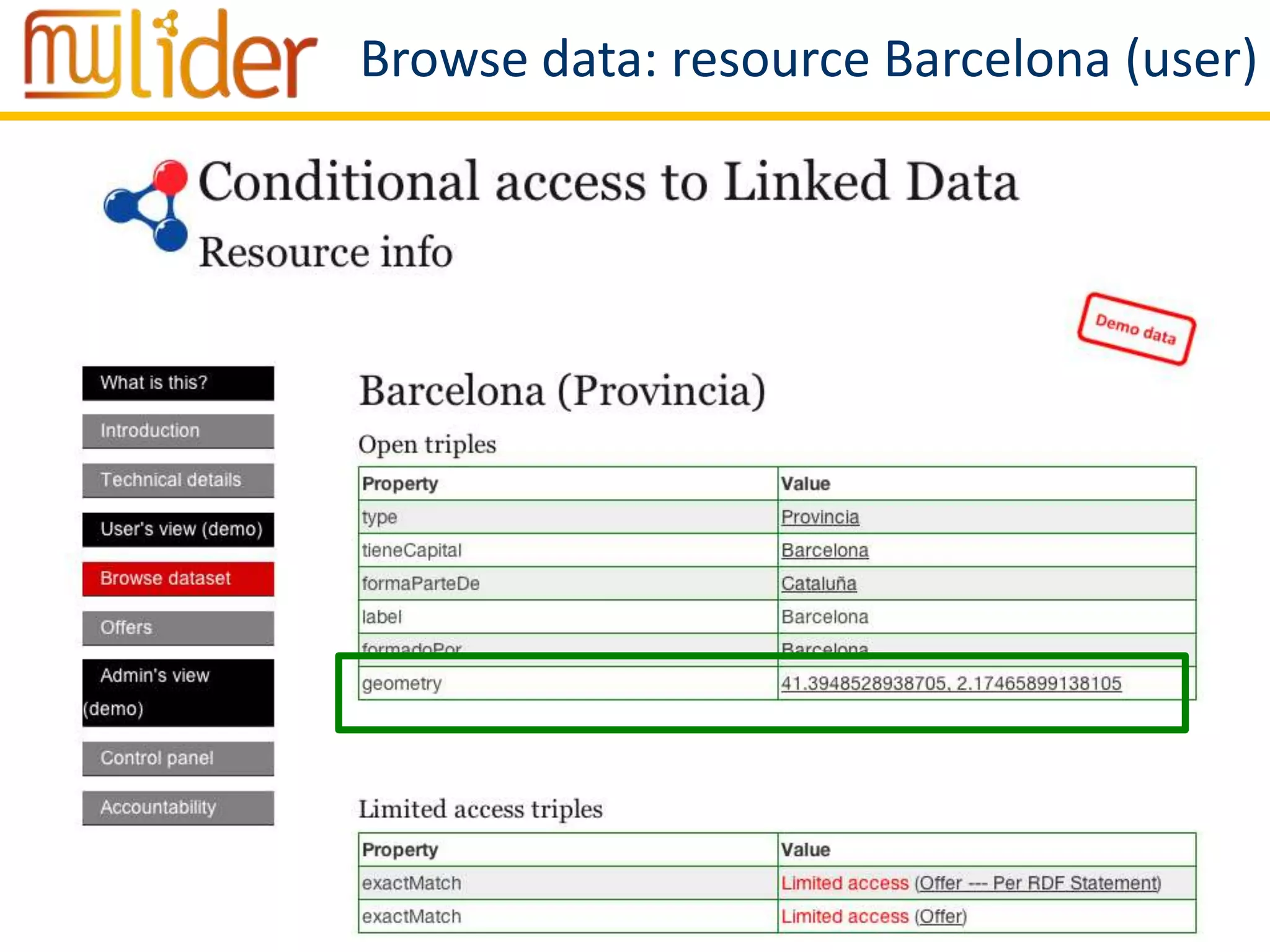

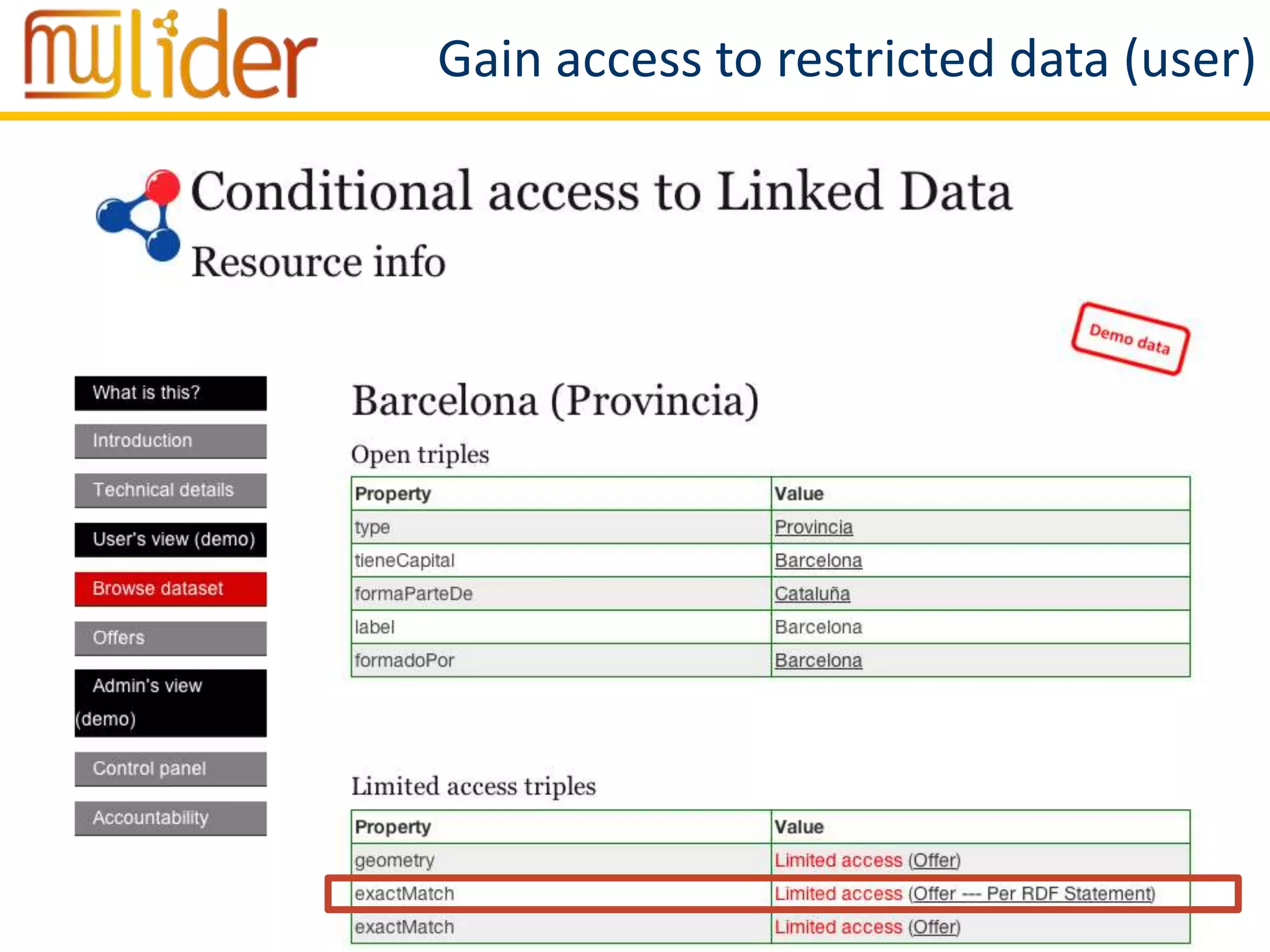
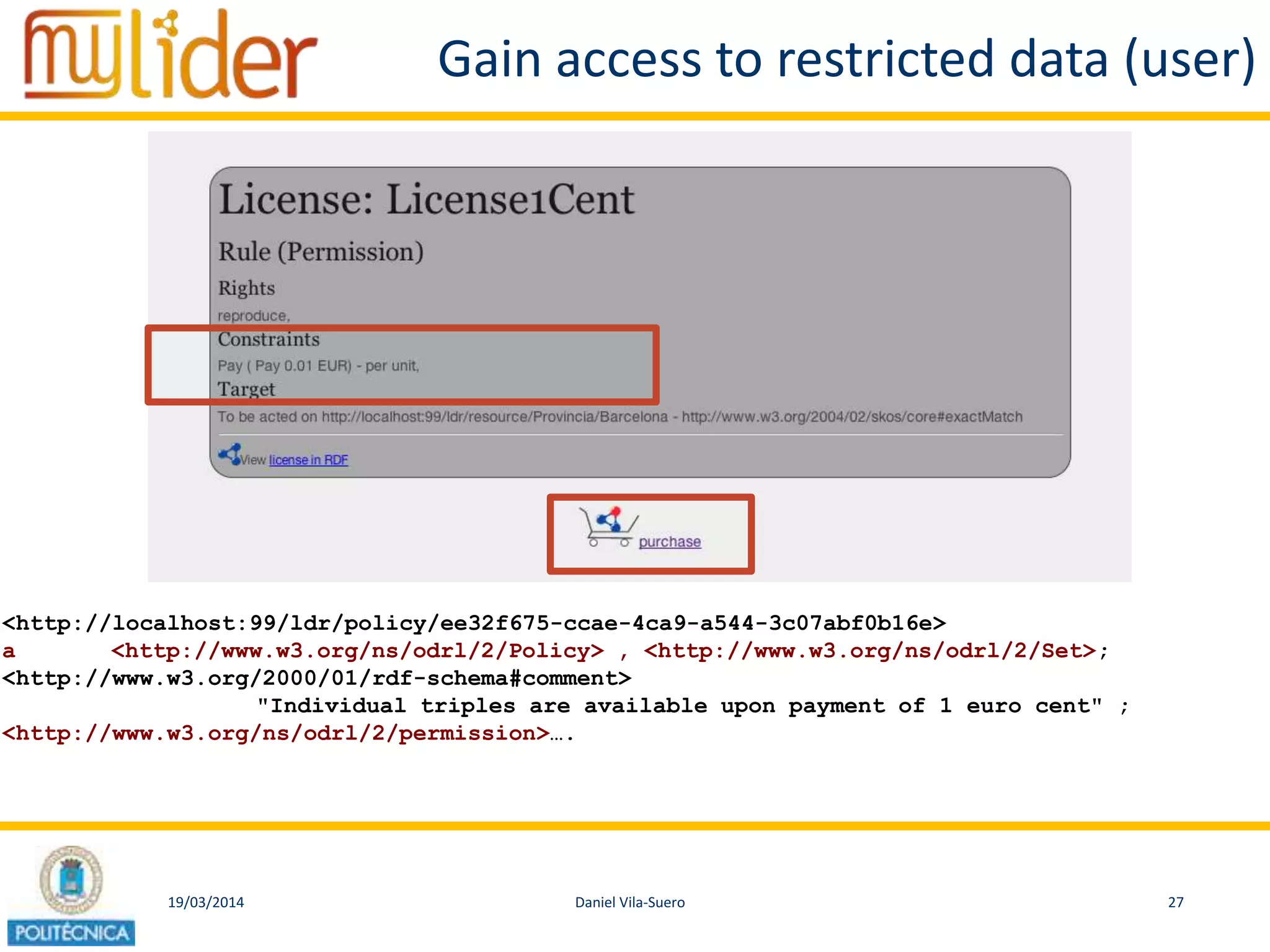



The document discusses the concept of '3LD' (Linguistic Linked Licensed Data) which focuses on licensing language resources as linked data using standard data models. It emphasizes the importance of metadata and rights declarations in order to facilitate open access and promote the re-use of linguistic data. A demonstration of a conditional access linked data prototype is provided, showcasing its application for managing access to geographical data in Spain.






































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
















