Downloaded 15 times













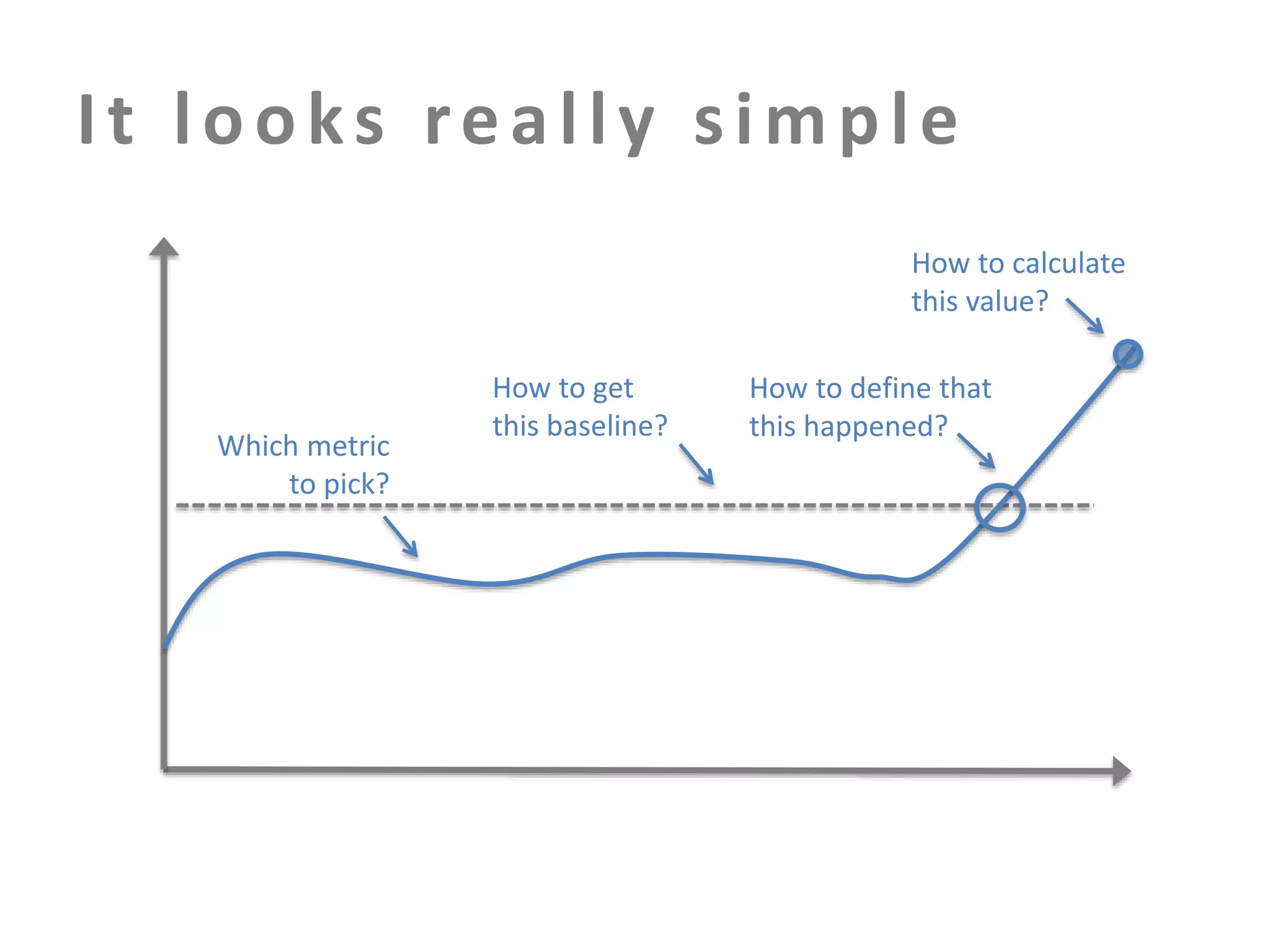









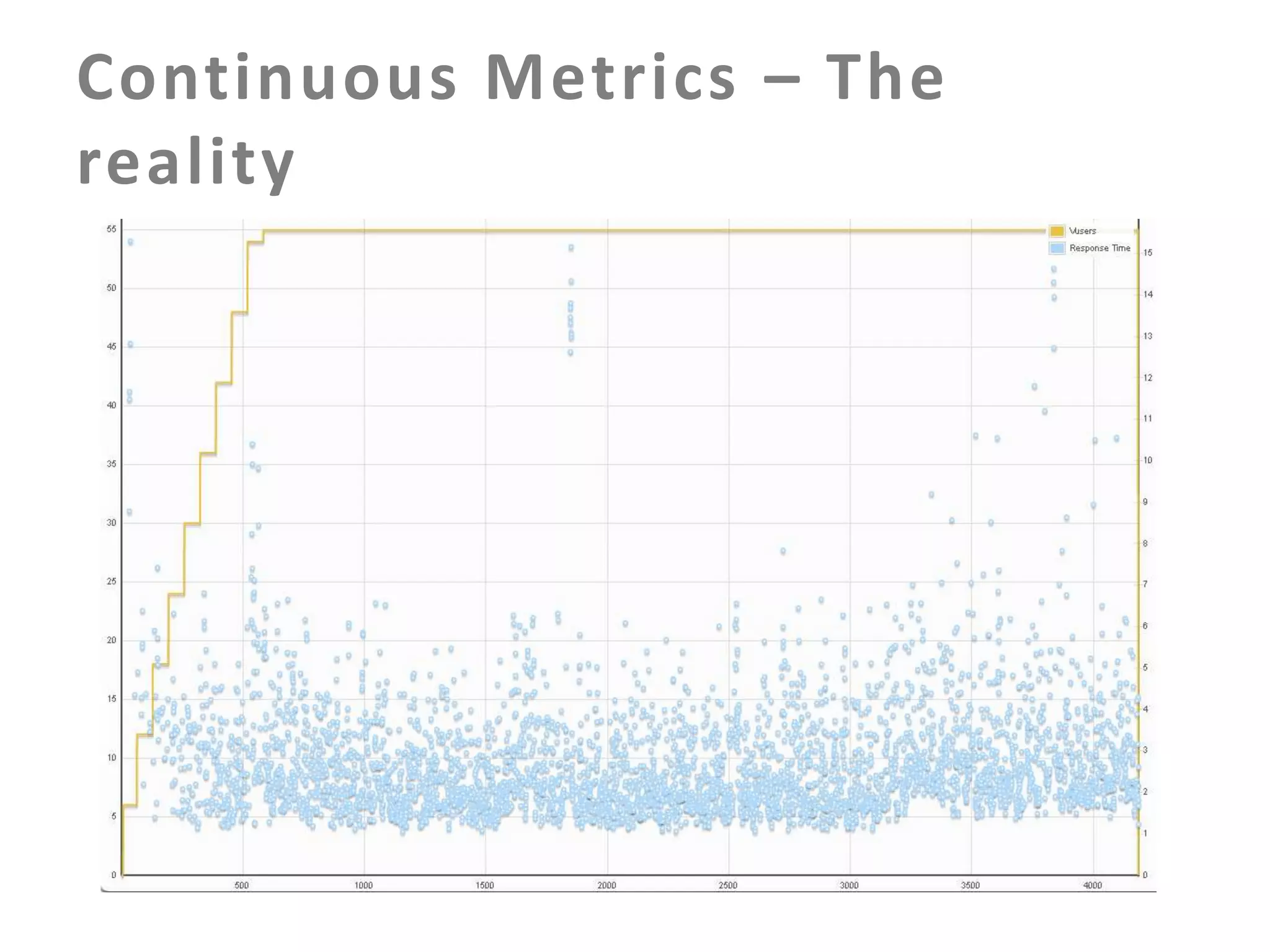
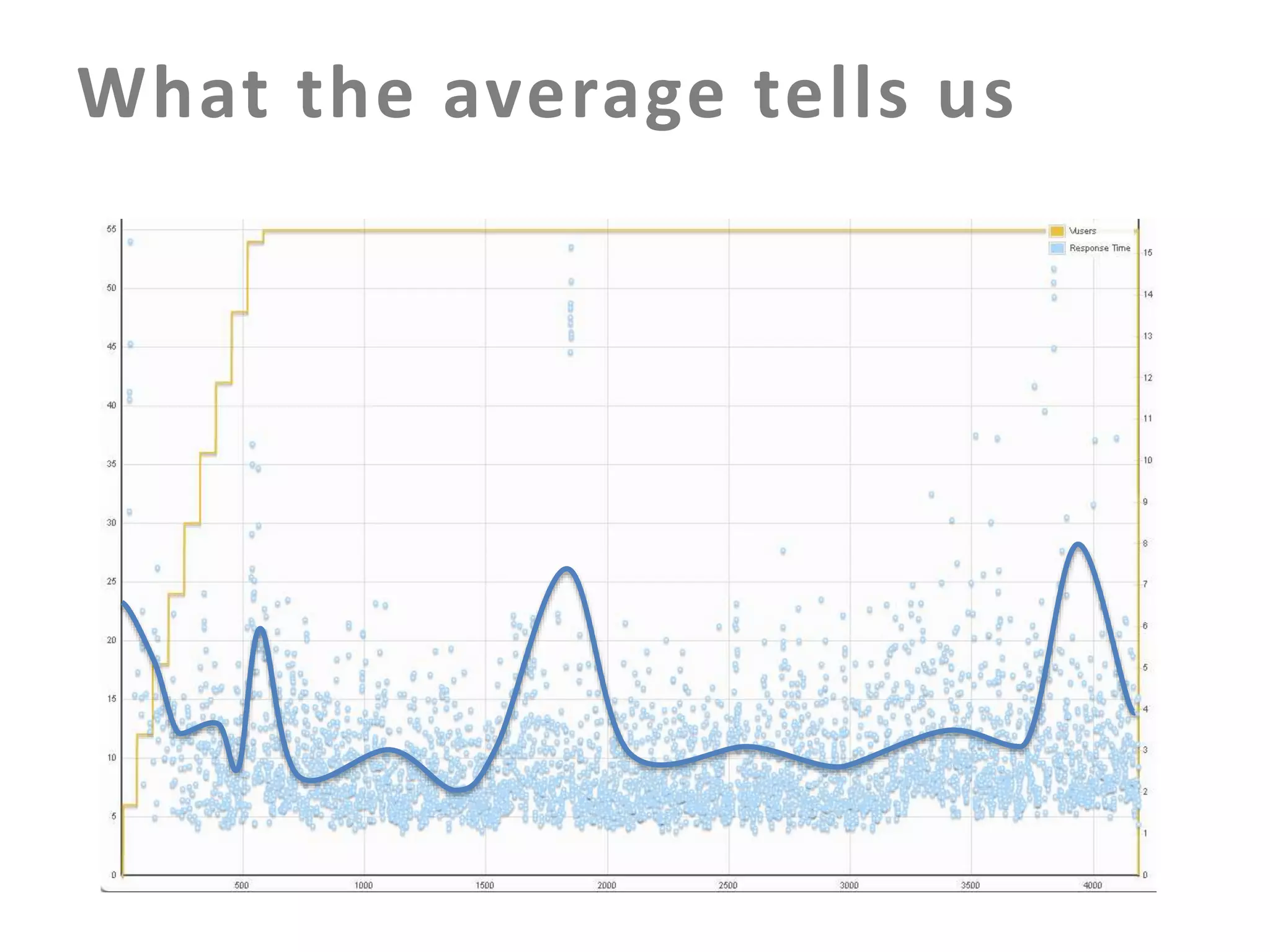
