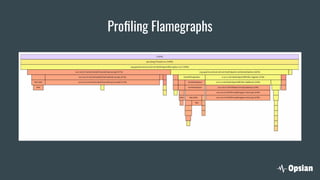
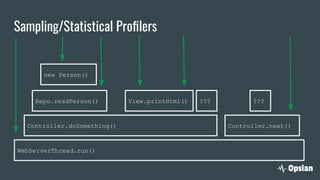
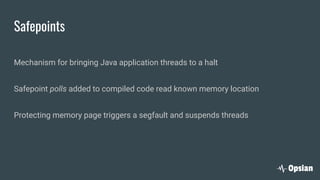
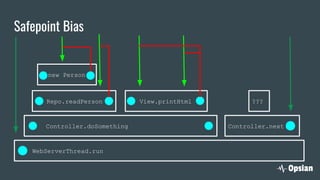
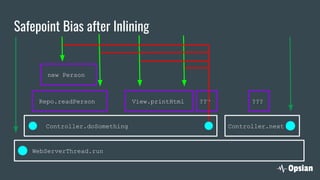
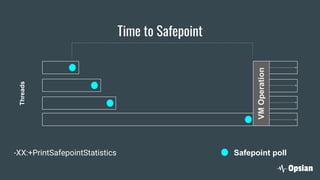
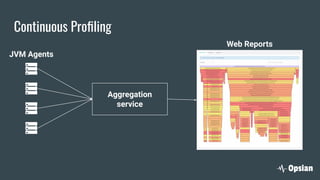
The document discusses the significance of continuous profiling in production environments, highlighting the challenges of performance tools that focus on development rather than operational realities. It outlines the methods and techniques for effective profiling, including the use of low-overhead profilers and the importance of actionable insights for troubleshooting performance issues. Continuous profiling is advocated as a proactive approach to monitoring applications, providing essential data for improve performance in real-time scenarios.



























































![[ CNCF Q1 2024 ] Intro to Continuous Profiling and Grafana Pyroscope.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/cncfq12024introtocontinuousprofilingandgrafanapyroscope-240407162420-9c15afb7-thumbnail.jpg?width=640&height=640&fit=bounds)
























































