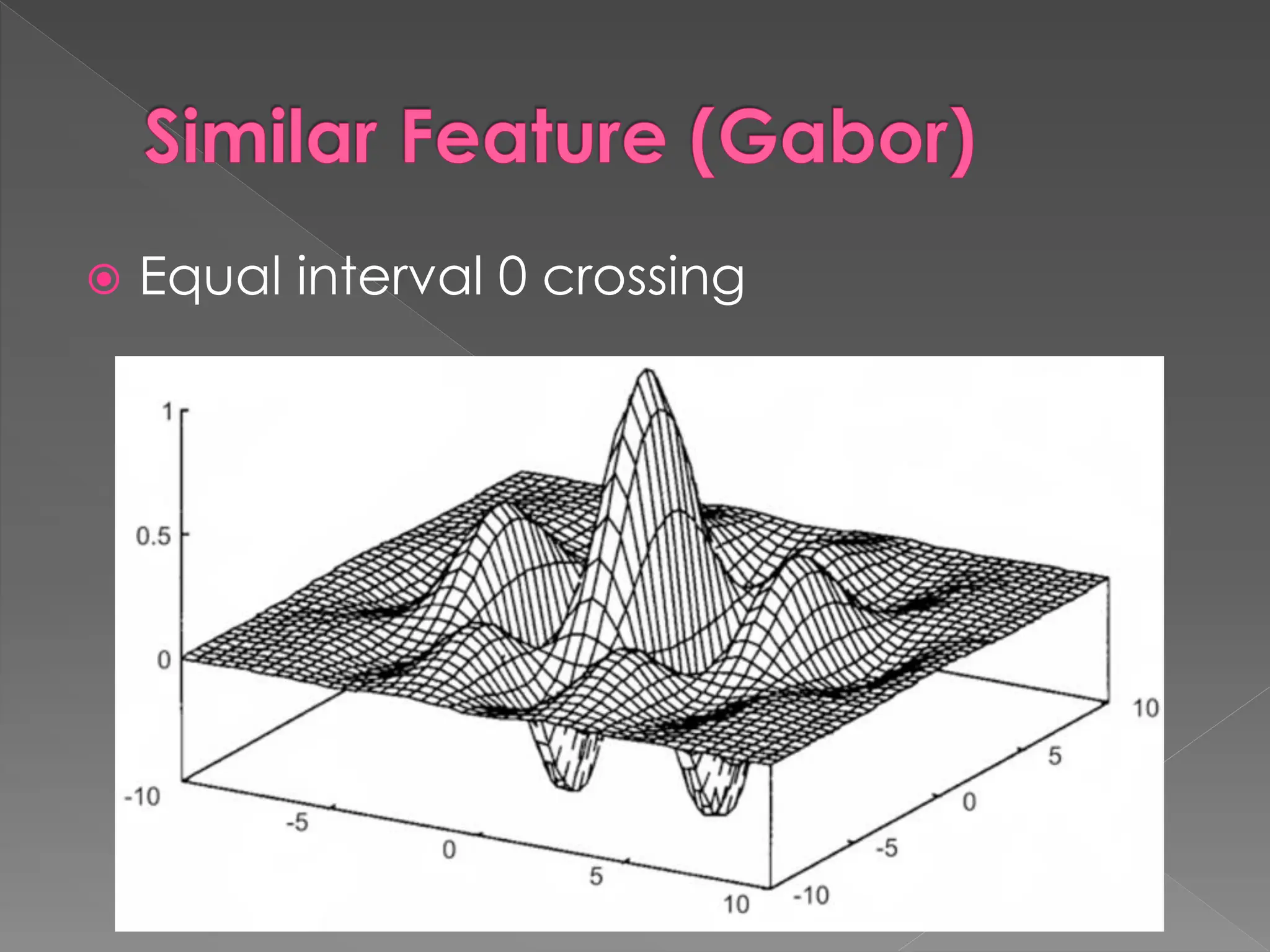
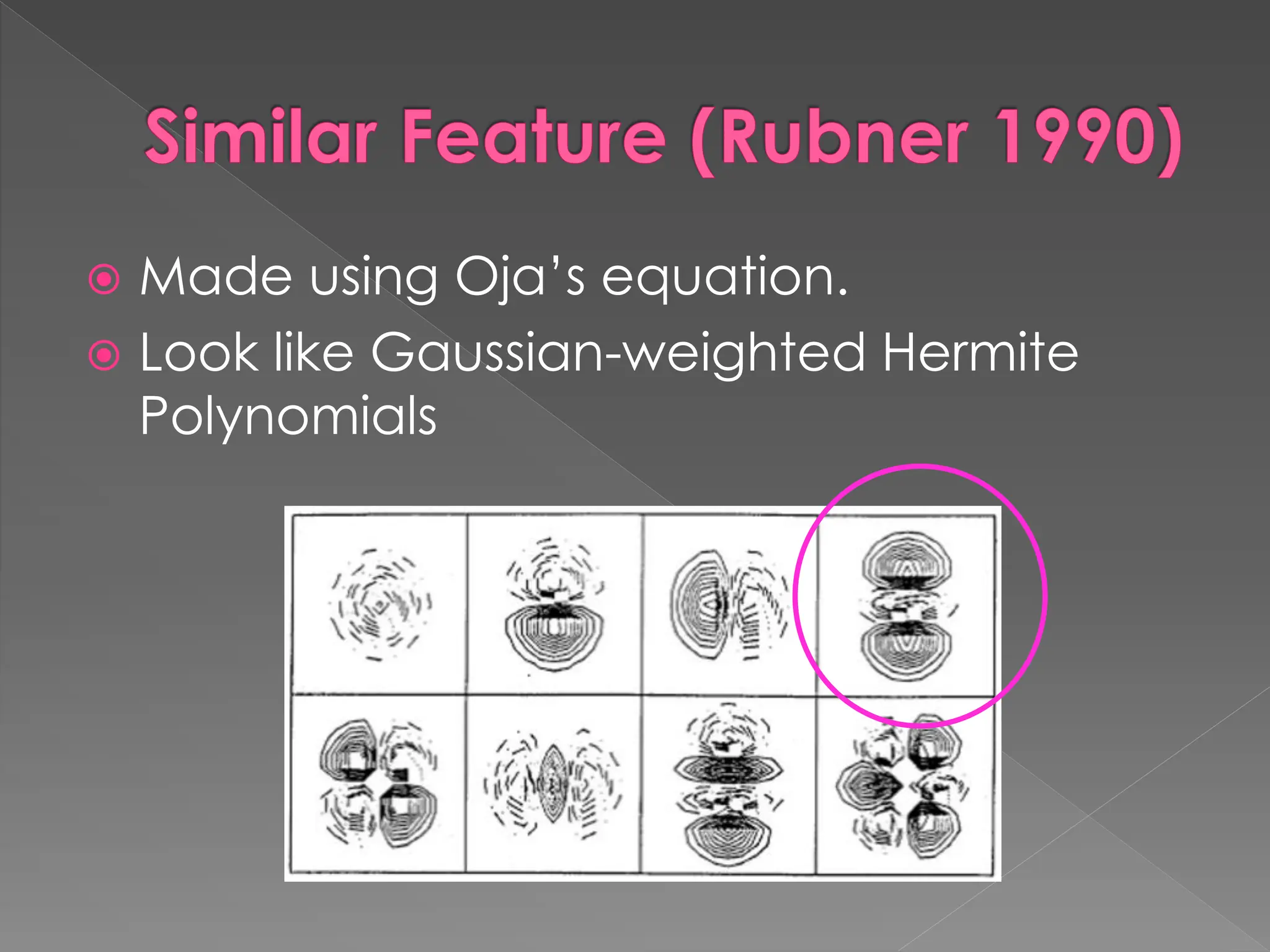
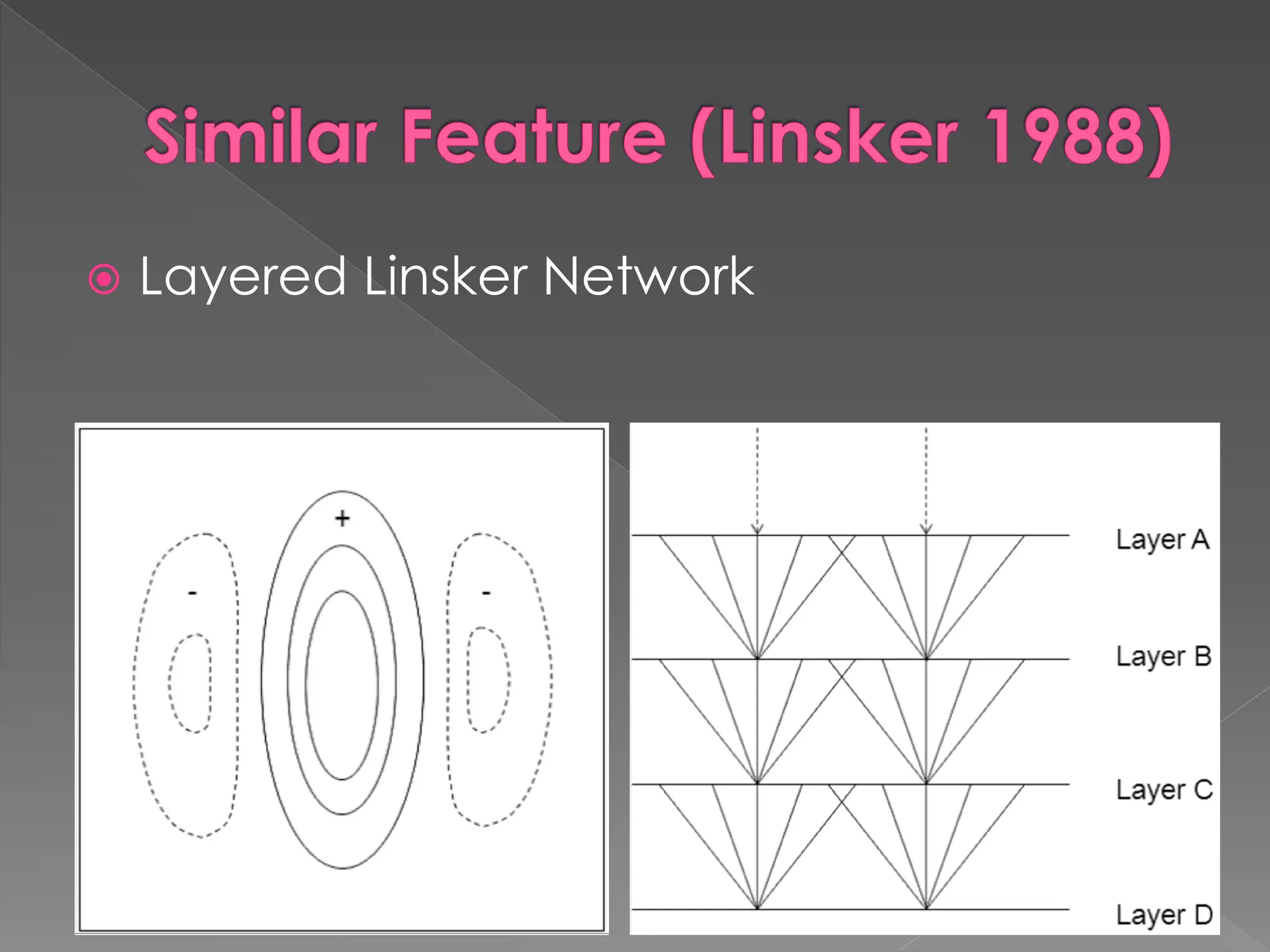
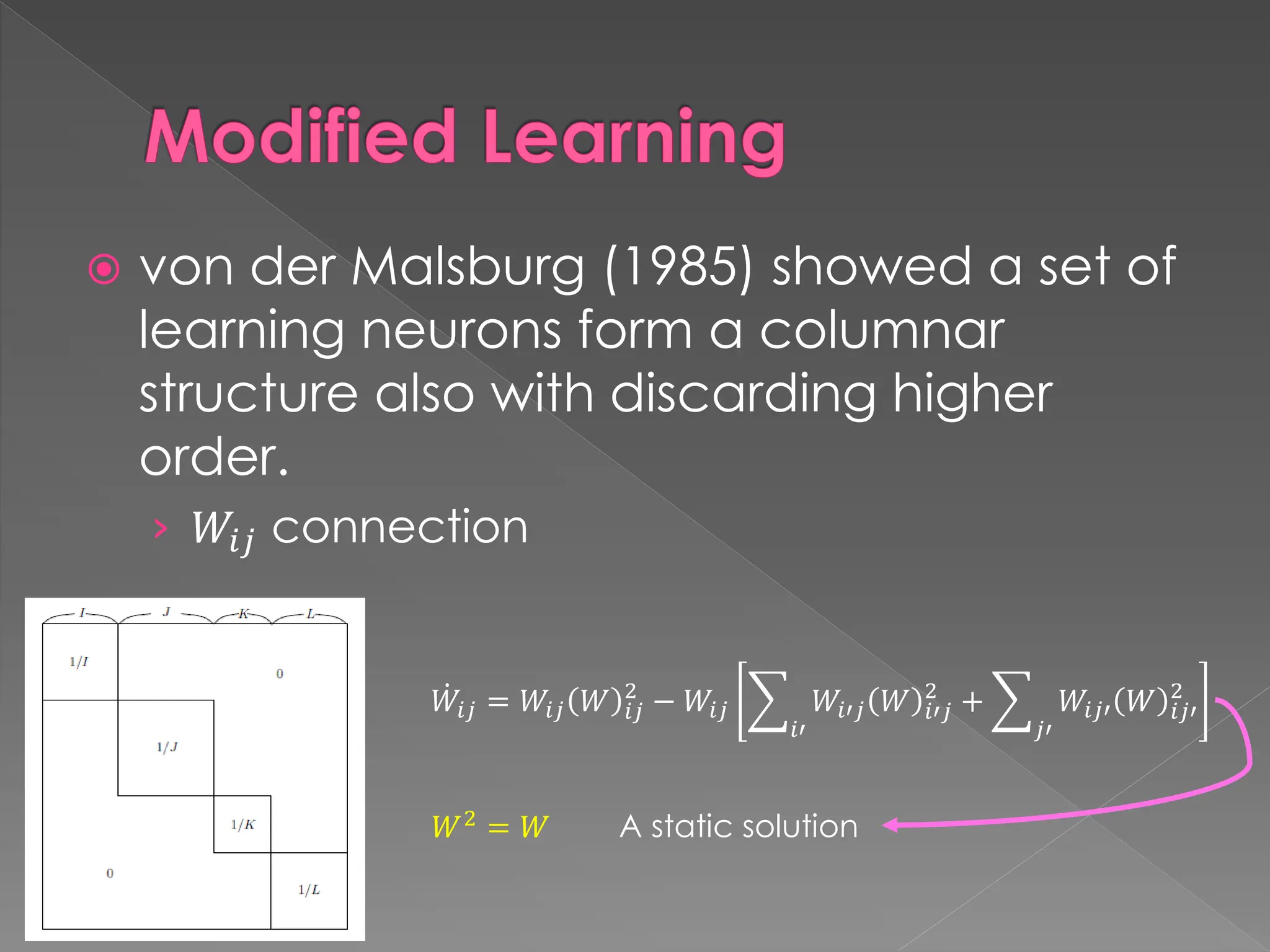
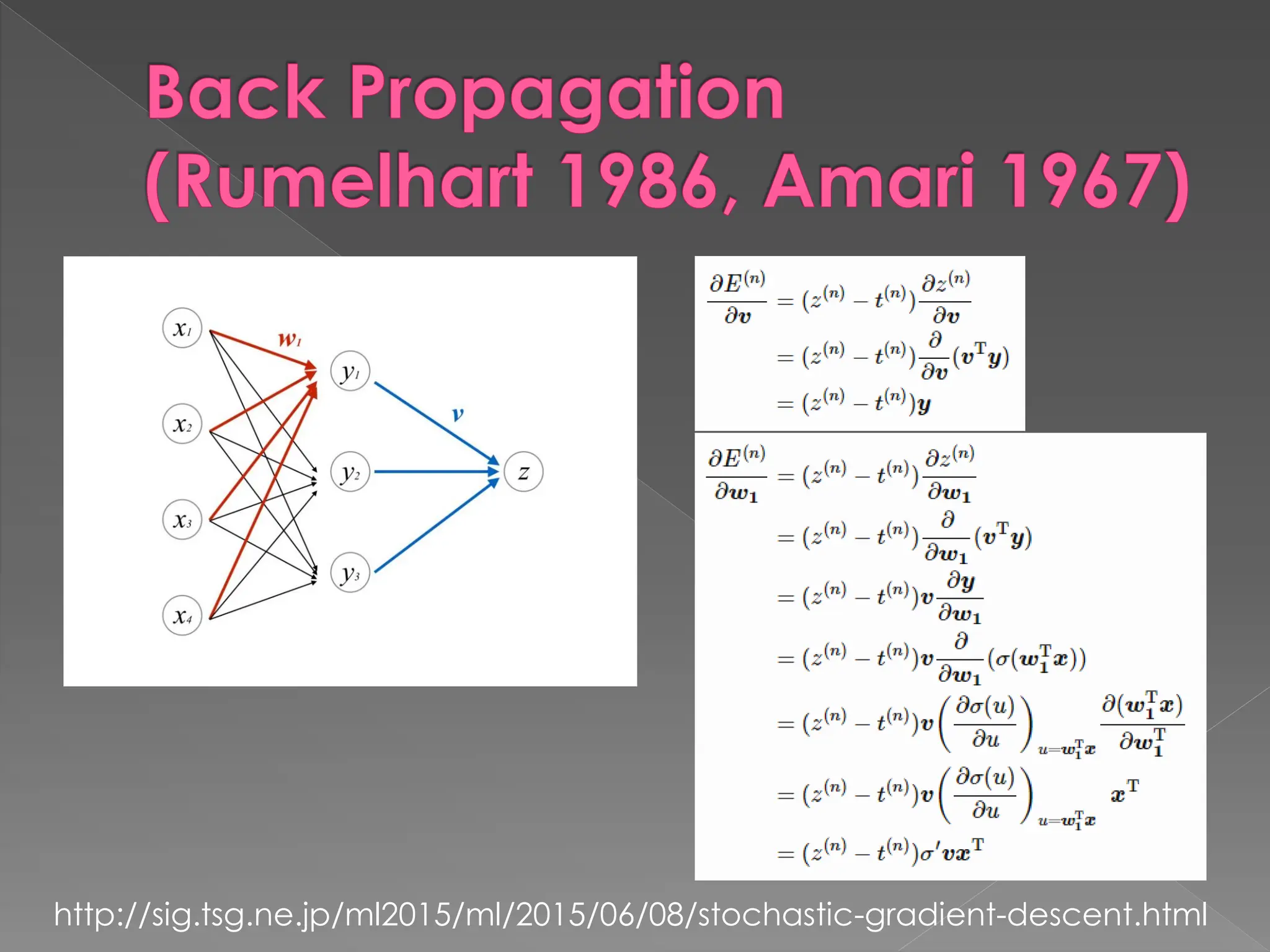
