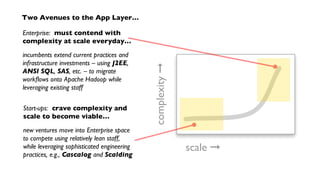
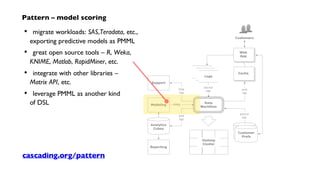
Downloaded 90 times








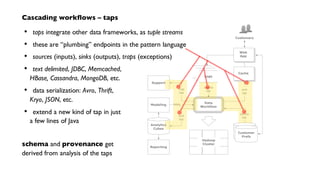
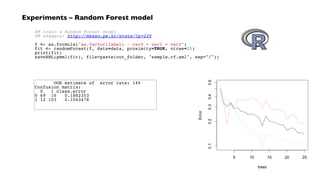
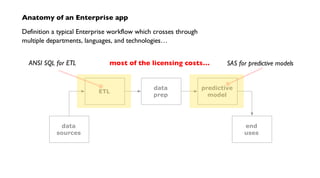
![Cascading workflows – taps
String docPath = args[ 0 ];
String wcPath = args[ 1 ];
Properties properties = new Properties();
AppProps.setApplicationJarClass( properties, Main.class );
HadoopFlowConnector flowConnector = new HadoopFlowConnector( properties );
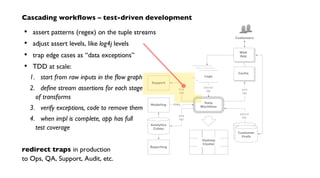
// create source and sink taps
Tap docTap = new Hfs( new TextDelimited( true, "t" ), docPath );
Tap wcTap = new Hfs( new TextDelimited( true, "t" ), wcPath );
// specify a regex to split "document" text lines into token stream
Fields token = new Fields( "token" );
Fields text = new Fields( "text" );
RegexSplitGenerator splitter = new RegexSplitGenerator( token, "[ []
(),.]" );
// only returns "token"
Pipe docPipe = new Each( "token", text, splitter, Fields.RESULTS );
// determine the word counts
Pipe wcPipe = new Pipe( "wc", docPipe );
wcPipe = new GroupBy( wcPipe, token );
wcPipe = new Every( wcPipe, Fields.ALL, new Count(), Fields.ALL );
// connect the taps, pipes, etc., into a flow
FlowDef flowDef = FlowDef.flowDef().setName( "wc" )
.addSource( docPipe, docTap )
.addTailSink( wcPipe, wcTap );
// write a DOT file and run the flow
Flow wcFlow = flowConnector.connect( flowDef );
wcFlow.writeDOT( "dot/wc.dot" );
wcFlow.complete();
source and sink taps
for TSV data in HDFS](https://image.slidesharecdn.com/nathanjune26455pmroom210av2-130711155842-phpapp01/85/Pattern-an-open-source-project-for-migrating-predictive-models-from-SAS-etc-onto-Hadoop-15-320.jpg)
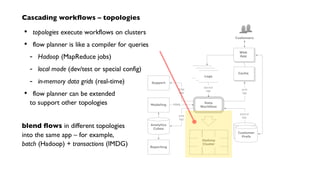
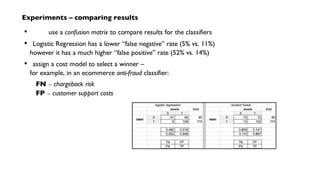
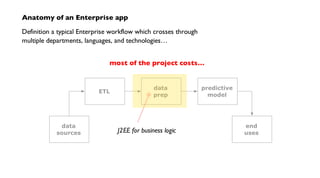
![Cascading workflows – topologies
String docPath = args[ 0 ];
String wcPath = args[ 1 ];
Properties properties = new Properties();
AppProps.setApplicationJarClass( properties, Main.class );
HadoopFlowConnector flowConnector = new HadoopFlowConnector( properties );
// create source and sink taps
Tap docTap = new Hfs( new TextDelimited( true, "t" ), docPath );
Tap wcTap = new Hfs( new TextDelimited( true, "t" ), wcPath );
// specify a regex to split "document" text lines into token stream
Fields token = new Fields( "token" );
Fields text = new Fields( "text" );
RegexSplitGenerator splitter = new RegexSplitGenerator( token, "[ []
(),.]" );
// only returns "token"
Pipe docPipe = new Each( "token", text, splitter, Fields.RESULTS );
// determine the word counts
Pipe wcPipe = new Pipe( "wc", docPipe );
wcPipe = new GroupBy( wcPipe, token );
wcPipe = new Every( wcPipe, Fields.ALL, new Count(), Fields.ALL );
// connect the taps, pipes, etc., into a flow
FlowDef flowDef = FlowDef.flowDef().setName( "wc" )
.addSource( docPipe, docTap )
.addTailSink( wcPipe, wcTap );
// write a DOT file and run the flow
Flow wcFlow = flowConnector.connect( flowDef );
wcFlow.writeDOT( "dot/wc.dot" );
wcFlow.complete();
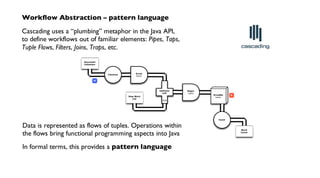
flow planner for
Apache Hadoop
topology](https://image.slidesharecdn.com/nathanjune26455pmroom210av2-130711155842-phpapp01/85/Pattern-an-open-source-project-for-migrating-predictive-models-from-SAS-etc-onto-Hadoop-17-320.jpg)










