Downloaded 55 times



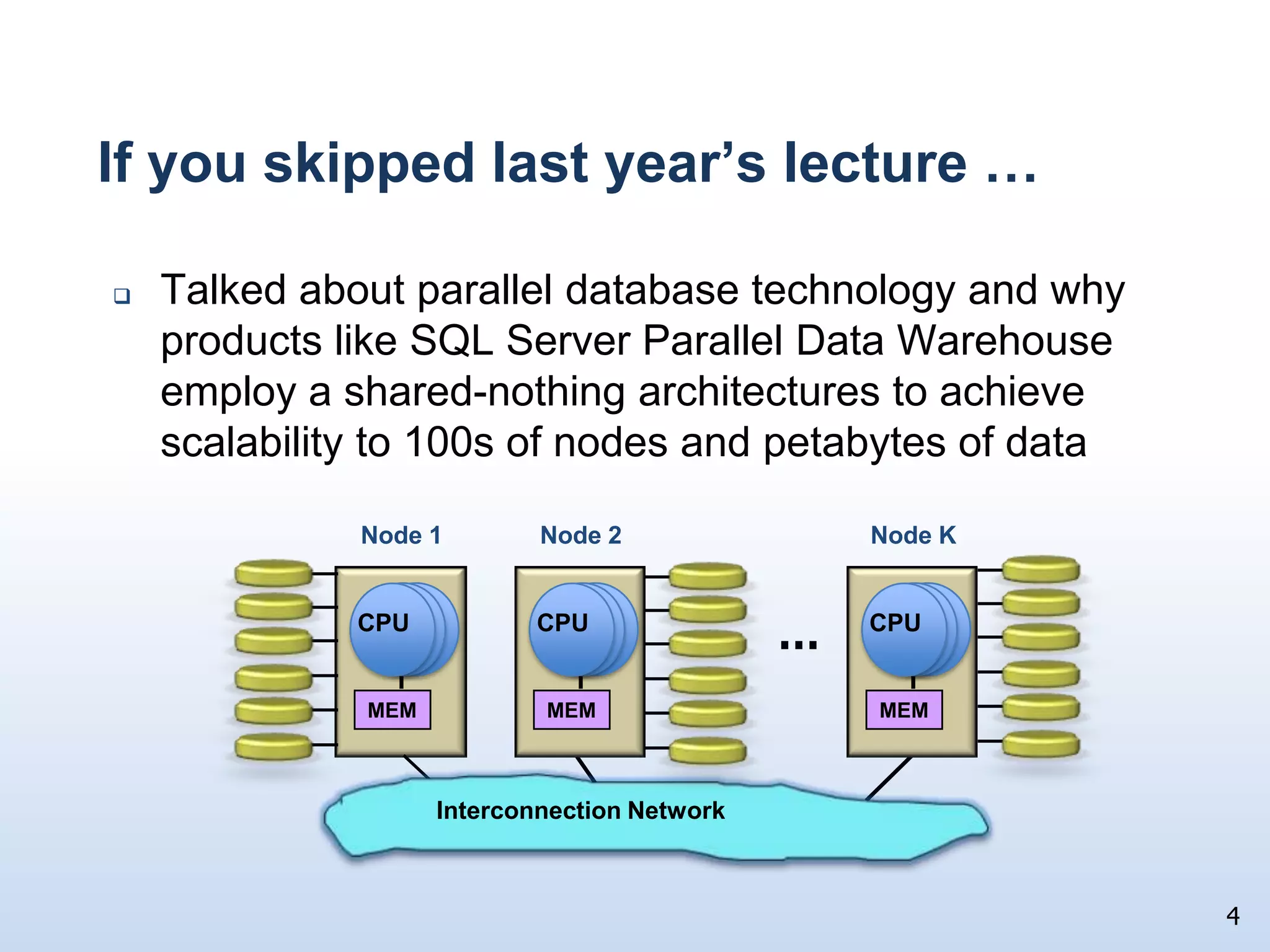