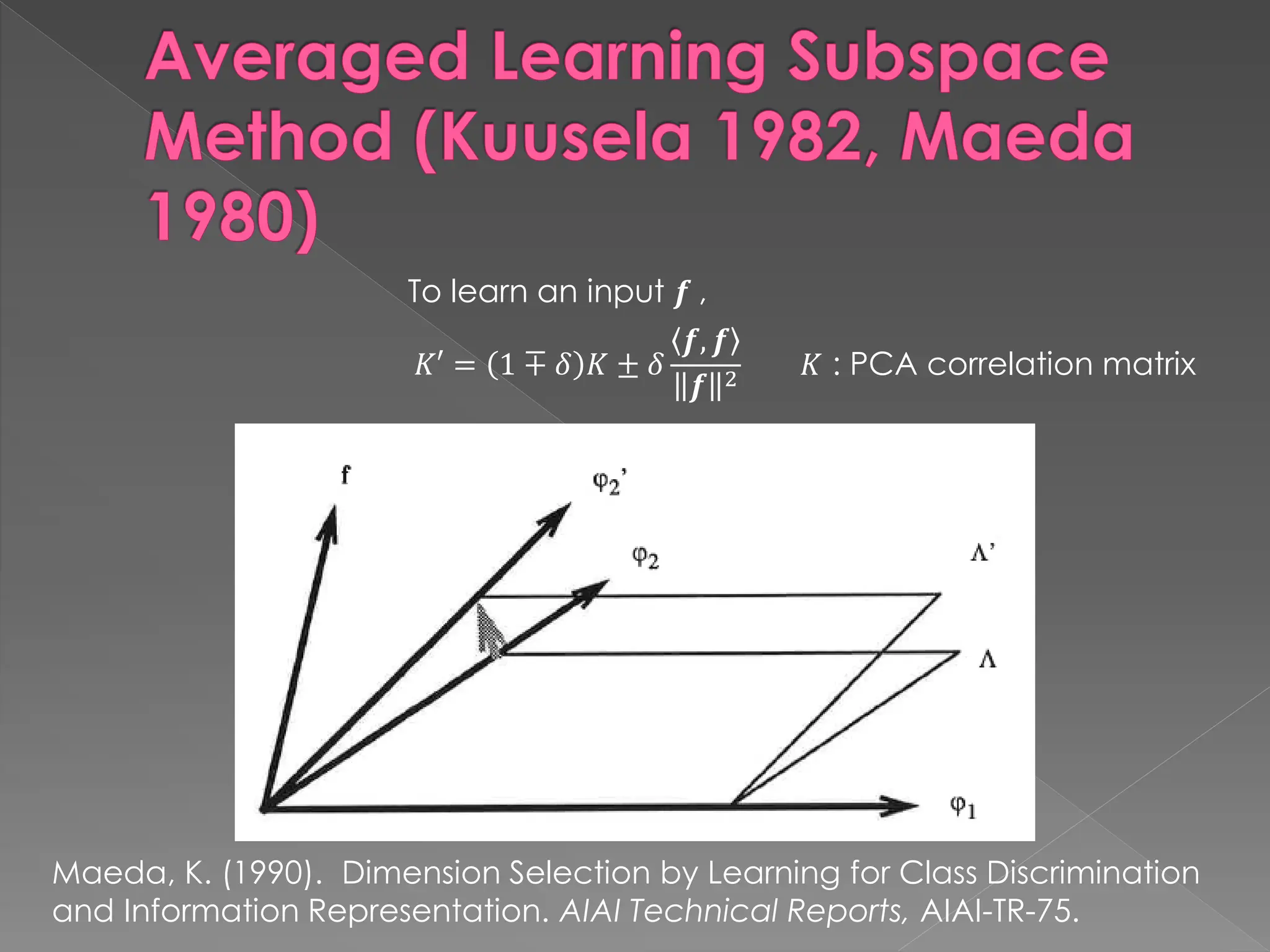
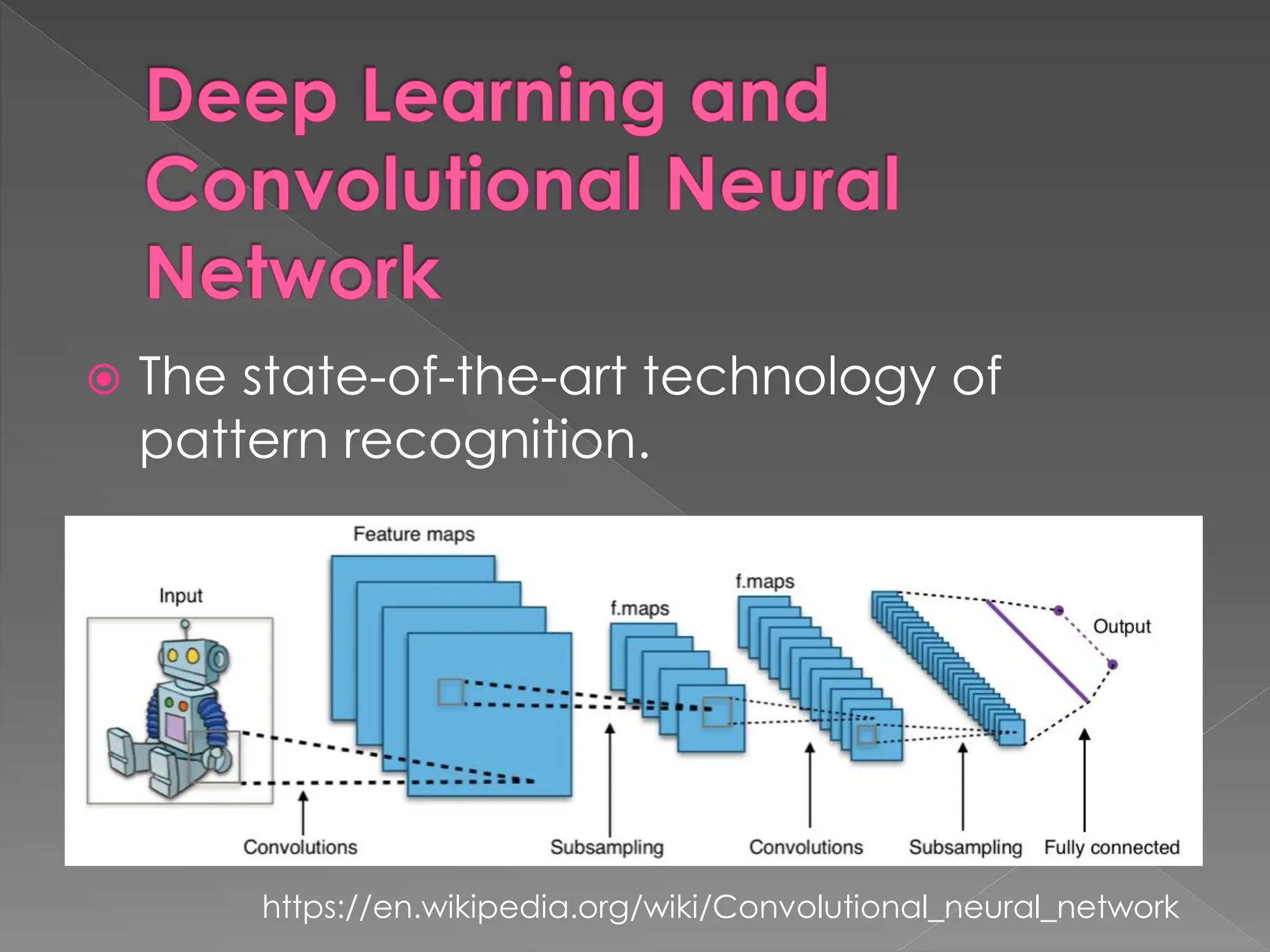
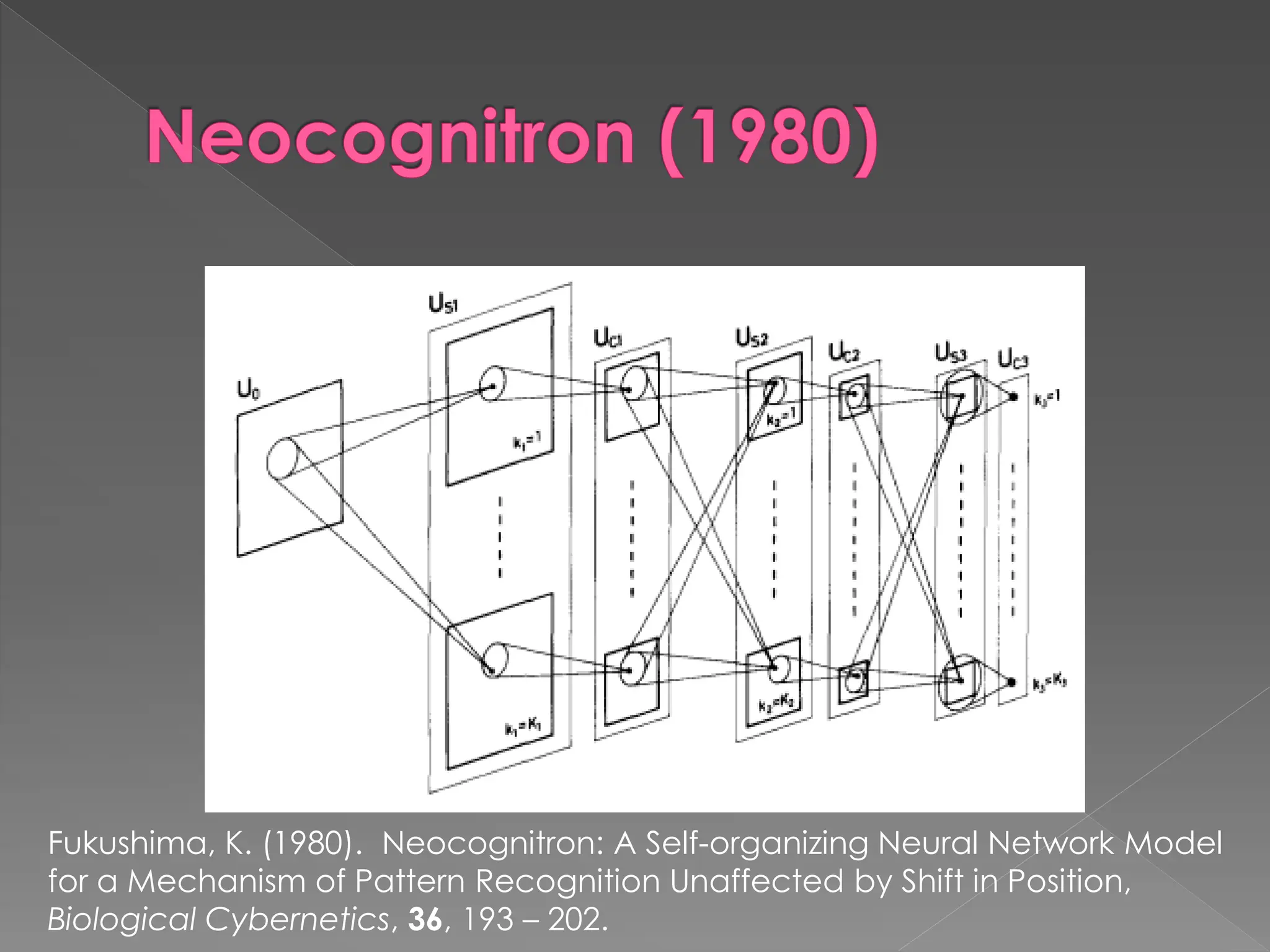
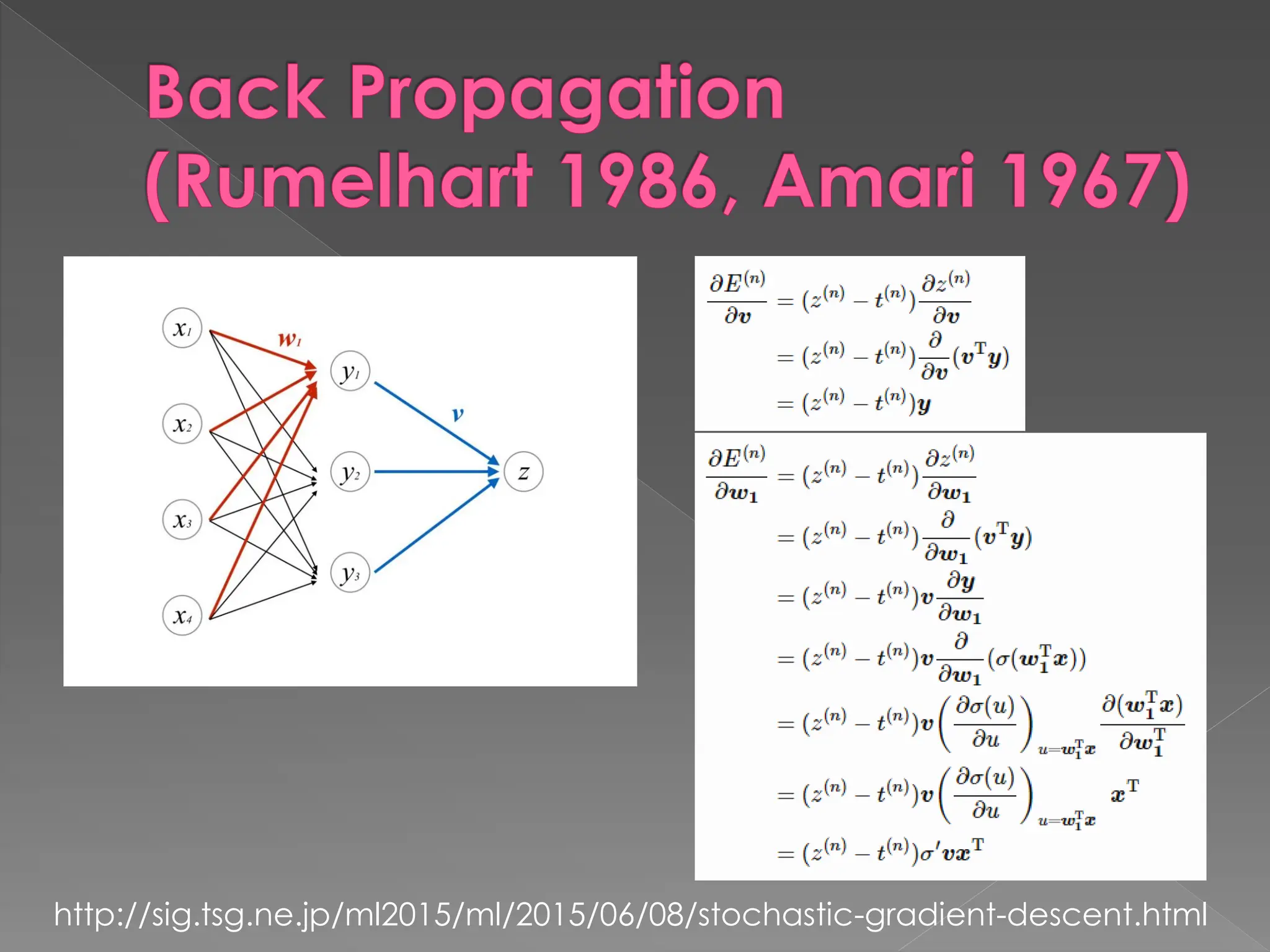
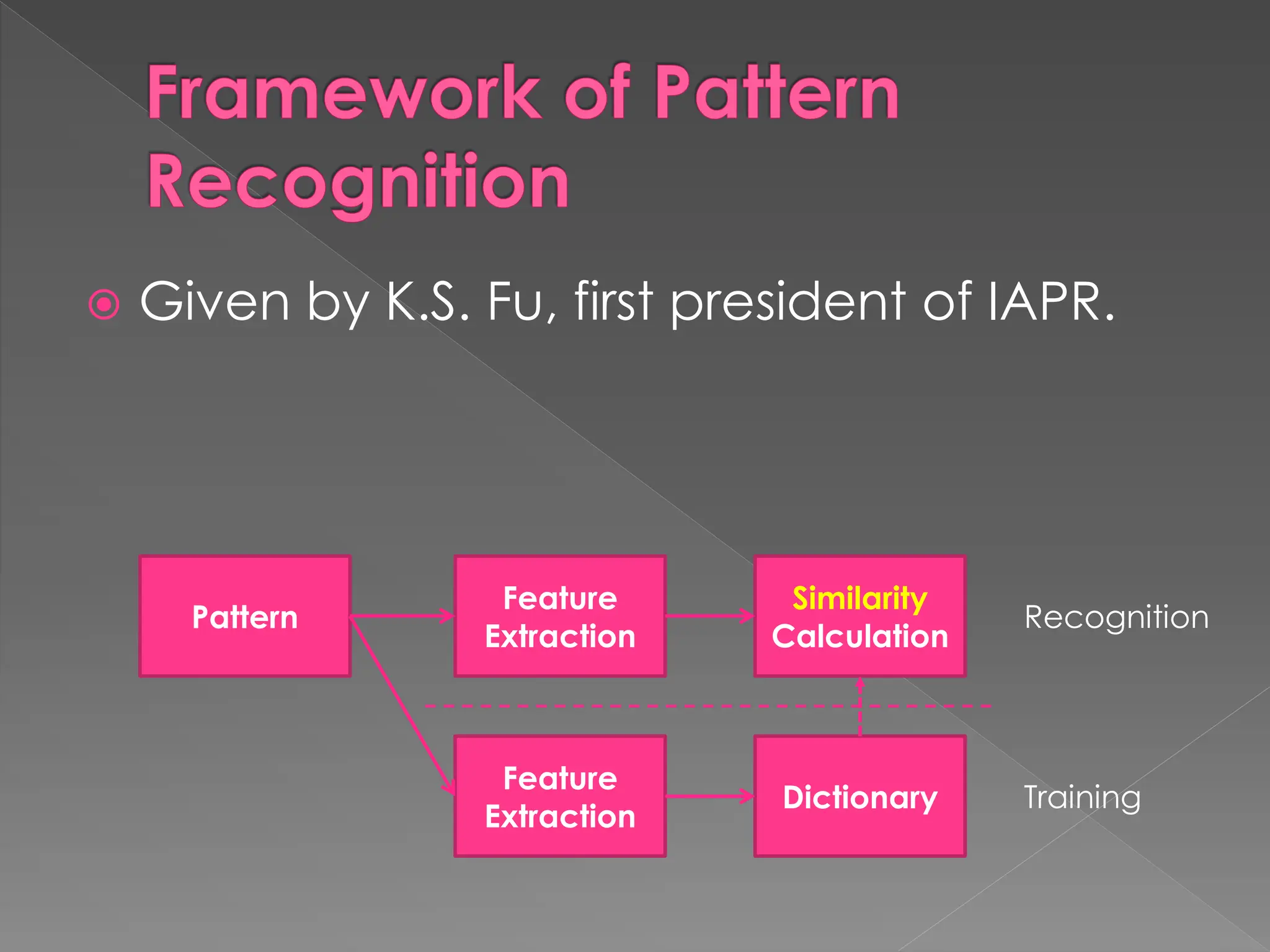
