

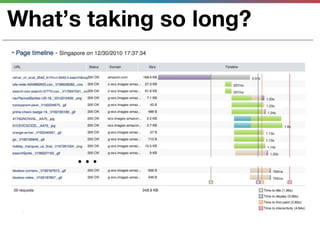
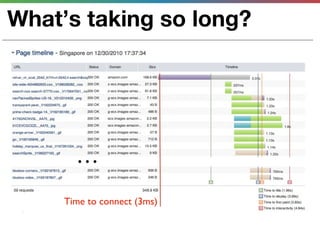
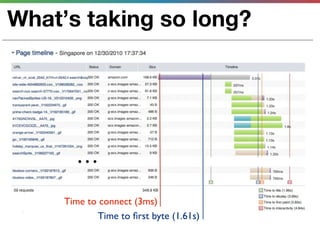
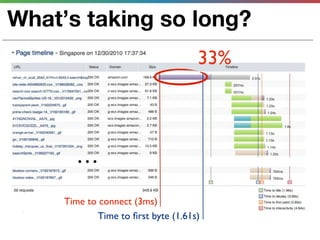
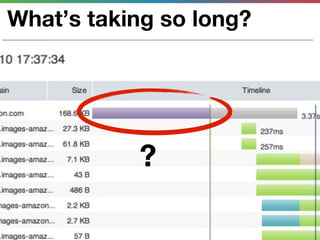



























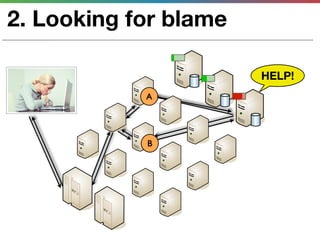
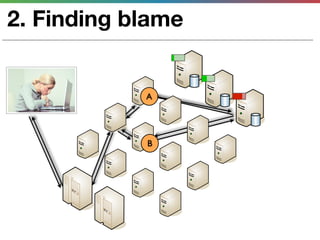
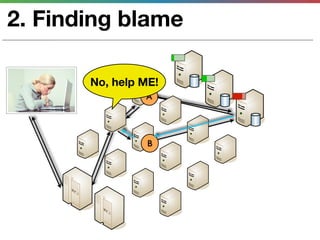








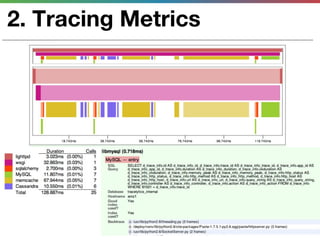




























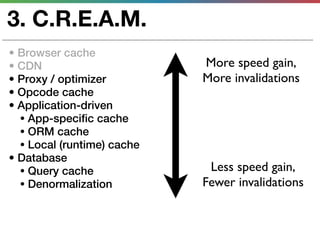

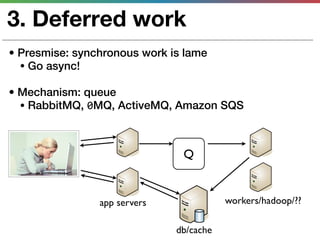

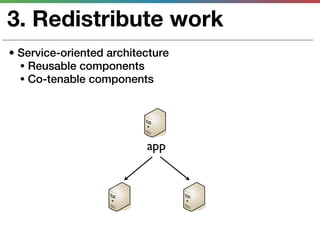


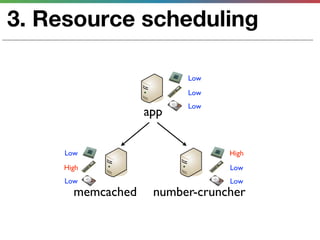
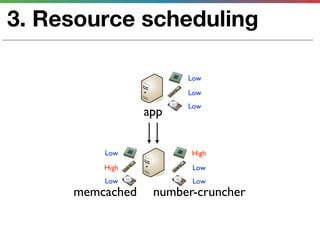









This document discusses various techniques for measuring and improving application performance. It begins by explaining the importance of measuring performance at the machine, component, and request levels. This includes collecting metrics on CPU, memory, I/O, logs, and tracing requests. Once issues are identified, the document recommends actions like caching, queueing work, and rearchitecting systems using service-oriented principles to improve performance. It stresses the importance of an ongoing process of measuring, analyzing data, taking action, and verifying the impact of changes.



























