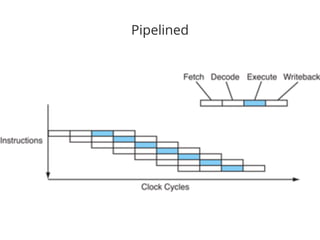
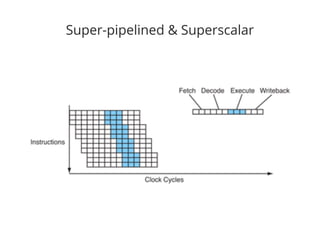
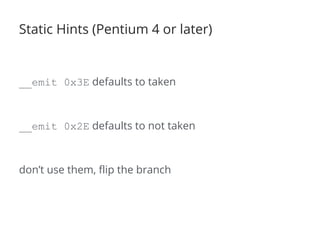
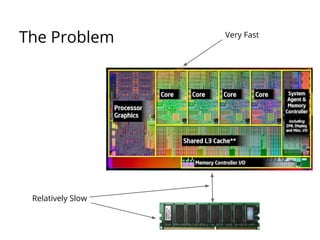
The document discusses the importance of low-level performance optimizations in software design, emphasizing how branch prediction and memory access patterns affect CPU efficiency. It outlines strategies for minimizing stalls caused by branches, optimizing cache usage, and improving data locality to enhance overall performance. Additionally, it compares traditional hard disk limitations with SSD advantages, urging developers to consider hardware characteristics when designing software.












































![Primitive Arrays
// Sequential Access = Predictable
for (int i=0; i<someArray.length; i++)
someArray[i]++;](https://image.slidesharecdn.com/performanceandpredictability-140430055652-phpapp02/85/Performance-and-predictability-49-320.jpg)
![Primitive Arrays - Skipping Elements
// Holes Hurt
for (int i=0; i<someArray.length; i += SKIP)
someArray[i]++;](https://image.slidesharecdn.com/performanceandpredictability-140430055652-phpapp02/85/Performance-and-predictability-50-320.jpg)
![Multidimensional Arrays
Multidimensional Arrays are really Arrays of
Arrays in Java. (Unlike C)
Some people realign their accesses:
for (int col=0; col<COLS; col++) {
for (int row=0; row<ROWS; row++) {
array[ROWS * col + row]++;
}
}](https://image.slidesharecdn.com/performanceandpredictability-140430055652-phpapp02/85/Performance-and-predictability-52-320.jpg)
![Bad Access Alignment
Strides the wrong way, bad
locality.
array[COLS * row + col]++;
Strides the right way, good
locality.
array[ROWS * col + row]++;](https://image.slidesharecdn.com/performanceandpredictability-140430055652-phpapp02/85/Performance-and-predictability-53-320.jpg)





































![[Paper reading] Interleaving with Coroutines: A Practical Approach for Robust...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadinginterleavingwithcoroutinesapracticalapproachforrobustindexjoin-211011055753-thumbnail.jpg?width=640&height=640&fit=bounds)


















