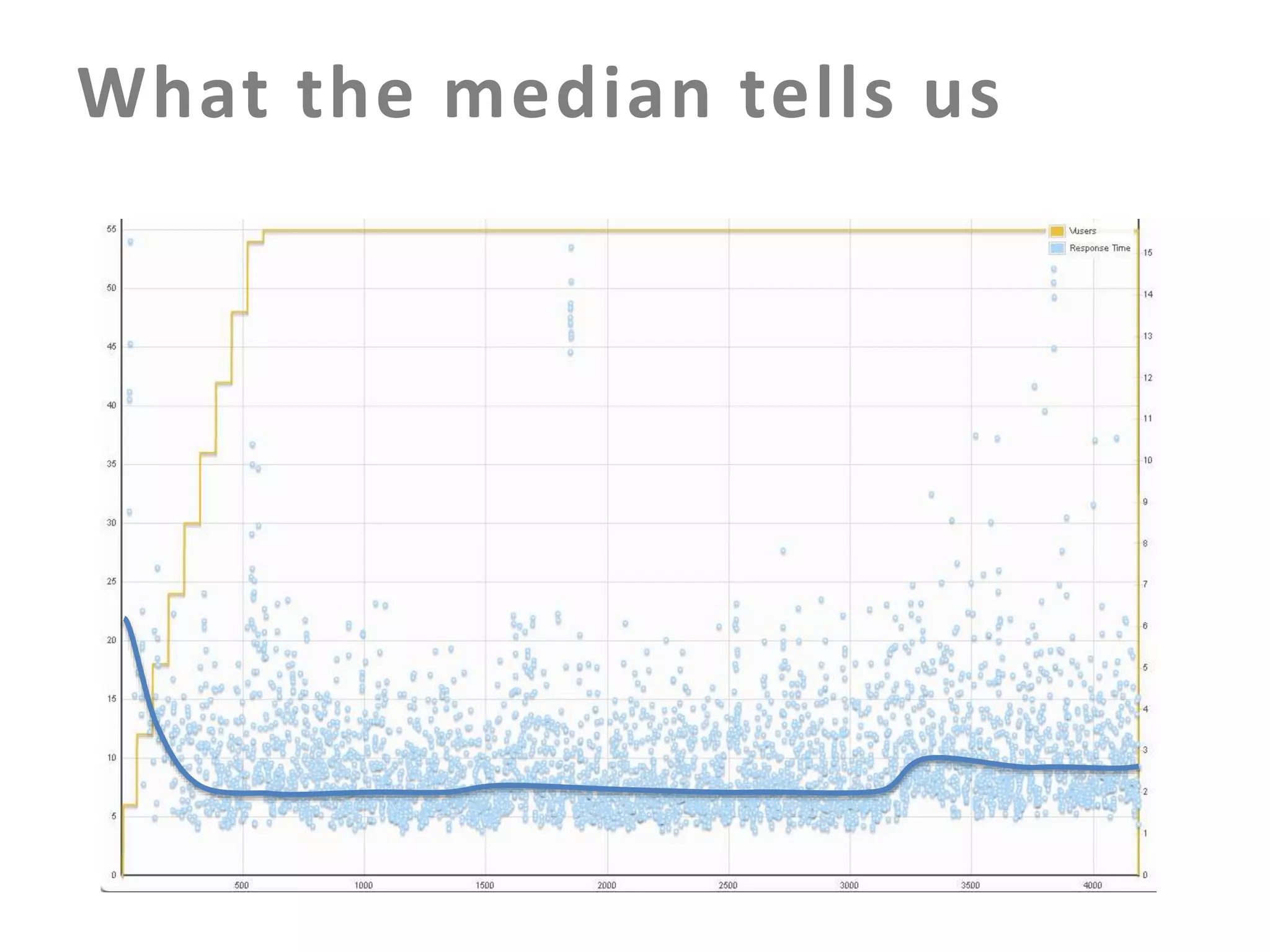


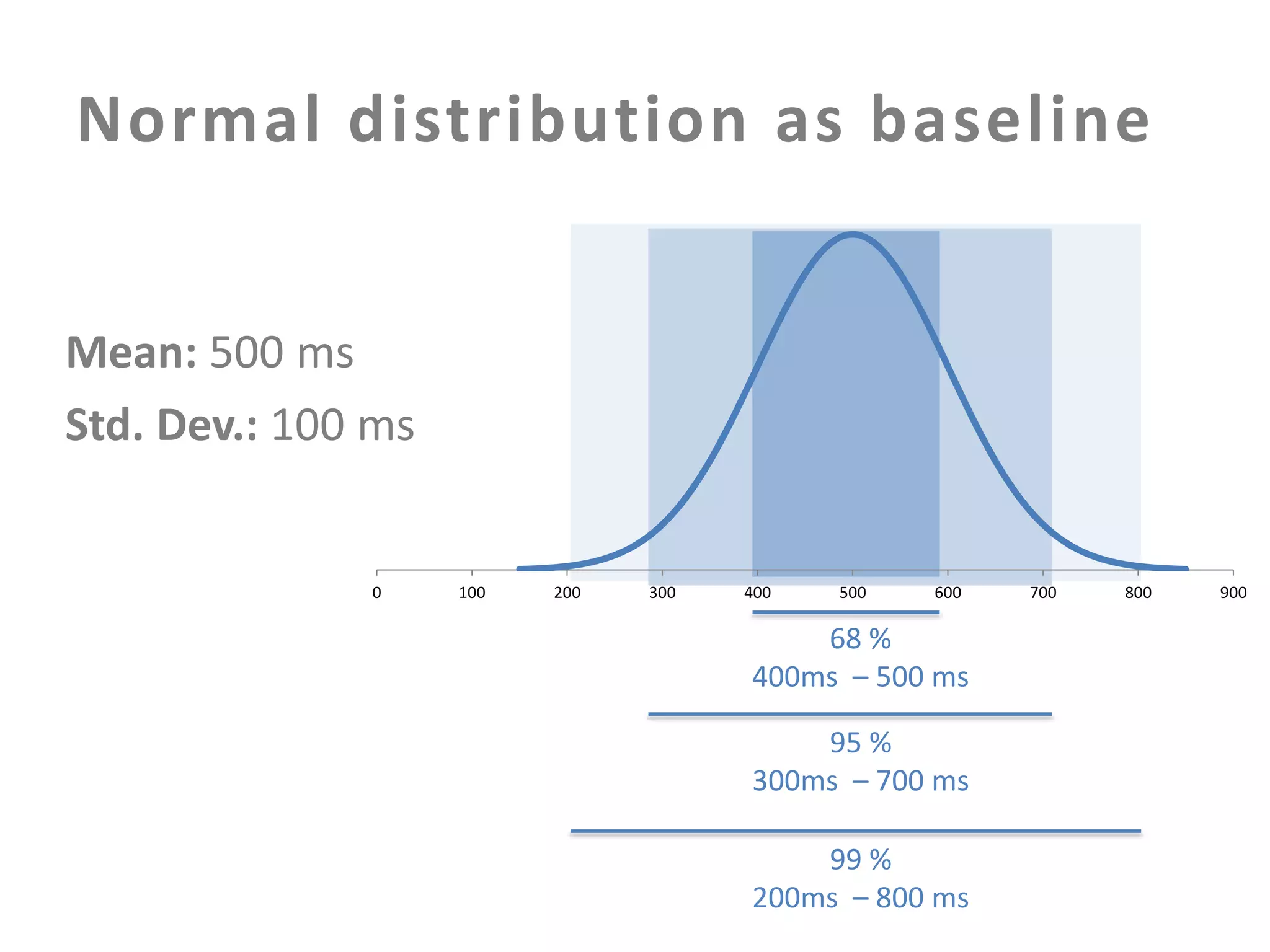


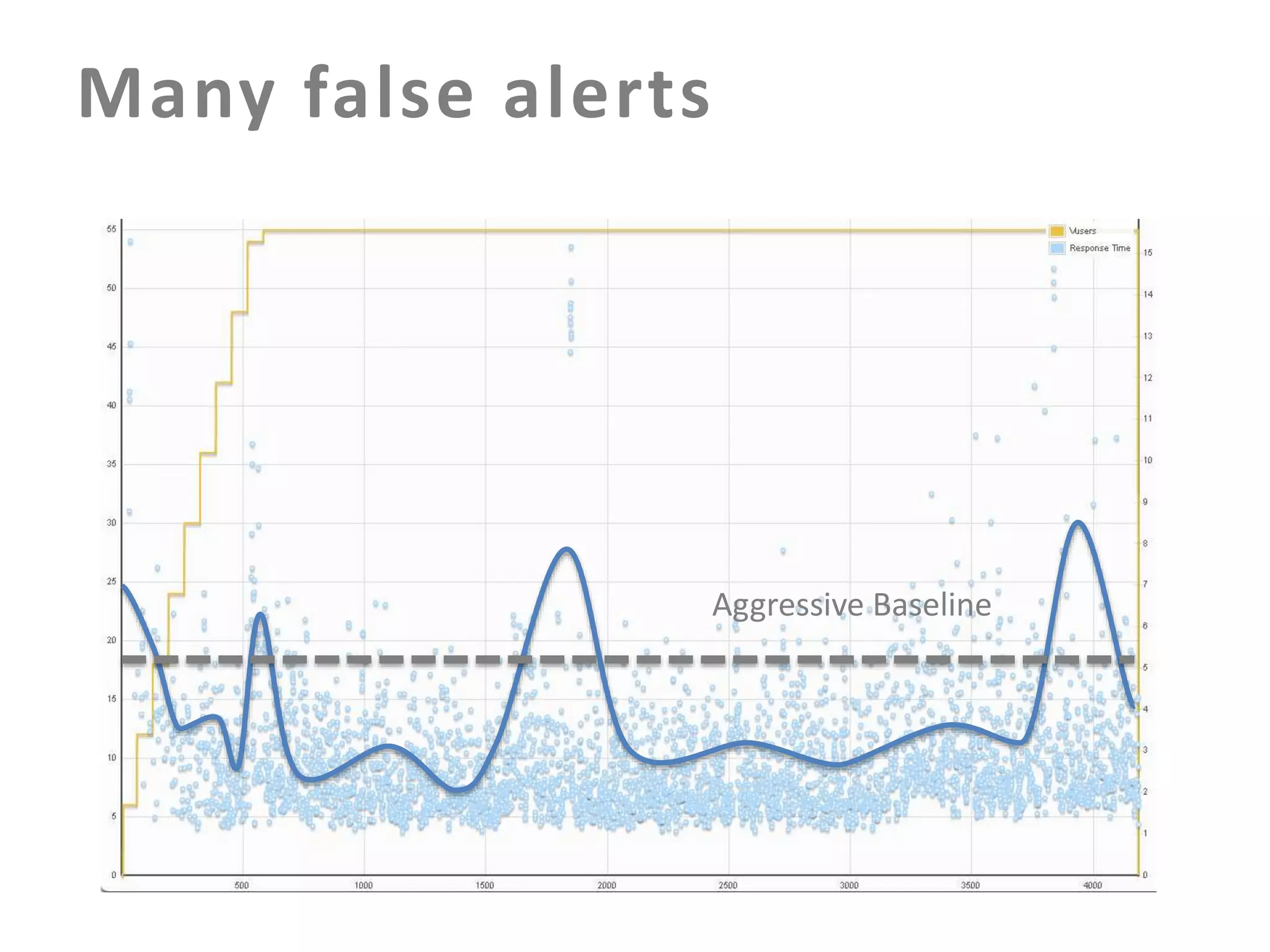
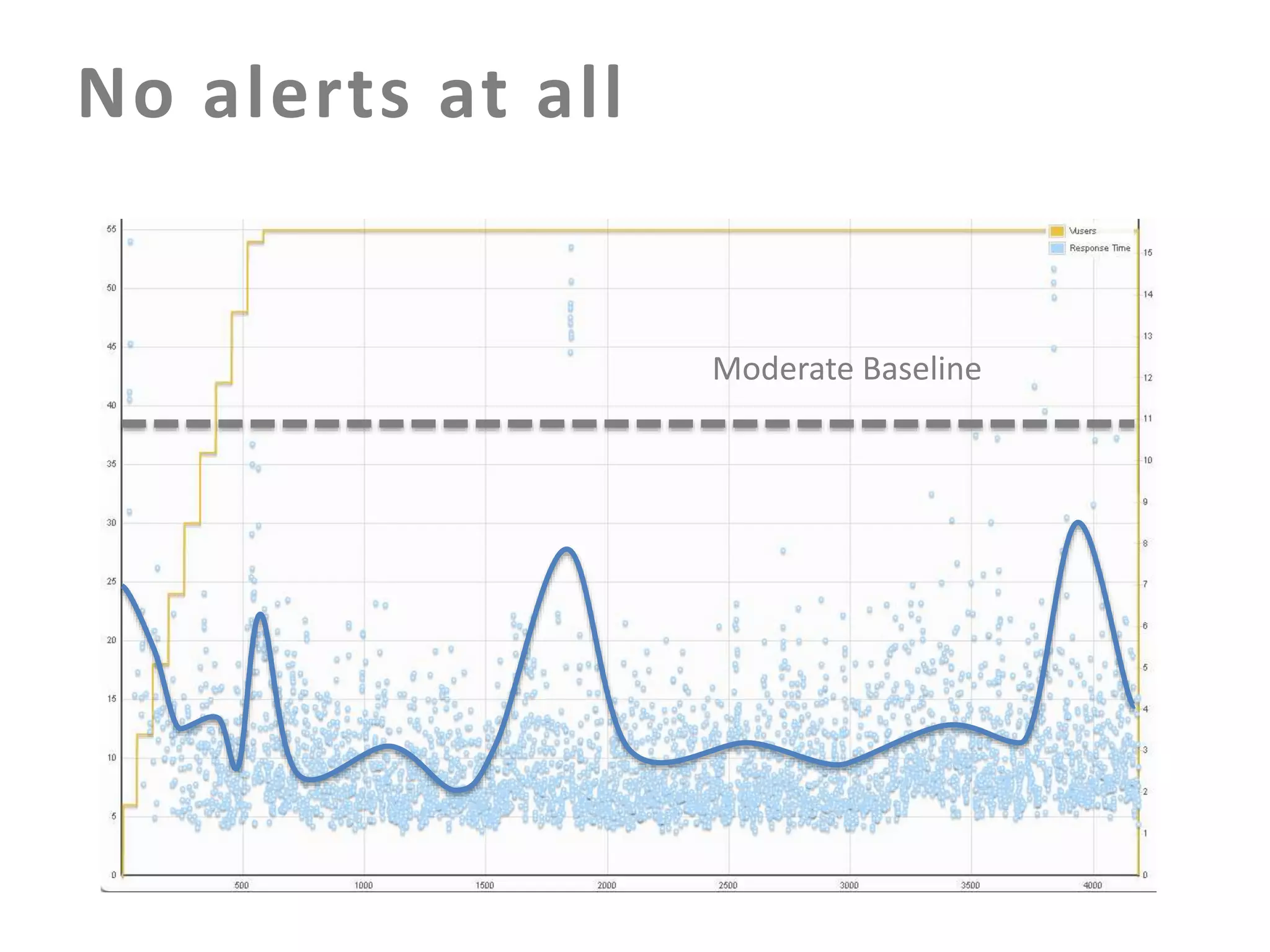