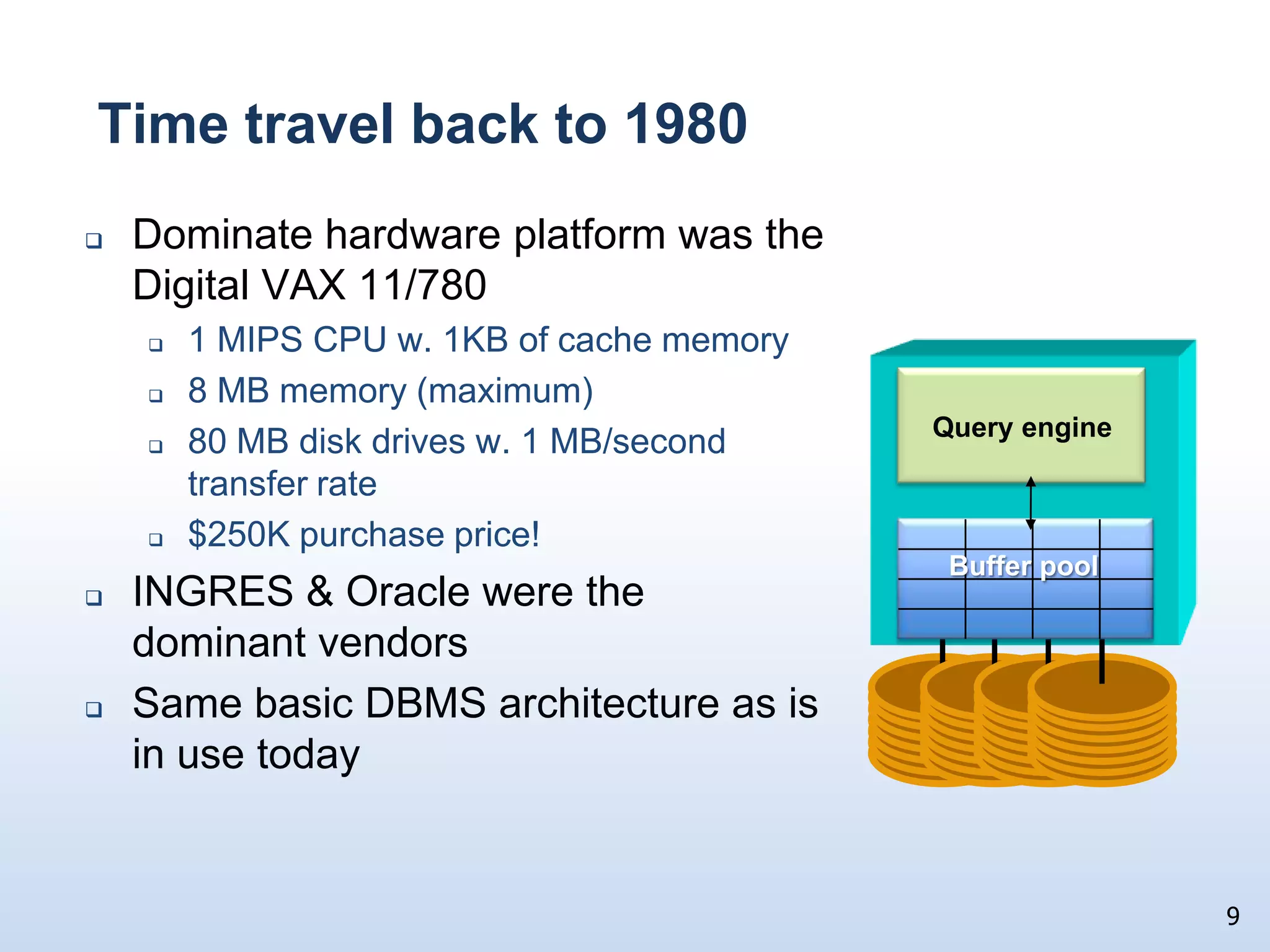
