Downloaded 19 times




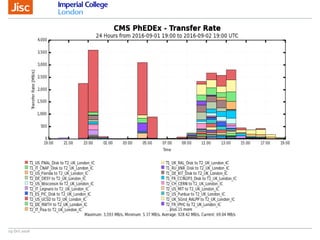

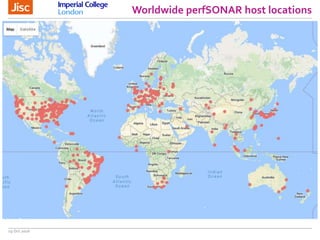
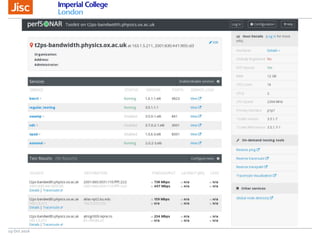
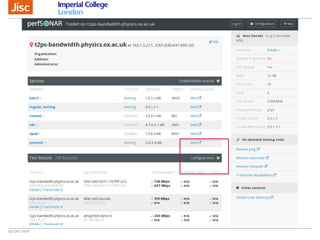
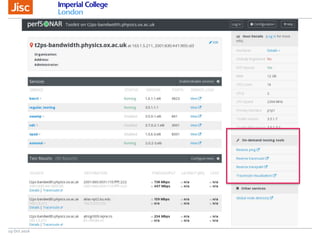
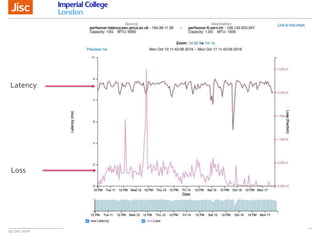
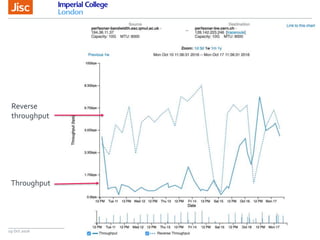
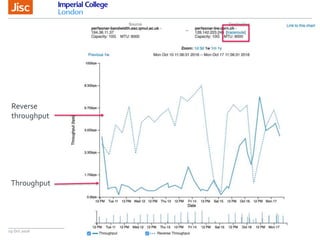
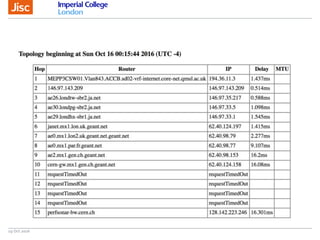
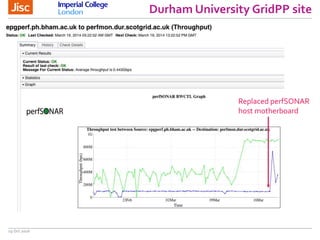
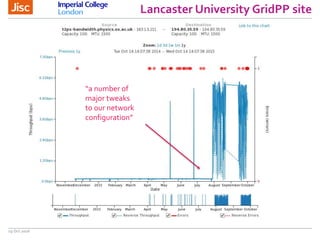
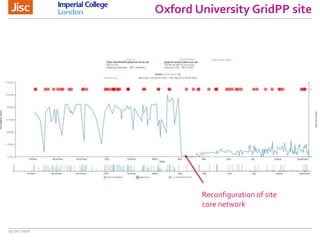

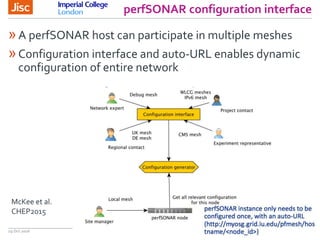

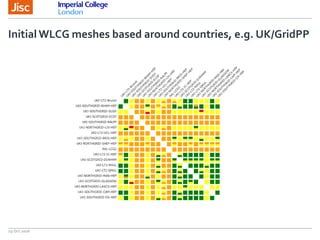
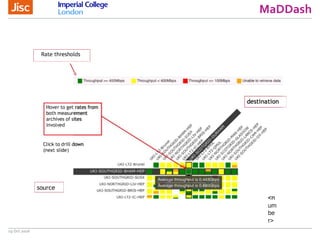
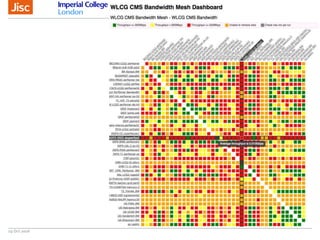



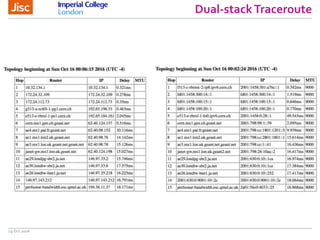
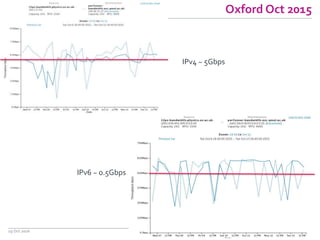
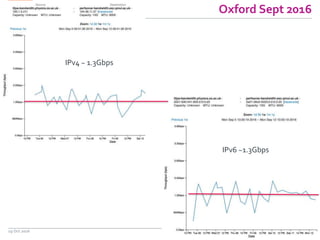

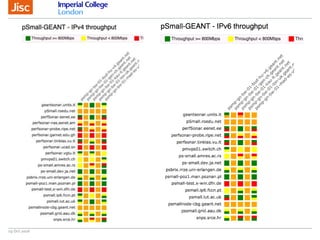
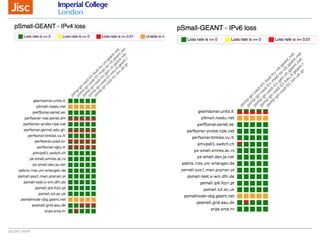




The document discusses the Worldwide Large Hadron Collider Computing Grid (WLCG) and its collaborative structure for data management and analysis. It highlights the importance of the perfSONAR network monitoring tool for ensuring reliable network performance across various sites, including the configuration and visualization of data transfer. Current efforts include promoting IPv6 adoption and enhancing network diagnostics through projects like Pundit to improve fault detection and monitoring capabilities.




























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