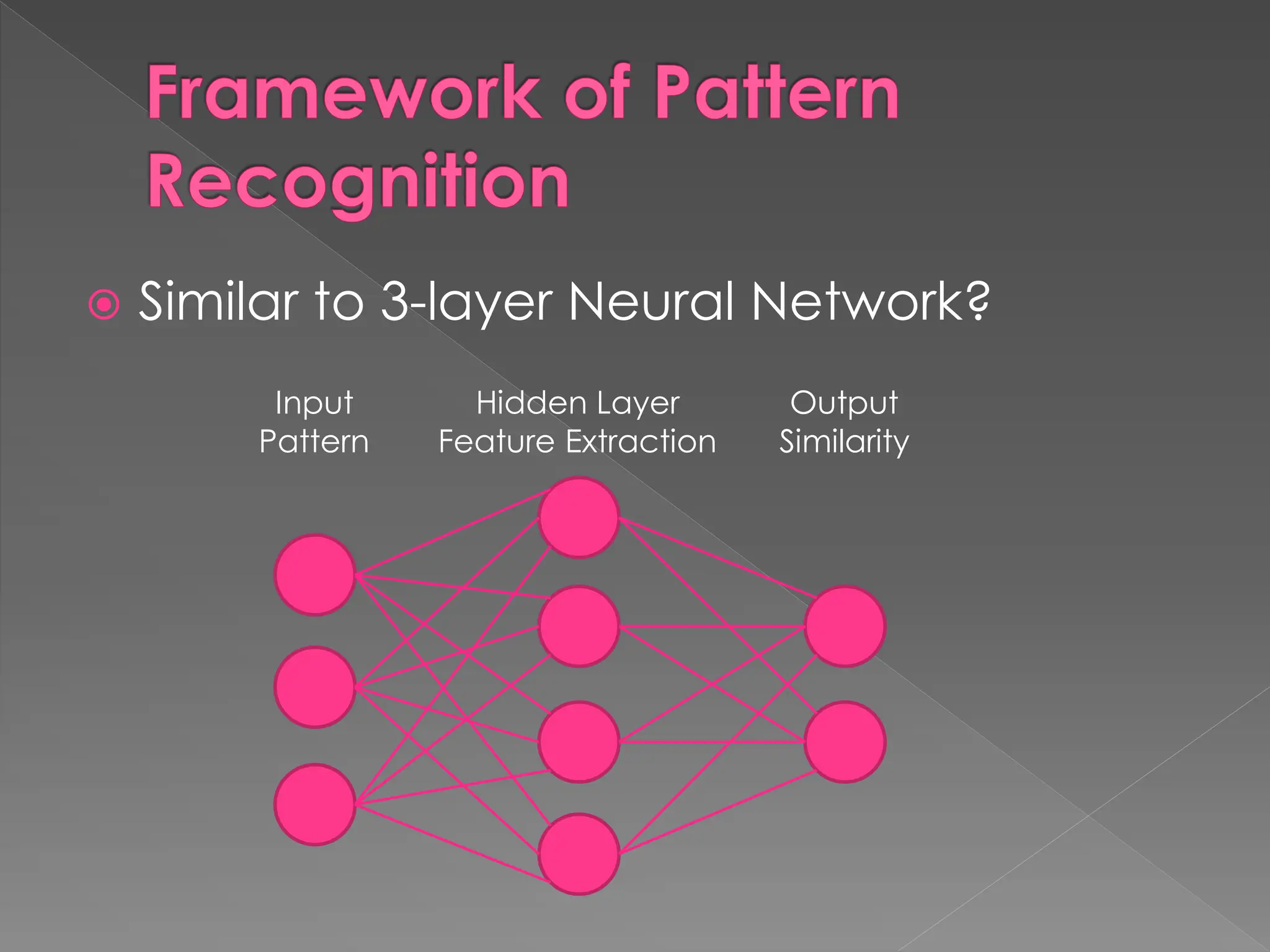
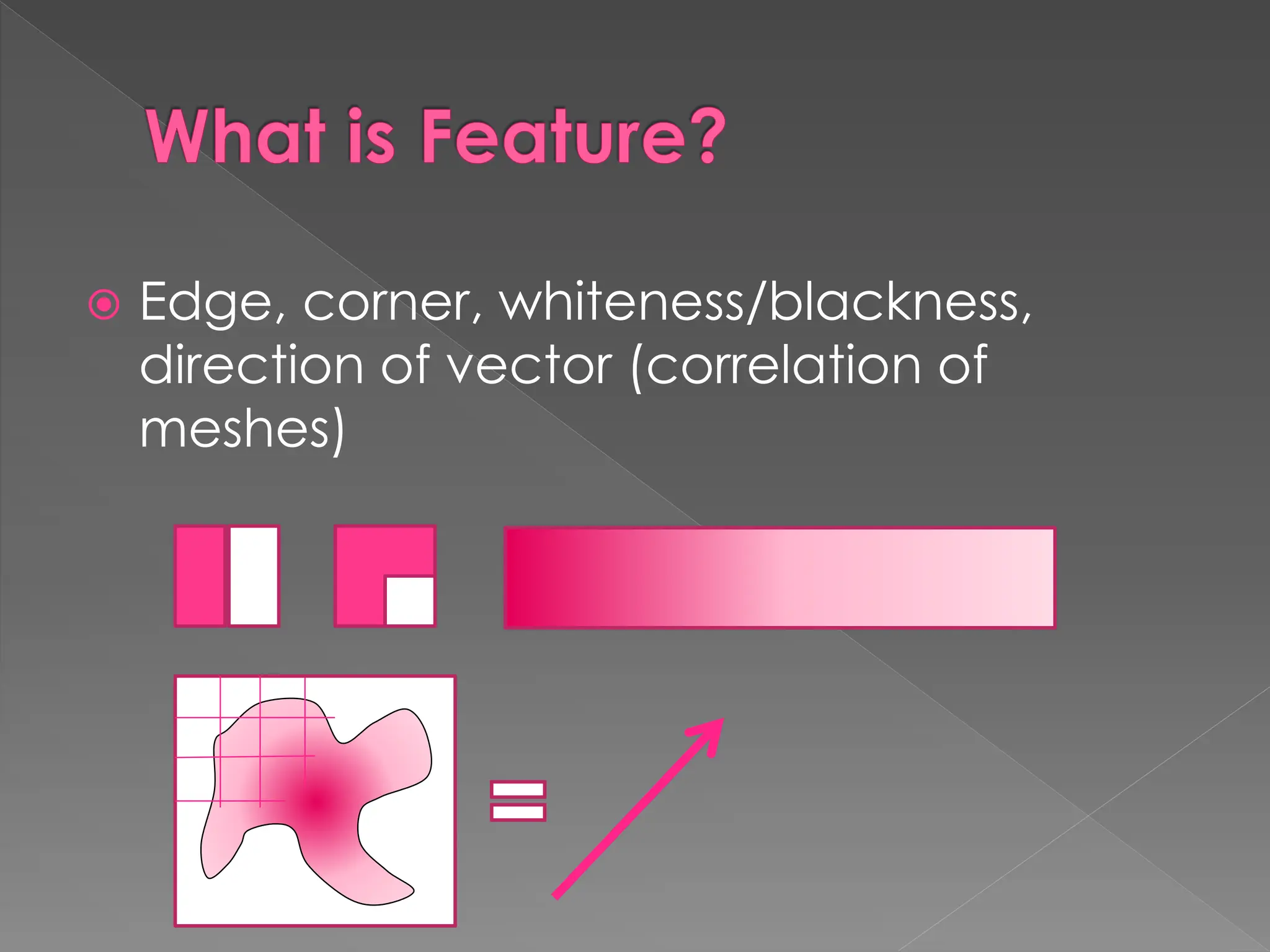
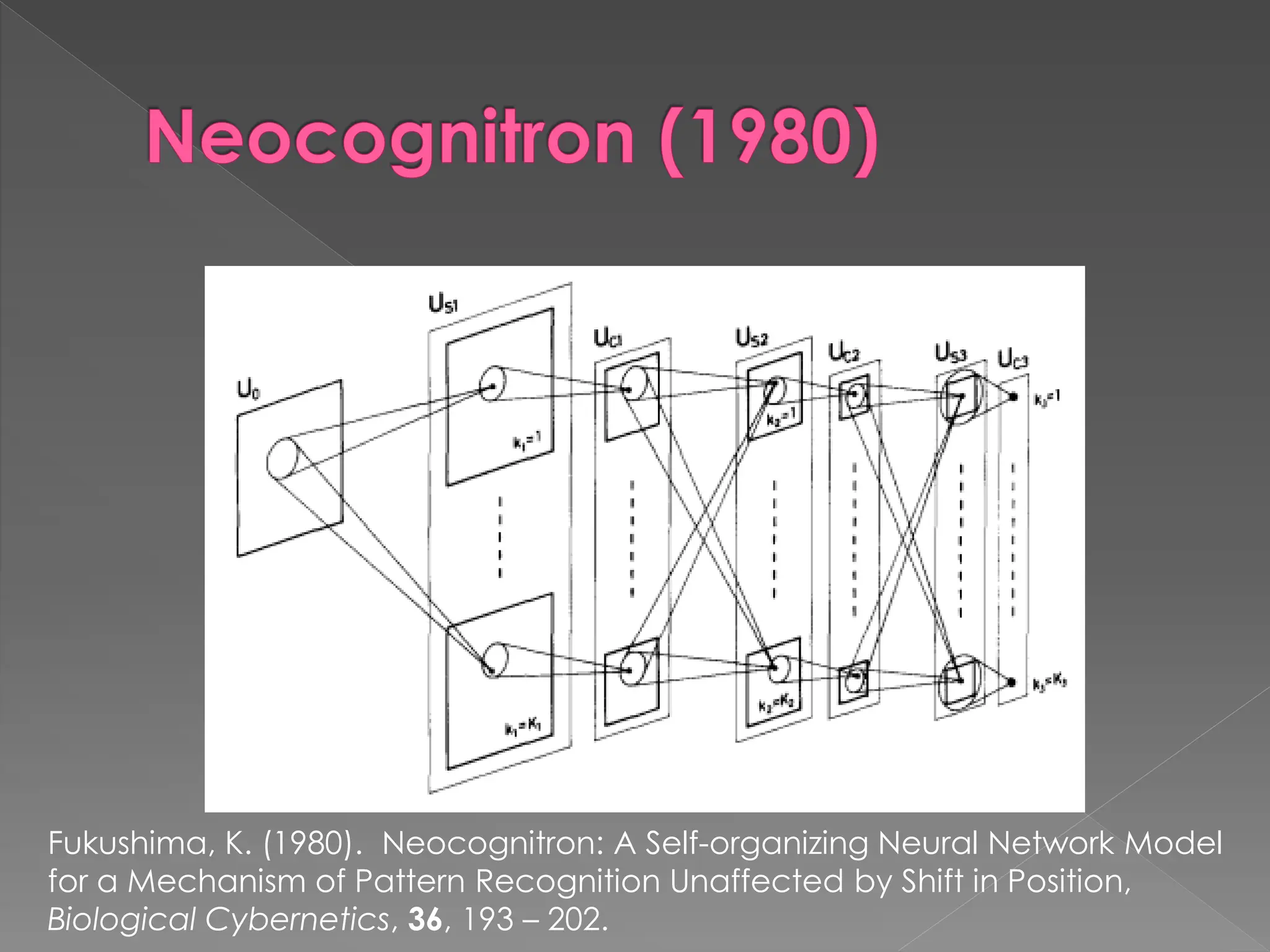
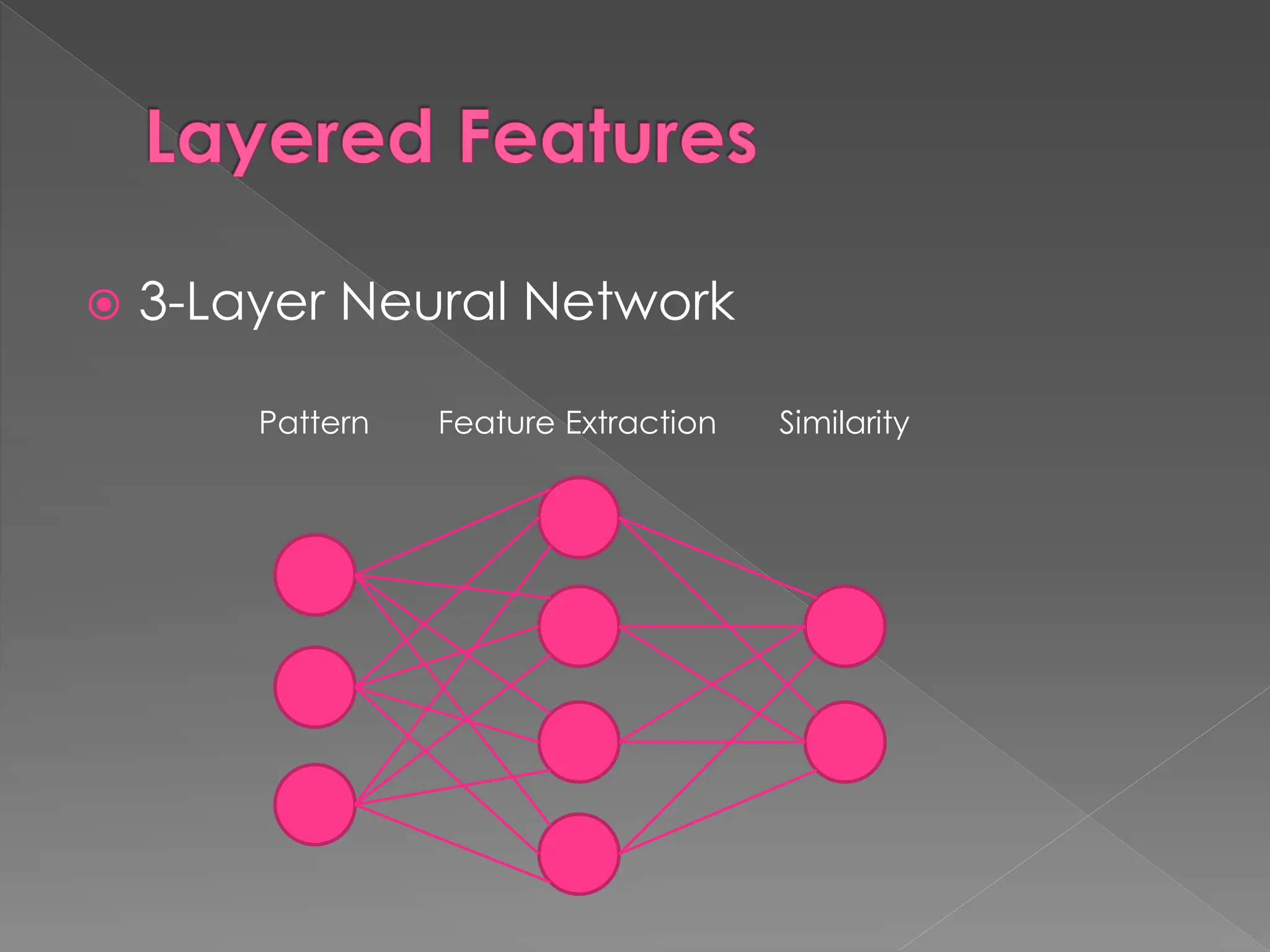
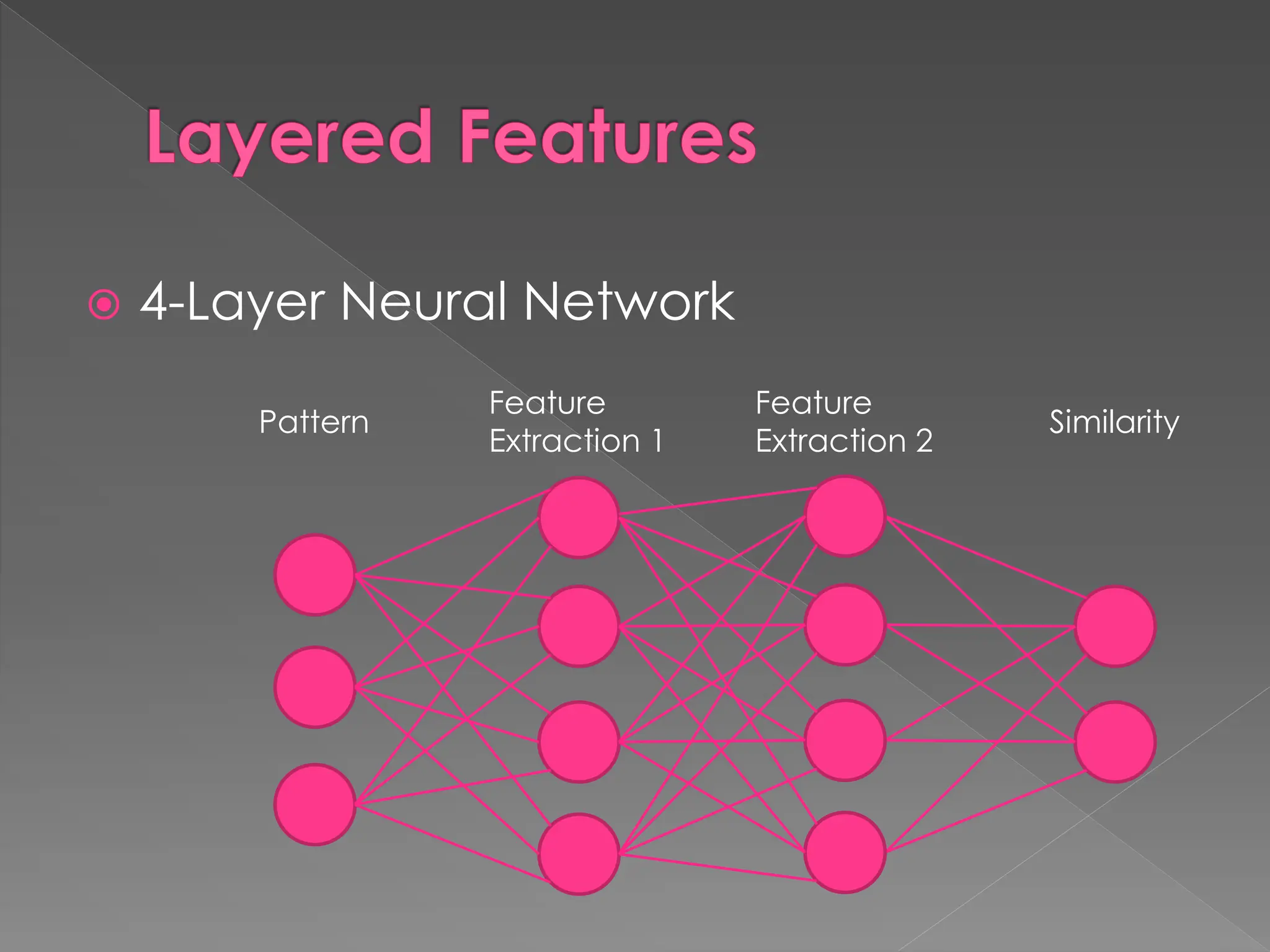