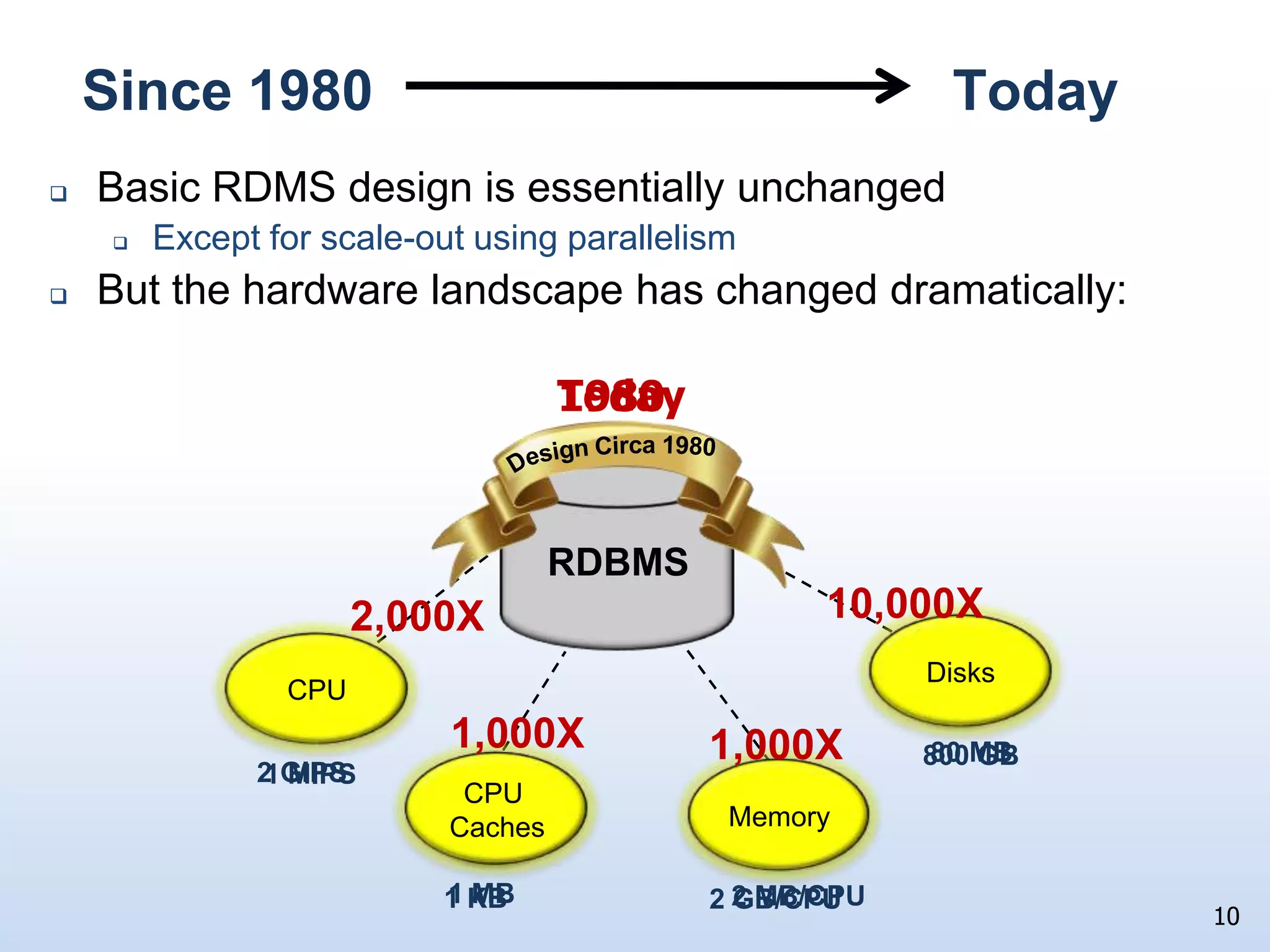