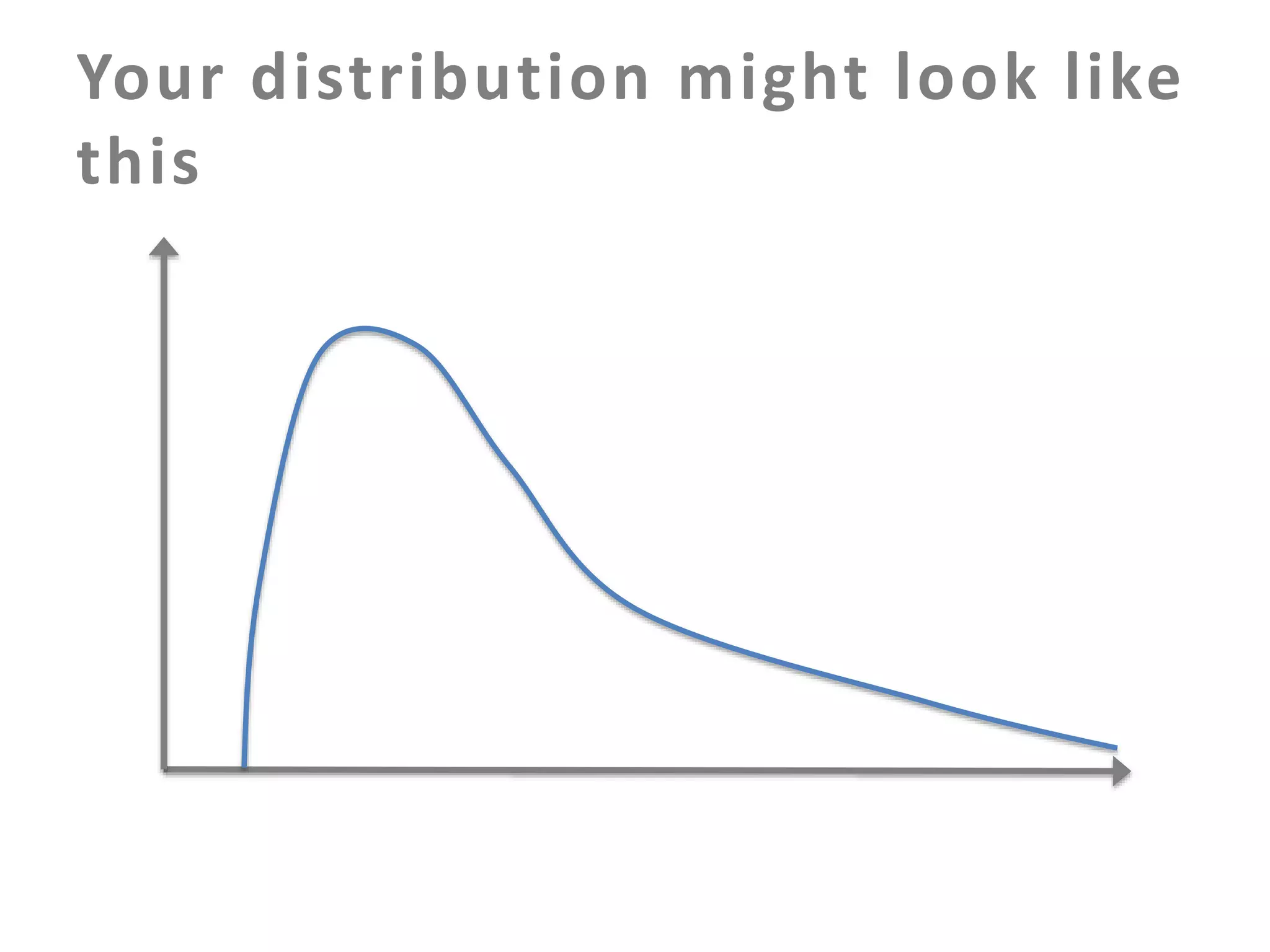
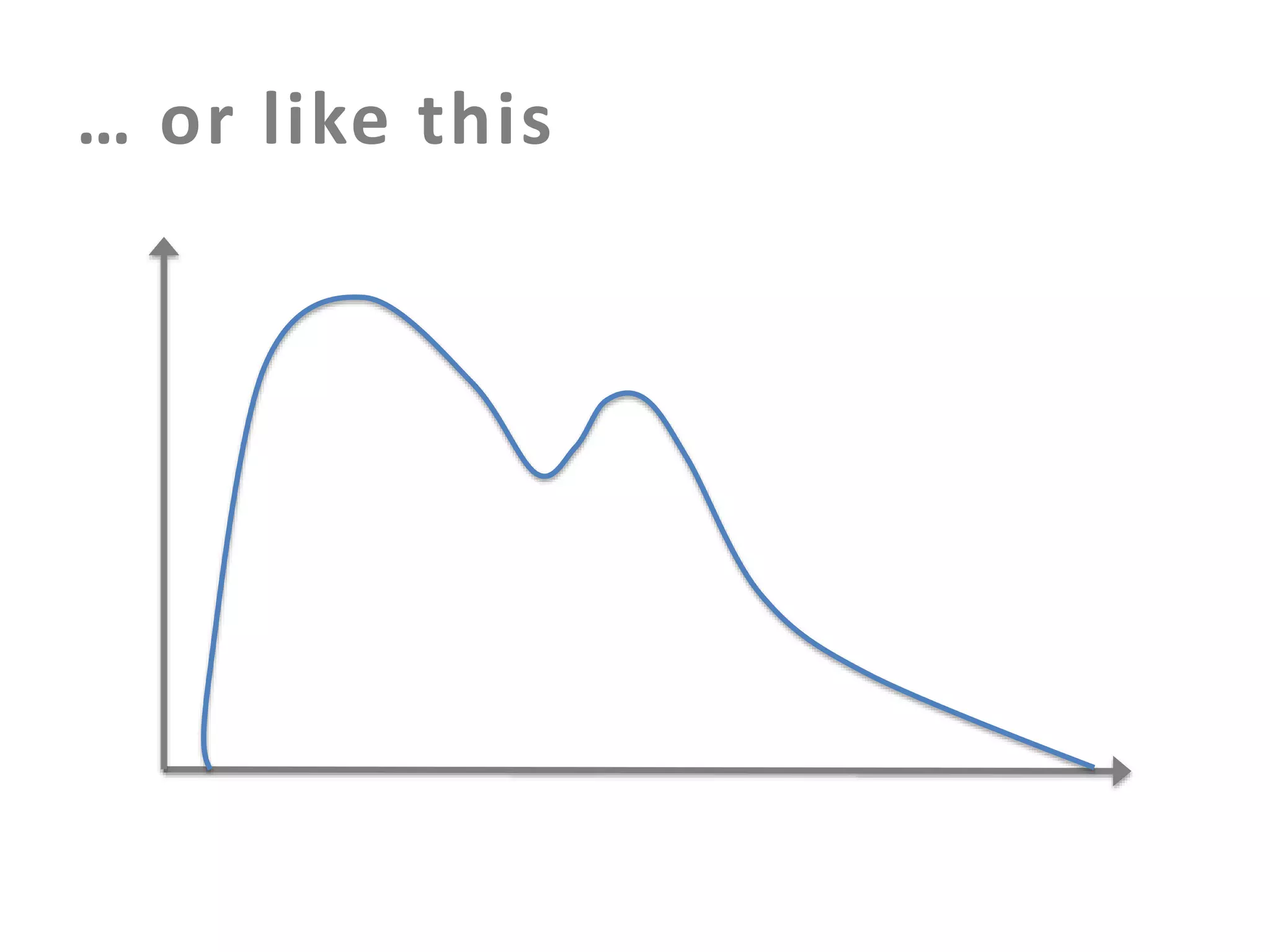


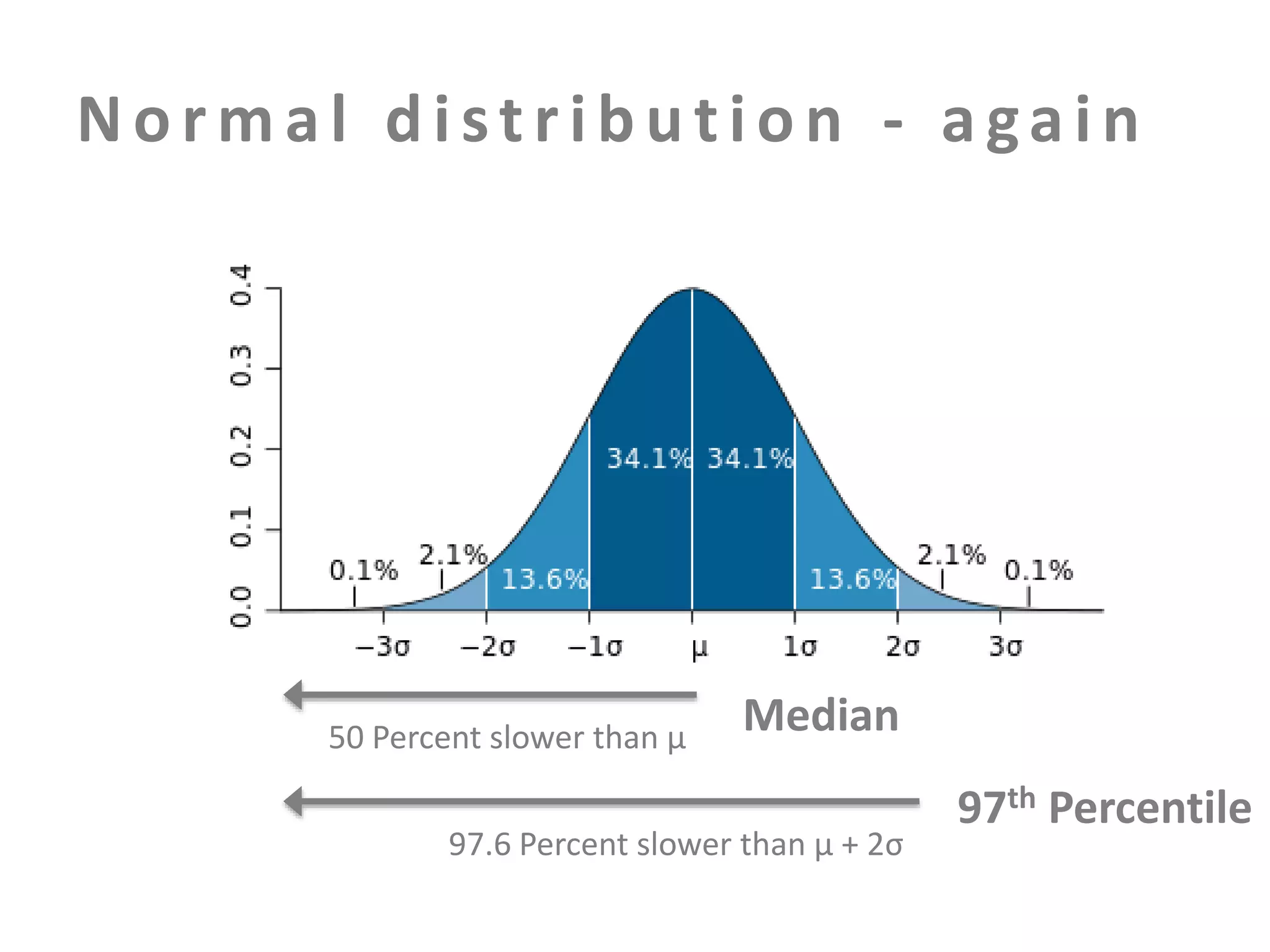

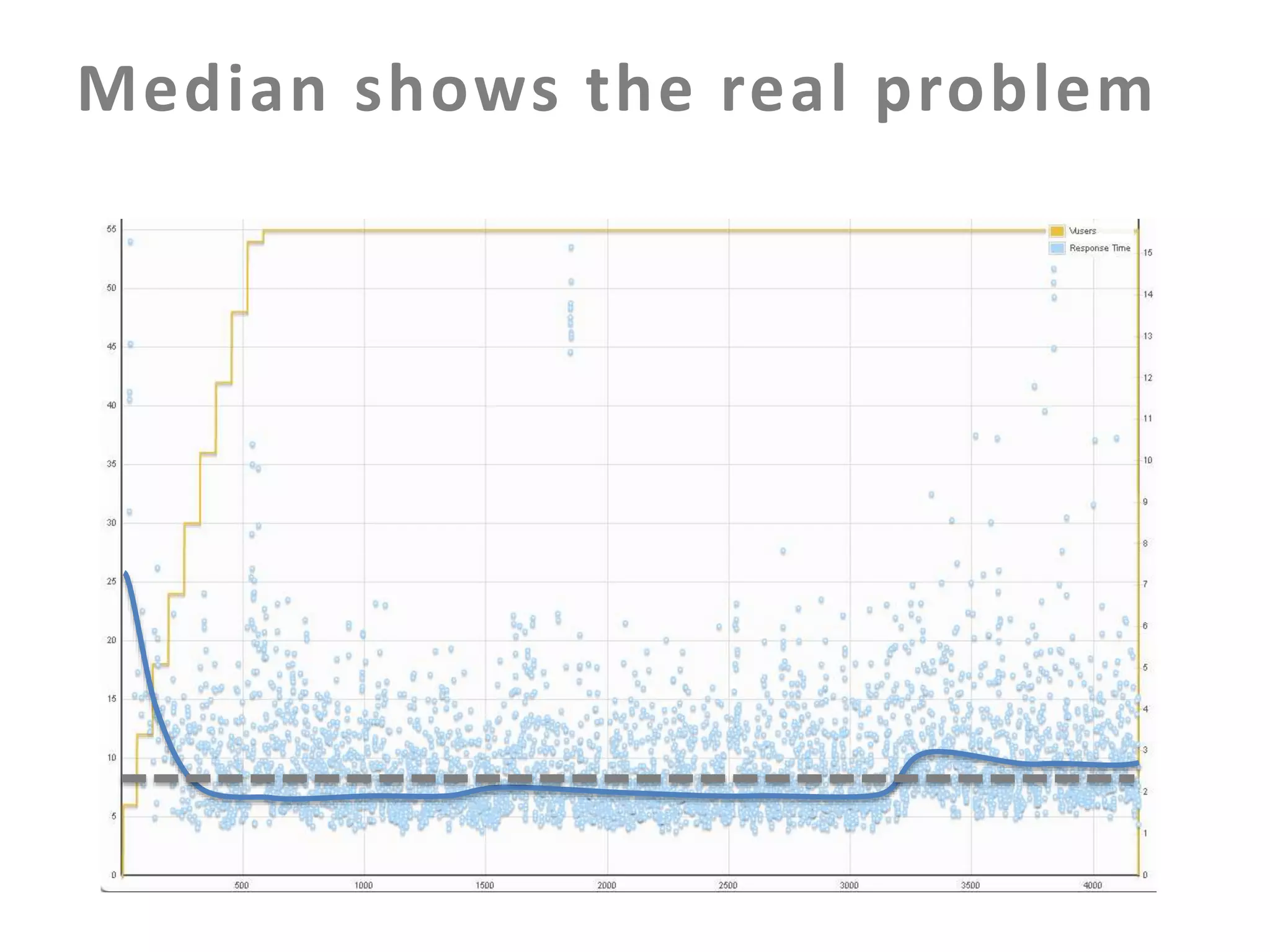







