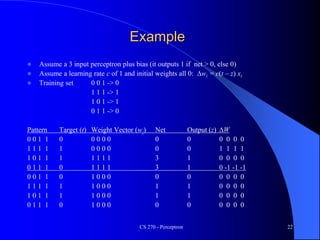
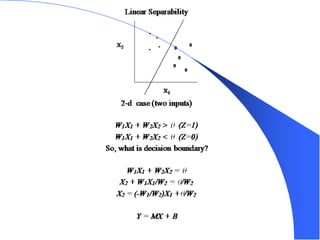
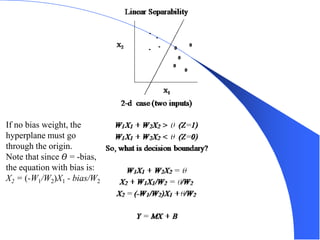
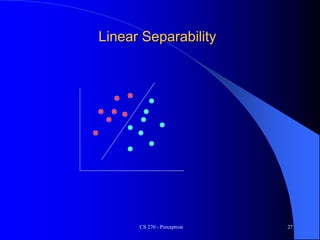
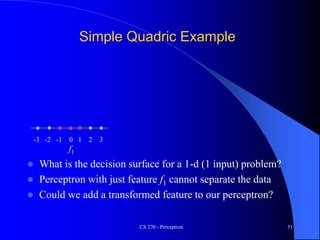
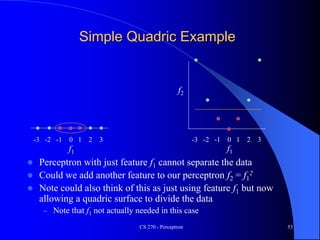
The document provides an overview of the perceptron, the first neural network learning model, developed by Frank Rosenblatt in the 1960s. It details the perceptron learning algorithm, including weight learning, the threshold logic unit, and the concept of bias in input data, while also discussing multi-class output scenarios. Additionally, it emphasizes active learning through peer instruction to enhance understanding and retention of the material.























































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)