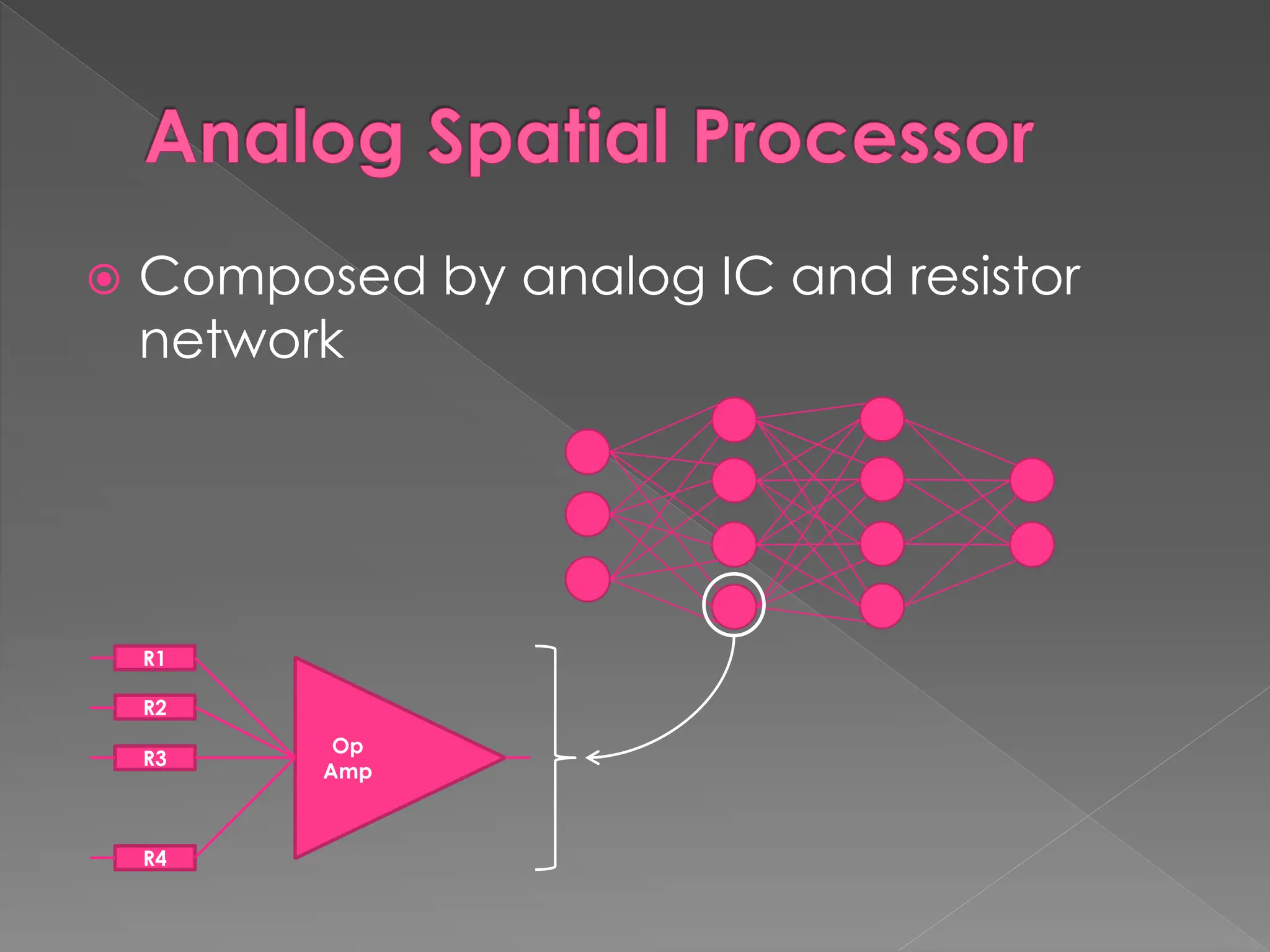
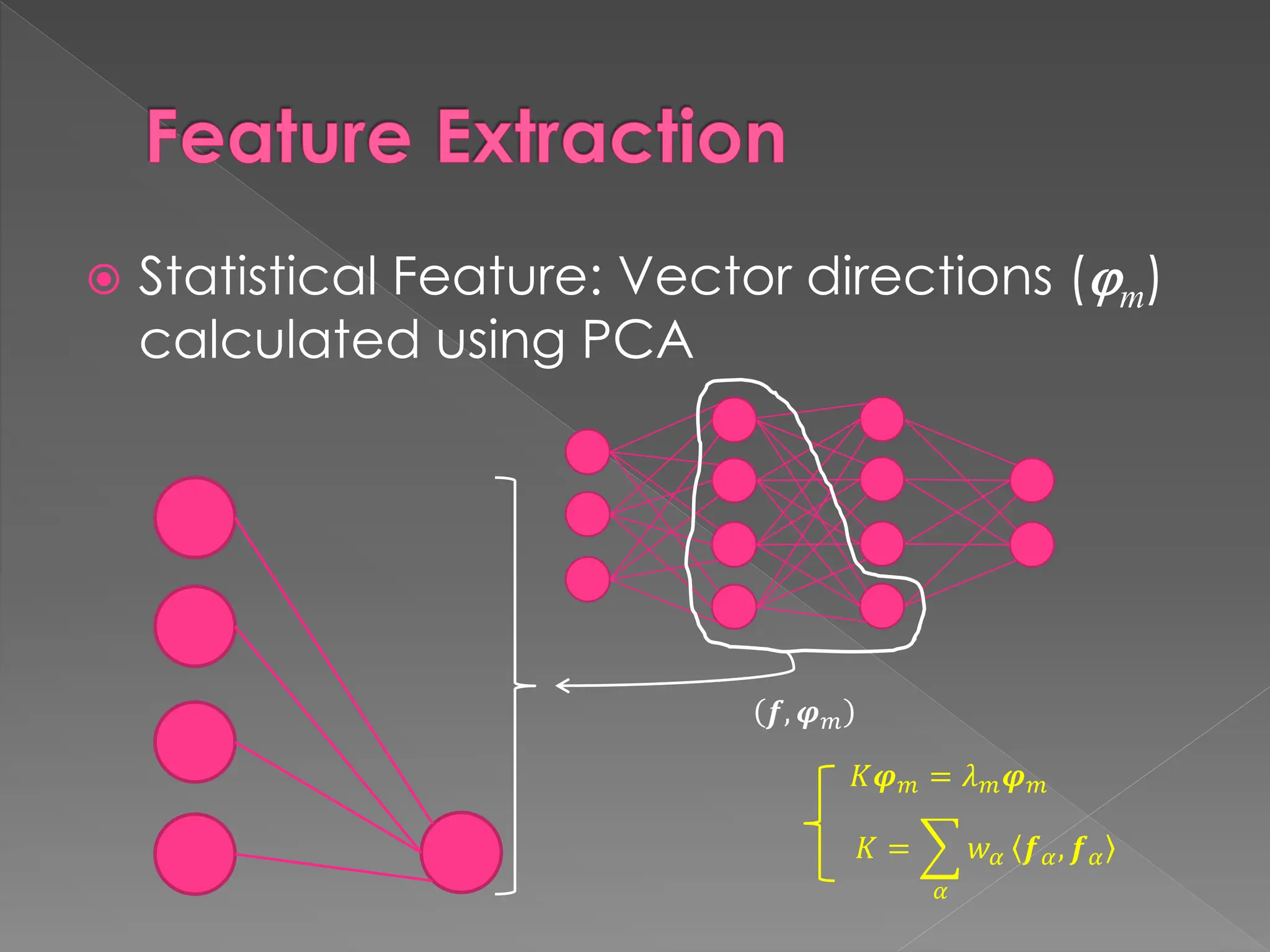
The document discusses the evolution and current state of pattern recognition, highlighting the