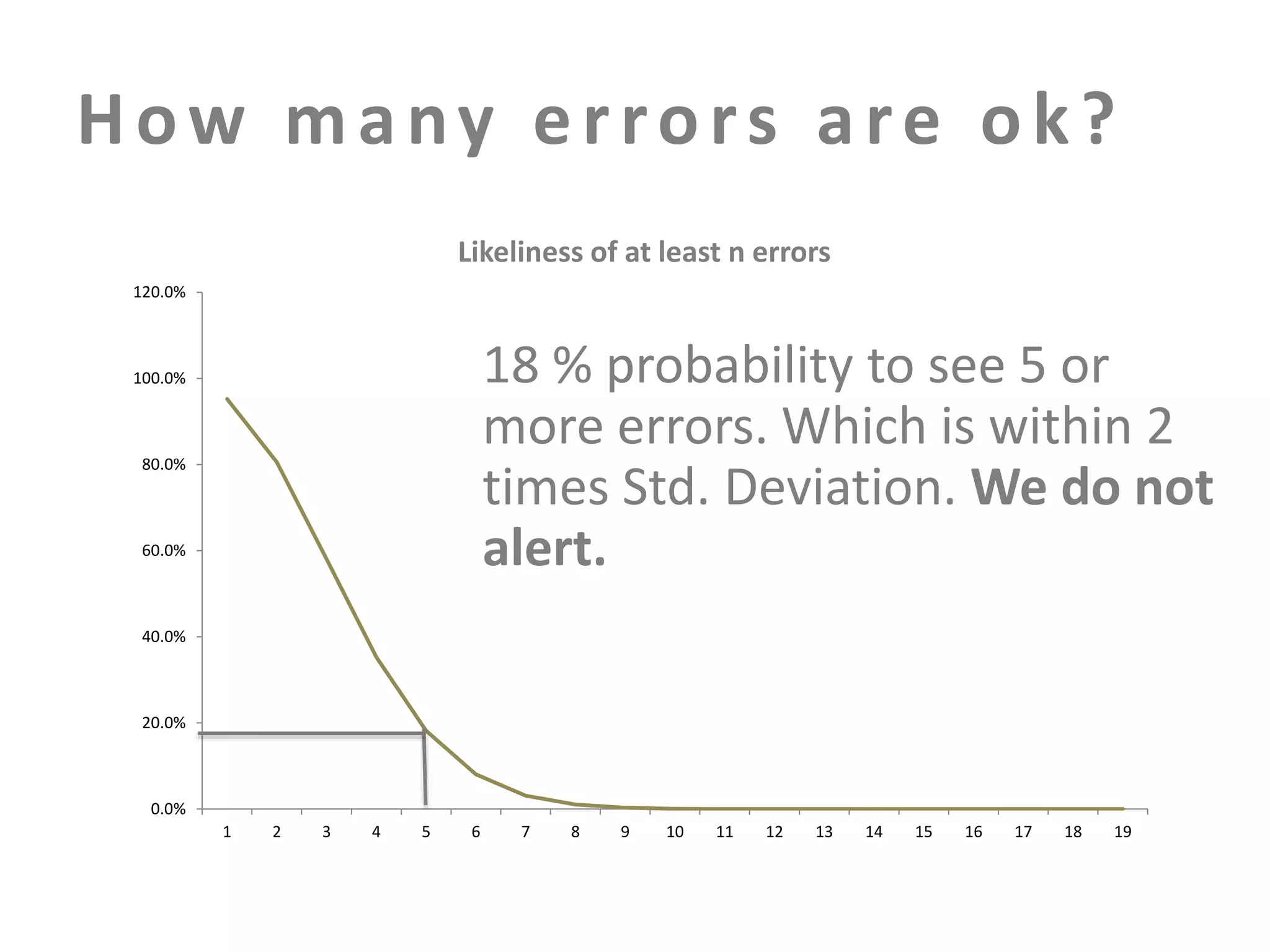




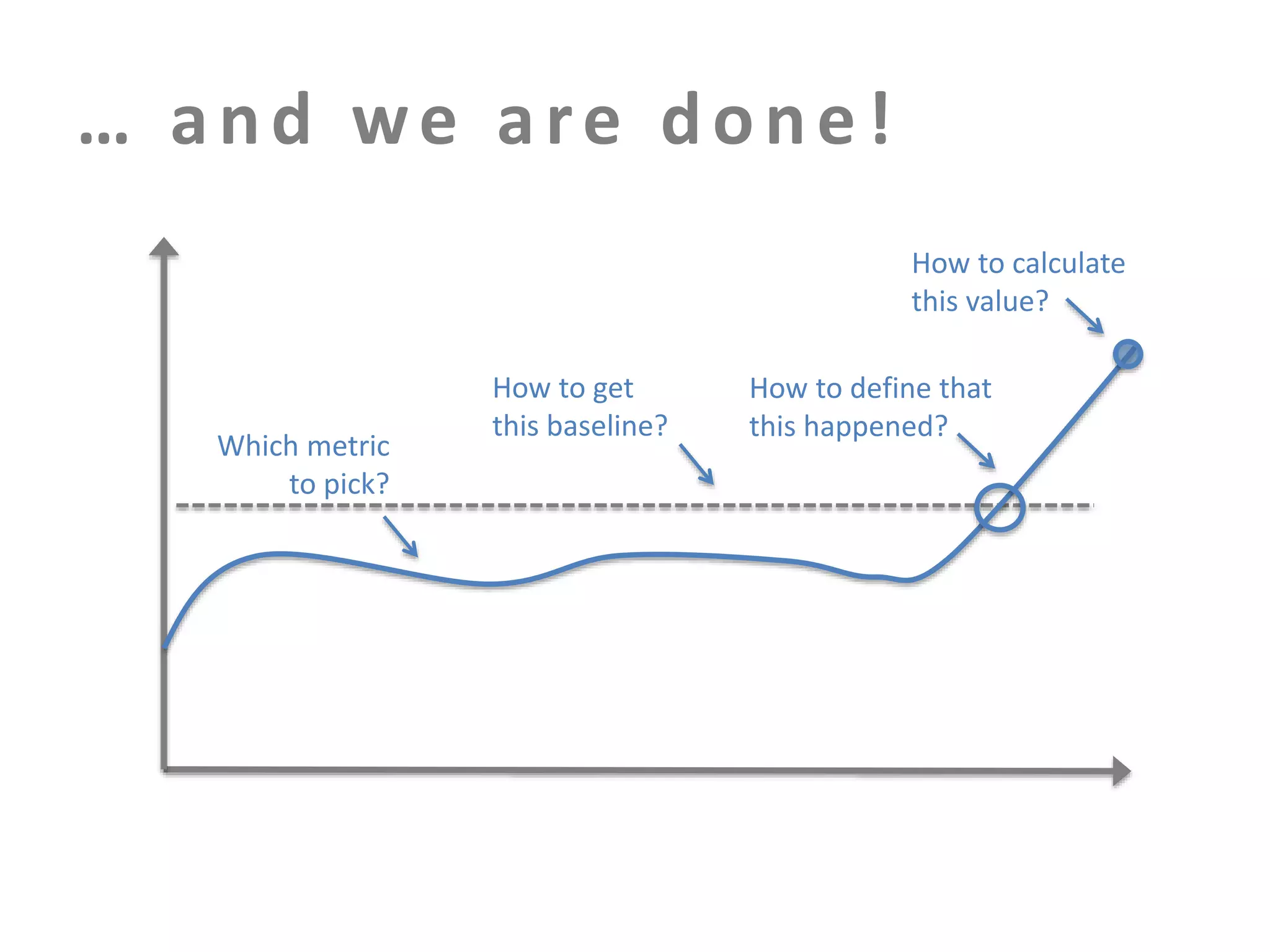




The document discusses building an effective production incident system using statistics. It explains that using the median and percentiles to define a baseline range captures normal system behavior better than trying to fit a specific distribution model. Two examples are provided: 1) Using the binomial distribution to determine if an error rate exceeds expectations. 2) Using percentiles to check if response times have drifted above the median without knowing the underlying distribution. The key is applying statistical methods to objectively determine what constitutes a normal range of values versus a problem requiring alerting.























































