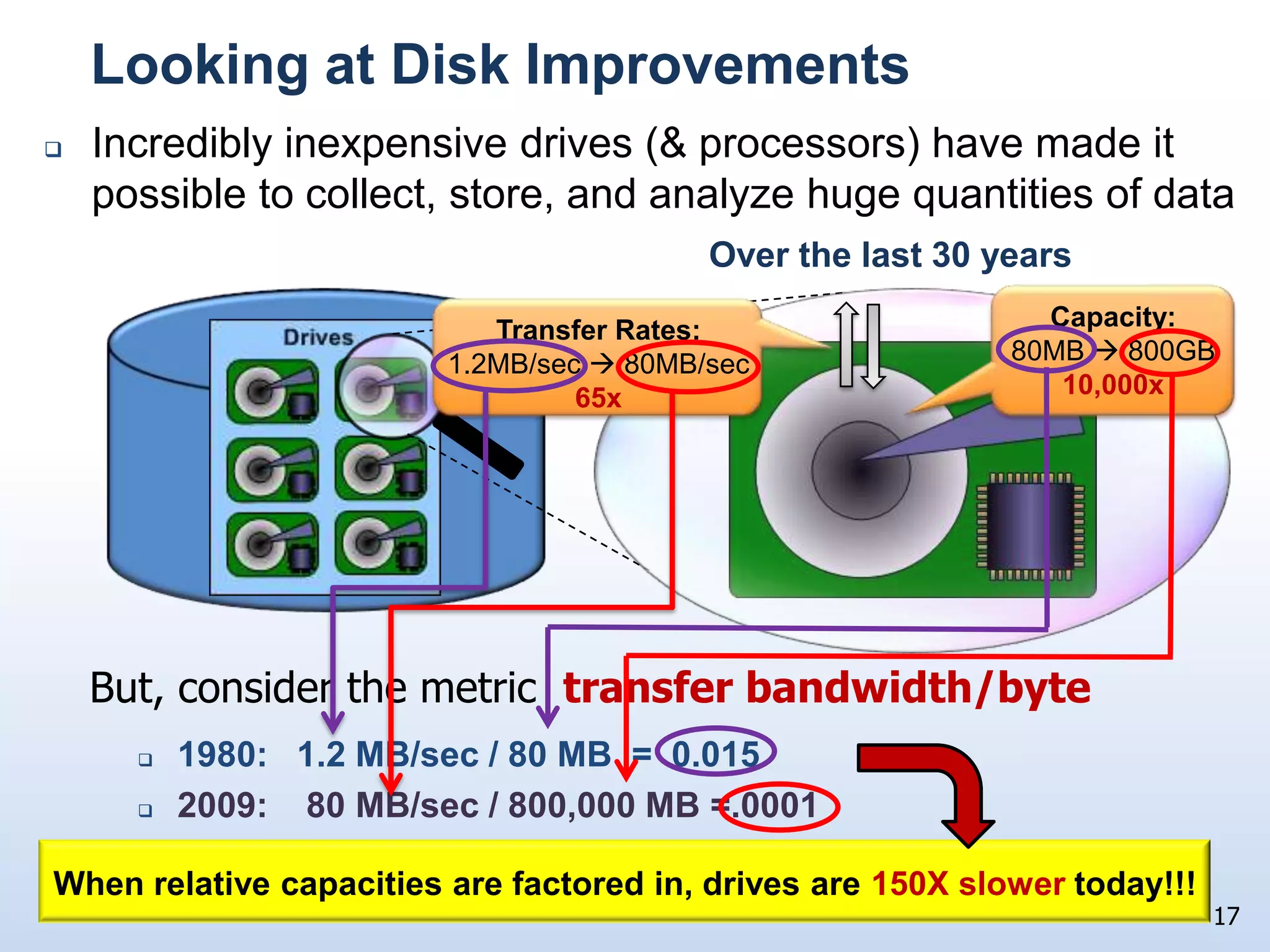