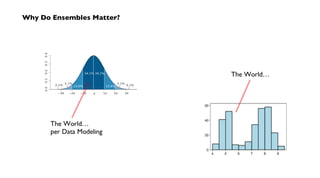
![## train a RandomForest model
f <- as.formula("as.factor(label) ~ .")
fit <- randomForest(f, data_train, ntree=50)
## test the model on the holdout test set
print(fit$importance)
print(fit)
predicted <- predict(fit, data)
data$predicted <- predicted
confuse <- table(pred = predicted, true = data[,1])
print(confuse)
## export predicted labels to TSV
write.table(data, file=paste(dat_folder, "sample.tsv", sep="/"),
quote=FALSE, sep="t", row.names=FALSE)
## export RF model to PMML
saveXML(pmml(fit), file=paste(dat_folder, "sample.rf.xml", sep="/"))
Pattern – create a model in R](https://image.slidesharecdn.com/nathanjune26455pmroom210av2-130711155842-phpapp01/85/Pattern-an-open-source-project-for-migrating-predictive-models-from-SAS-etc-onto-Hadoop-34-320.jpg)

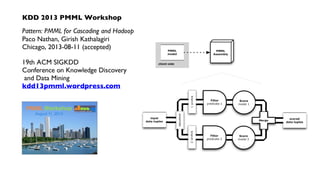
![public static void main( String[] args ) throws RuntimeException {
String inputPath = args[ 0 ];
String classifyPath = args[ 1 ];
// set up the config properties
Properties properties = new Properties();
AppProps.setApplicationJarClass( properties, Main.class );
HadoopFlowConnector flowConnector = new HadoopFlowConnector( properties );
// create source and sink taps
Tap inputTap = new Hfs( new TextDelimited( true, "t" ), inputPath );
Tap classifyTap = new Hfs( new TextDelimited( true, "t" ), classifyPath );
// handle command line options
OptionParser optParser = new OptionParser();
optParser.accepts( "pmml" ).withRequiredArg();
OptionSet options = optParser.parse( args );
// connect the taps, pipes, etc., into a flow
FlowDef flowDef = FlowDef.flowDef().setName( "classify" )
.addSource( "input", inputTap )
.addSink( "classify", classifyTap );
if( options.hasArgument( "pmml" ) ) {
String pmmlPath = (String) options.valuesOf( "pmml" ).get( 0 );
PMMLPlanner pmmlPlanner = new PMMLPlanner()
