Recommended
PDF
PDF
KEY
Chiba pm#1 - ArangoDB for Perl
PDF
PDF
PDF
PPTX
WebSocketでリアルタイム通信 (第13回学生LT資料)
PDF
PDF
思い通りにいかないのがWebなんて 割り切りたくないから (Gunma.web #4 2011/02/12)
PDF
PDF
PDF
MongoDBではじめるカジュアルなタイムラインシステム
PDF
PDF
丸の内MongoDB勉強会#20LT 2.8のストレージエンジン動かしてみました
PDF
PDF
(きっと)あなたにも出来る!Hyperledger composer でブロックチェーンアプリを動かしてみた
PDF
PPTX
PDF
CasualなMongoDBのサービス運用Tips
PDF
PDF
BestGems.org -RubyGemsランキングサイトのご紹介-
PPTX
PDF
Using SockJS(Websocket) with Sencha Ext JS
PPTX
KEY
PDF
ちゃんとWeb会議スライド『Coffee script』
PDF
PDF
PDF
Rails と Rack と HTTP と通信の話
PPTX
Fluxflex meetup 2011 in Tokyo
More Related Content
PDF
PDF
KEY
Chiba pm#1 - ArangoDB for Perl
PDF
PDF
PDF
PPTX
WebSocketでリアルタイム通信 (第13回学生LT資料)
PDF
What's hot
PDF
思い通りにいかないのがWebなんて 割り切りたくないから (Gunma.web #4 2011/02/12)
PDF
PDF
PDF
MongoDBではじめるカジュアルなタイムラインシステム
PDF
PDF
丸の内MongoDB勉強会#20LT 2.8のストレージエンジン動かしてみました
PDF
PDF
(きっと)あなたにも出来る!Hyperledger composer でブロックチェーンアプリを動かしてみた
PDF
PPTX
PDF
CasualなMongoDBのサービス運用Tips
PDF
PDF
BestGems.org -RubyGemsランキングサイトのご紹介-
PPTX
PDF
Using SockJS(Websocket) with Sencha Ext JS
PPTX
KEY
PDF
ちゃんとWeb会議スライド『Coffee script』
PDF
PDF
Similar to エコなWebサーバー
PDF
Rails と Rack と HTTP と通信の話
PPTX
Fluxflex meetup 2011 in Tokyo
PDF
ゲットーの斜め上をゆくWebアプリケーションフレームワークの開発
PPTX
PDF
PDF
PPTX
PPTX
サーバーの初歩的な話セミナー@大阪20120901
PDF
Beginning Java EE 6 勉強会(7) #bje_study
PDF
日本 GNU AWK ユーザー会チラシ - OSC2012 Tokyo/Fall
PDF
PDF
KEY
Mojoliciousをウェブ制作現場で使ってみてる
PDF
PDF
PDF
PDF
Hypermedia: The Missing Element to Building Adaptable Web APIs in Rails (増補日本語版)
PPT
OSC2008 Tokyo/Spring REST勉強夜会
PDF
PDF
More from emasaka
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
Recently uploaded
PDF
PMBOK 7th Edition_Project Management Context Diagram
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
PDF
PMBOK 7th Edition Project Management Process Scrum
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
PDF
PMBOK 7th Edition_Project Management Process_WF Type Development
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
エコなWebサーバー 1. 2. 自己紹介
● twitterとかGitHubとか: emasaka
● blog: 本を読む
http://emasaka.blog65.fc2.com/
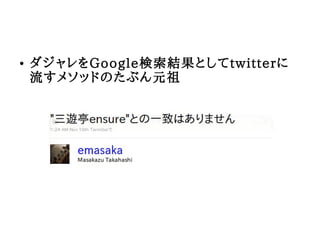
3. ● ダジャレをGoogle検索結果としてtwitterに
流すメソッドのたぶん元祖
4. 過去の実績
● Bash on Rails
●
pure Bashのメタプログラミングで、
オブジェクト指向もどき+ActiveRecord
もどき+ERBもどき+YAMLもどき、ほか
5. ● sh.inatra
●
pure Bashでsinatraもどき
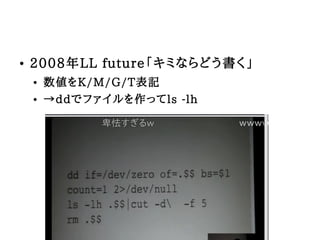
6. ● 2008年LL future「キミならどう書く」
● 数値をK/M/G/T表記
● →ddでファイルを作ってls -lh
7. 8. 9. 10. 11. ● ブラウザでカット?
● Adblock PlusとかGreaseMonkeyとか
● でも送ってくる分のHTMLが無駄
MOTTAINAI!
12. HTTPの仕様を見る
● HTTP 1.1 "Range Requests and Partial
Responses"
● コンテンツの一部分をリクエストできる
● リクエストヘッダーにRange:フィールド
● 206 Partial Contentのレスポンス
Range: bytes=1000
13. 使用例
● ダウンローダー
● 分割ダウンロード
● リジューム
● 2chブラウザ(追記型データ)
14. ただ
● バイト数指定なので、本文抽出には使いづらい
● やっぱりDOMとかでやりたい
新しい指定方法が必要
15. メールヘッダを見てみる
XMoe: CCSakura/Sakura
(萌え属性表明)
● 1990年代に一部で流行
(通信用語の基礎知識
http://www.wdic.org/w/WDIC/X-Moe より)
16. X-*フィールド
● 勝手拡張フィールド
● X-Mailer:とかX-ML-Name:とかはメジャー
17. HTTPのレスポンスヘッダでも
XPoweredBy: Phusion Passenger
(mod_rails/mod_rack) 2.2.5
● Passengerで
18. Xhacker: If you're reading this,
you should visit automattic.com/
jobs and apply to join the fun,
mention this header.
● WordPress.comのHTTPレスポンスヘッダー
● X-*:フィールドを使ってリクルート
※ネタ元
http://www.1x1.jp/blog/2009/09/wordpress_http_heade.html
19. 20. XPathで指定
● X-Path:フィールドでXPathを指定
● HTMLのうち、その部分だけ返ってくる
(リクエスト)
XPath: //p[@id="hello"]
(レスポンス)
<p id="hello">〜</p>
※厳密にはこの指定じゃNGみたいですが
21. 22. 作りました
●
名付けて
WEBrick-DOM
(ウェブリック・ドム)
←これはリックドム
23. サーバーのサンプル (WEBrick)
require 'webrick'
srv = WEBrick::HTTPServer.new({
:DocumentRoot => './',
:BindAddress => '127.0.0.1',
:Port => 20080 })
trap('INT'){ srv.shutdown }
srv.start
※ほぼRubyのリファレンスマニュアルから
24. 25. やってること
● WEBrickのDefaultFileHandlerをラップす
るサブクラスを作る
● X-Path:フィールドがあればnokogiriで処理
● それ以外はsuper丸投げ
● FileHandler.add_handler()で、.html
と.htmの
ハンドラーに指定
● 50行ぐらいのごく簡単なコードです
※参考
http://jp.rubyist.net/magazine/?0002-WEBrickProxy
26. 27. 28. 29. 30.

















![XPathで指定
● X-Path:フィールドでXPathを指定
● HTMLのうち、その部分だけ返ってくる
(リクエスト)
XPath: //p[@id="hello"]
(レスポンス)
<p id="hello">〜</p>
※厳密にはこの指定じゃNGみたいですが](https://image.slidesharecdn.com/eco-091130082707-phpapp01/85/Web-20-320.jpg)
















































