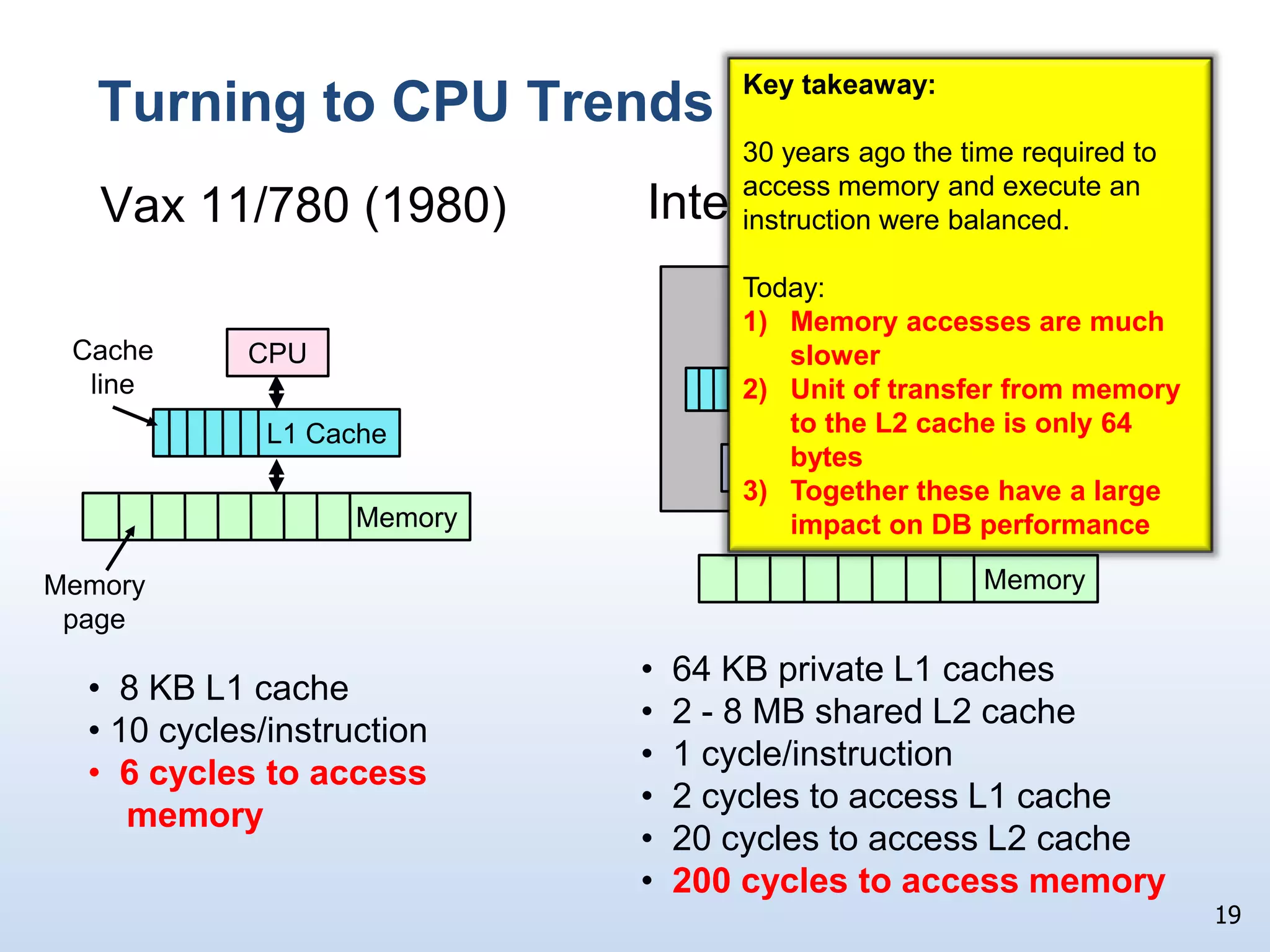
