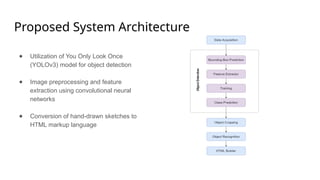
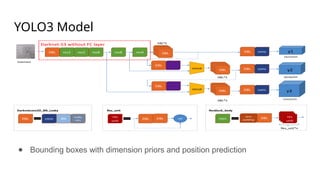
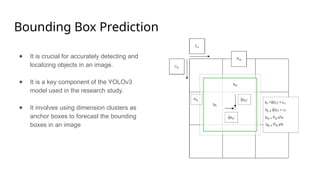
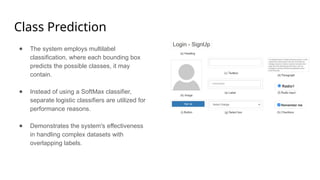
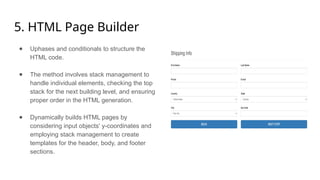
The document outlines a methodology for generating HTML code from hand-drawn sketches using deep learning techniques, particularly employing the YOLOv3 model for object detection and feature extraction. It discusses the architecture and training process of the model, achieving an accuracy rate of 87.71%, while also noting limitations such as the inability to support hyperlinks. Overall, the proposed system allows for efficient transformation of design mock-ups into structured HTML code, facilitating streamlined web page development.




























































![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)









