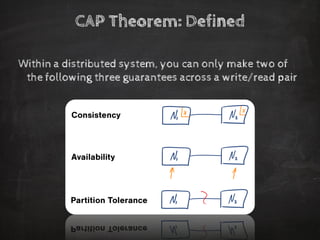
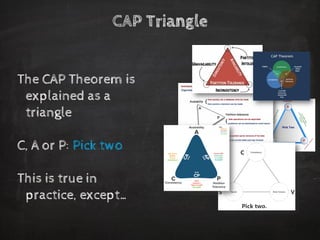
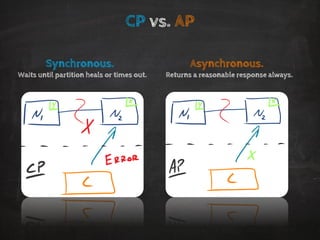
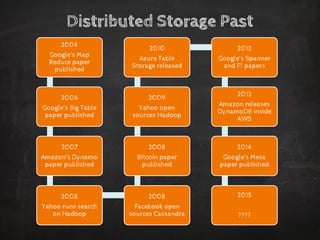
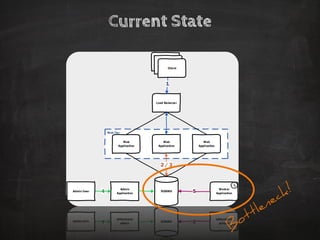
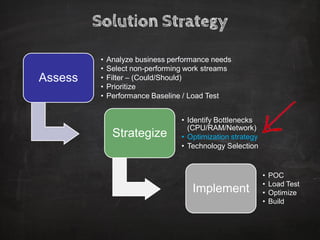
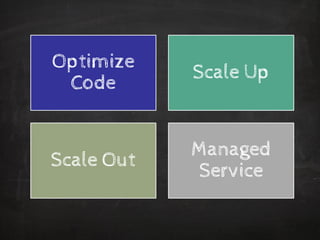
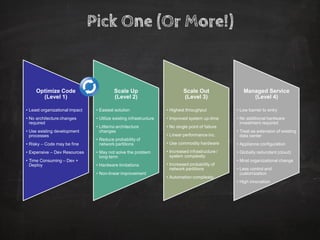
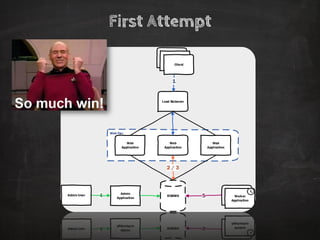
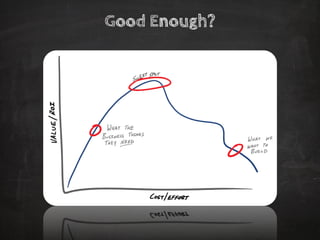
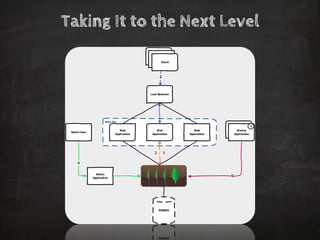
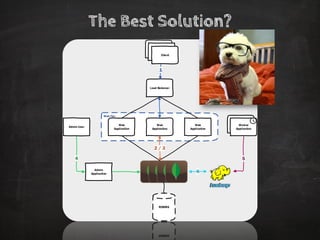
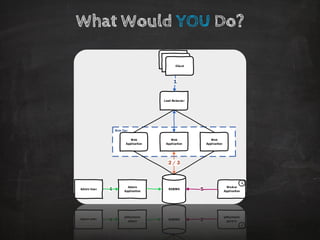
The document discusses distributed data storage and the CAP theorem, emphasizing the challenges of achieving consistency, availability, and partition tolerance in distributed systems. It outlines strategies for scaling applications, addressing bottlenecks, and adopting managed services to handle increased demand for real-time data processing. Additionally, it explores the evolution of distributed storage technologies and their implications for businesses, particularly in the context of internet-scale needs.




































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)

