.setPMMLInput( new File( pmmlPath ) )
.retainOnlyActiveIncomingFields()
.setDefaultPredictedField( new Fields( "predict", Double.class ) ); // default value if missing from the model
flowDef.addAssemblyPlanner( pmmlPlanner );
}
// write a DOT file and run the flow
Flow classifyFlow = flowConnector.connect( flowDef );
classifyFlow.writeDOT( "dot/classify.dot" );
classifyFlow.complete();
}
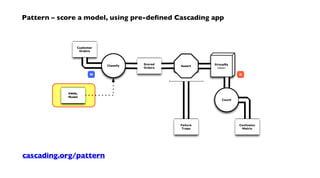
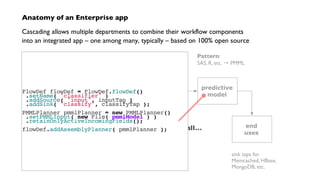
Pattern – score a model, within an app](https://image.slidesharecdn.com/nathanjune26455pmroom210av2-130711155842-phpapp01/85/Pattern-an-open-source-project-for-migrating-predictive-models-from-SAS-etc-onto-Hadoop-36-320.jpg)





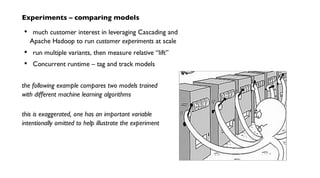






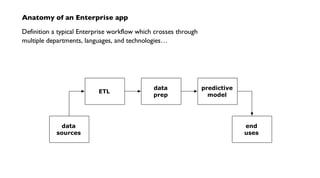
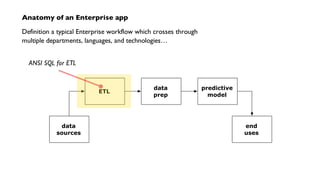
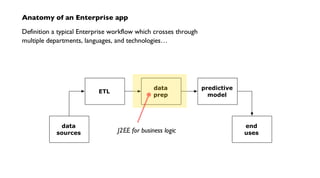
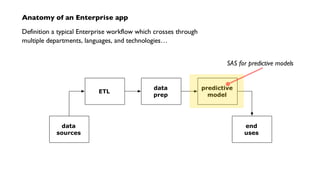
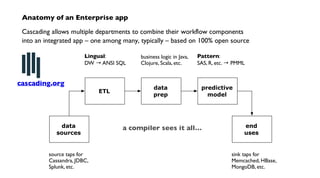
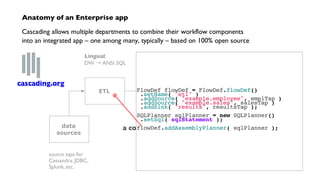
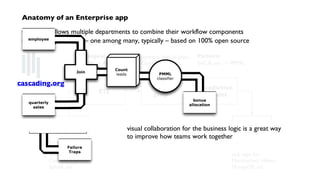





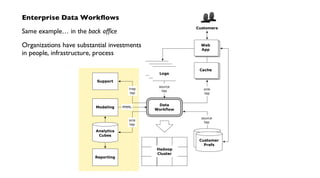
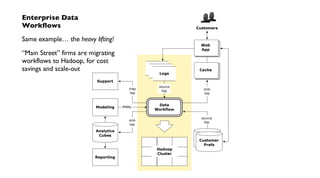
The document discusses 'Cascading', an open-source API for simplifying the implementation of functional programming with Hadoop for large-scale data workflows, allowing Java developers to efficiently manage complex enterprise data processes. It outlines its uses, integrations, and case studies, emphasizing the pattern language that promotes best practices and enhances business process management through effective workflow abstraction. Additionally, the document highlights PMML (Predictive Model Markup Language) for migrating predictive models from systems like SAS to Hadoop, facilitating easier model deployment and interoperability.





















































































