Download as PDF, PPTX











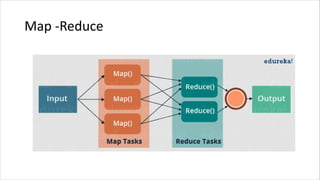
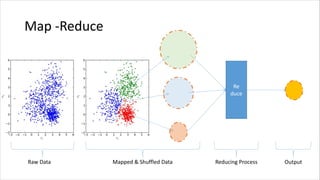
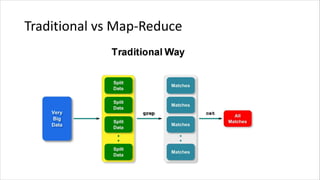
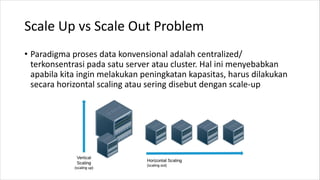

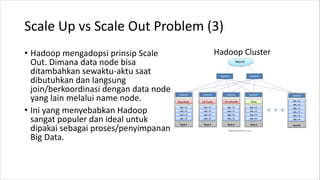
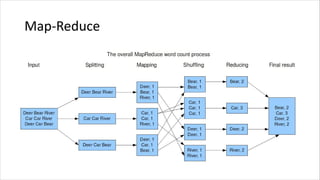
![Map-Reduce (latihan)
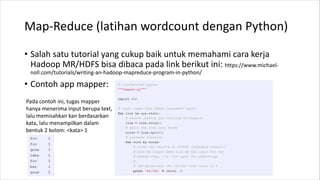
• Install Hadoop (dibutuhkan install dan konfigurasi JAVA, download
dan setting aplikasi Apache Hadoop). Untuk proses instalasi Hadoop
bisa dilihat dari berbagai sumber, salah satunya:
https://www.tutorialspoint.com/hadoop/hadoop_enviornment_setup.htm
• Pastikan Hadoop sudah jalan. Bisa coba dengan ketik hadoop version
• Untuk menjalankan contoh di hadoop (pada saat download dan
extract, ada beberapa contoh bawaan). Contohnya: hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input
output 'dfs[a-z.]+'
• Lebih jauh bisa dibaca pada beberapa sumber seperti
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html](https://image.slidesharecdn.com/introductiontobigdata-210610153127/85/Pengenalan-Big-Data-untuk-Pemula-21-320.jpg)




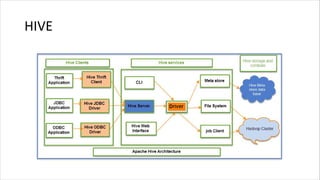

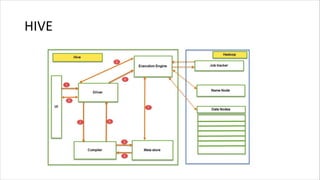



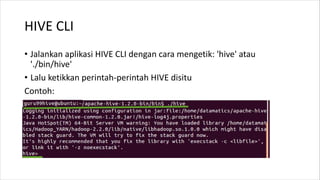
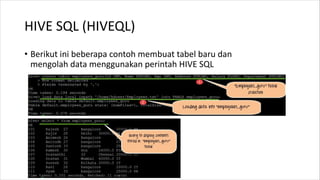

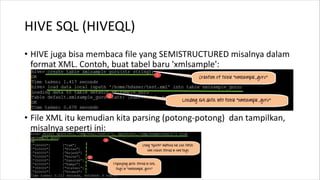



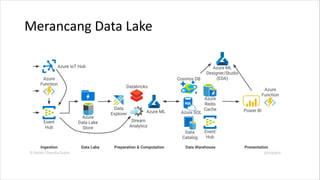
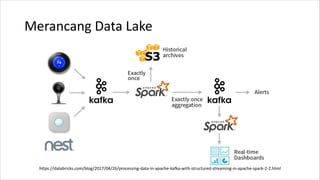


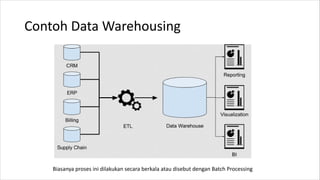
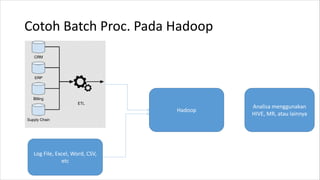
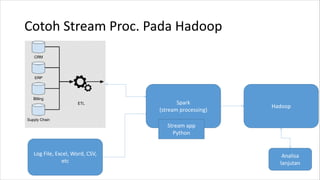

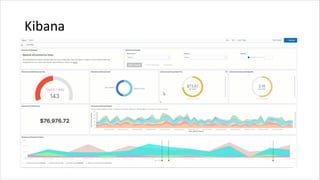
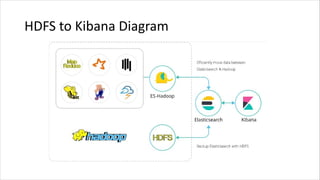
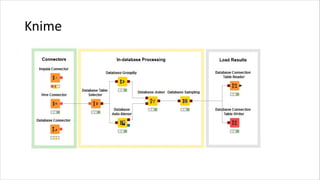

1. HIVE dibutuhkan karena dapat mengolah data besar secara terdistribusi di Hadoop. Sedangkan RDBMS biasa hanya dapat mengolah data secara terpusat. 2. Kelebihan HIVE dibandingkan RDBMS biasa antara lain: - Dapat mengolah data besar secara terdistribusi di kluster Hadoop - Tidak terikat dengan skema karena menggunakan "schema on read" - Dapat mengolah data berstruktur, semi struktur, dan tidak berstruktur



















![Sistem Penunjang Keputusan [Konsep dan Permodelan Sistem Penunjang Keputusan]](https://cdn.slidesharecdn.com/ss_thumbnails/3-190607213242-thumbnail.jpg?width=640&height=640&fit=bounds)























