significance of deep learning and convolutional neural networks as state-of-the-art technologies. It traces the historical development of various pattern recognition models, including the neocognitron and the back propagation algorithm, while emphasizing the importance of returning to fundamental principles in the field. Ultimately, it asserts that while deep learning is powerful, it is not the sole solution and encourages a broader perspective on learning and feature recognition.



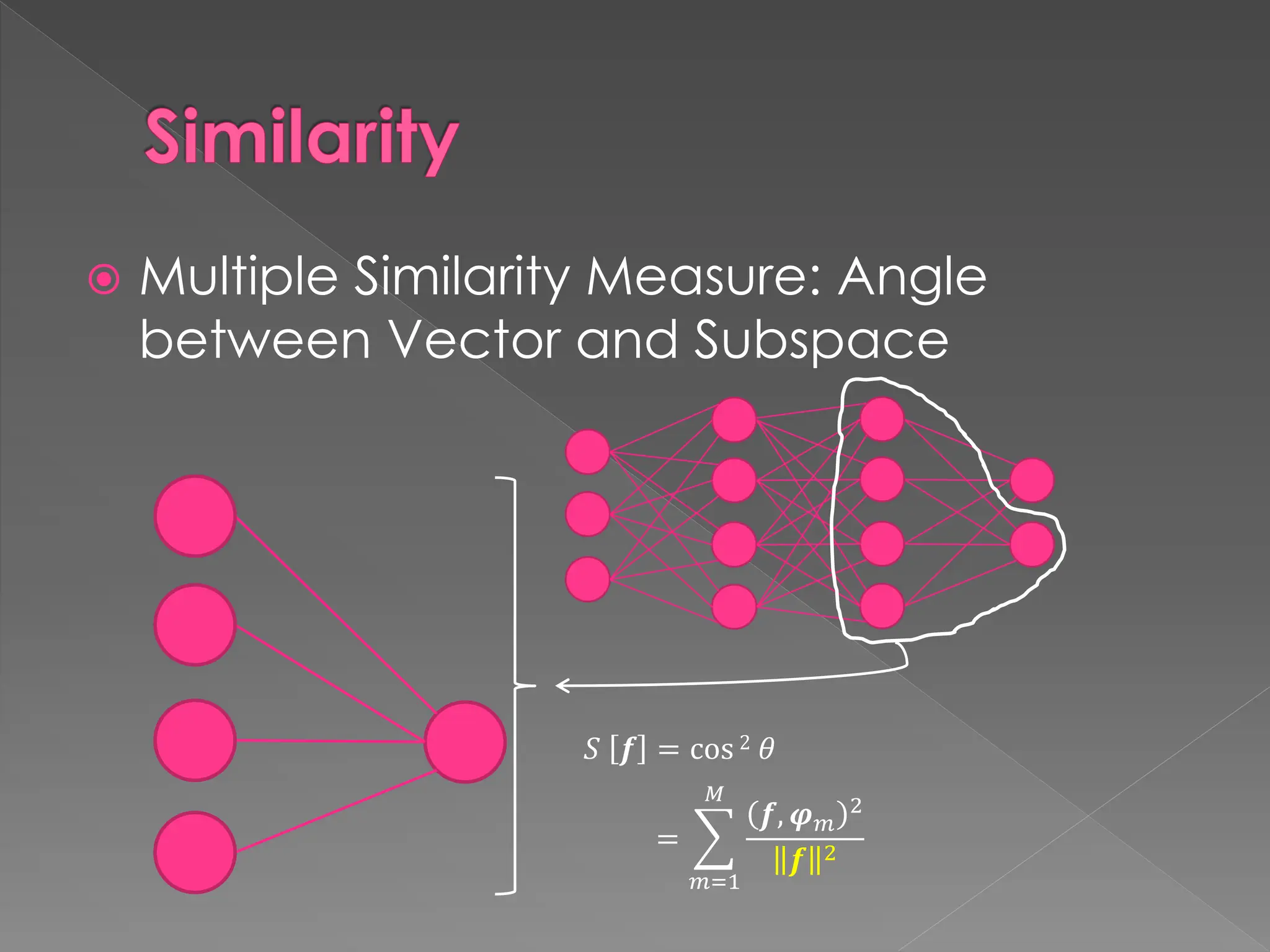
![Similarity Visualisation
Angle between a vector and a subspace
(f*: Nearest vector of f in the subspace)
S [f] = cos2
𝝋1
𝝋2
f
f*](https://image.slidesharecdn.com/prrevisited-h-240723054129-59372769/75/Pattern-Recognition-Revisited-ICVSS-2016-presentaion-16-2048.jpg)