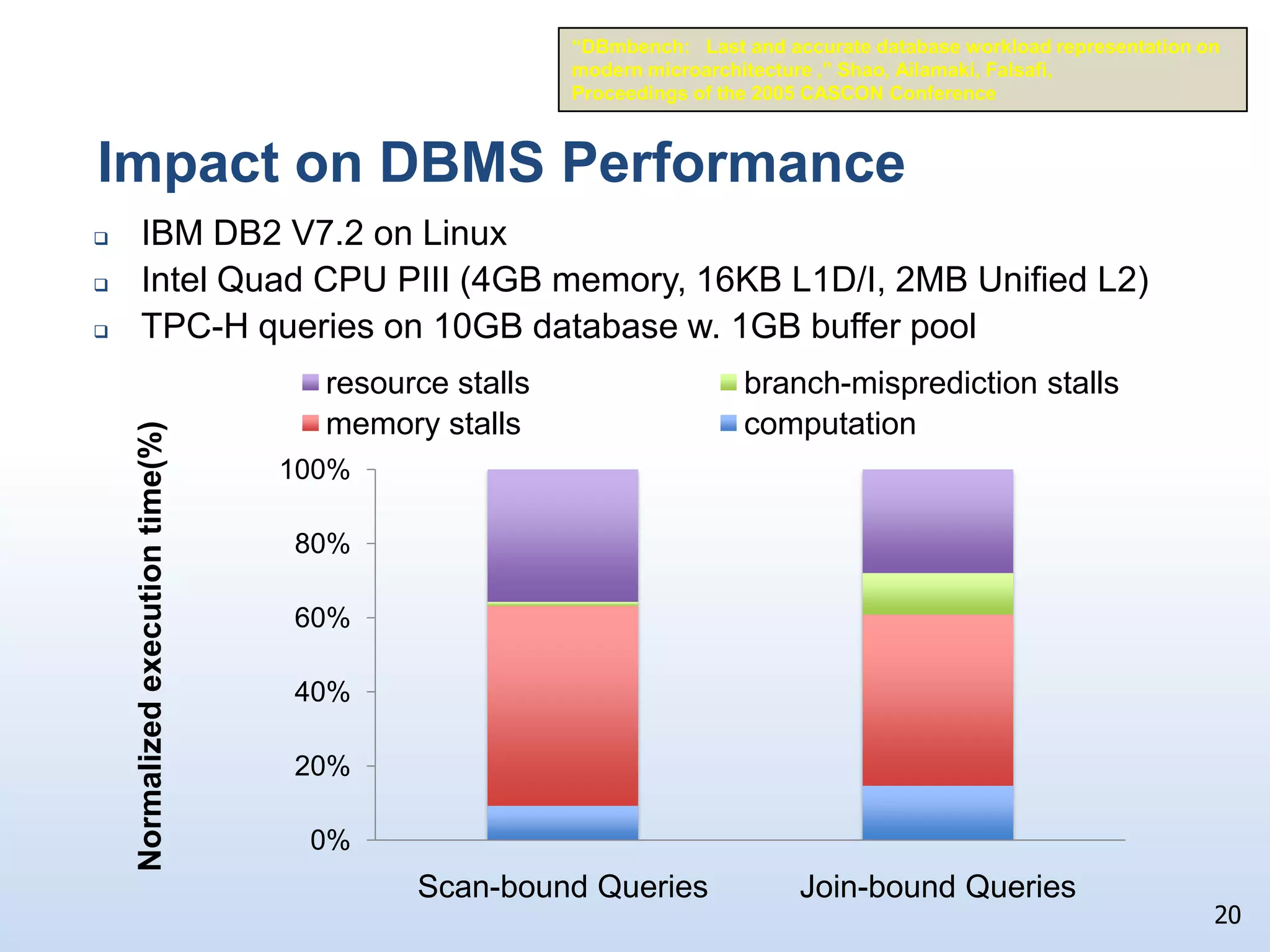
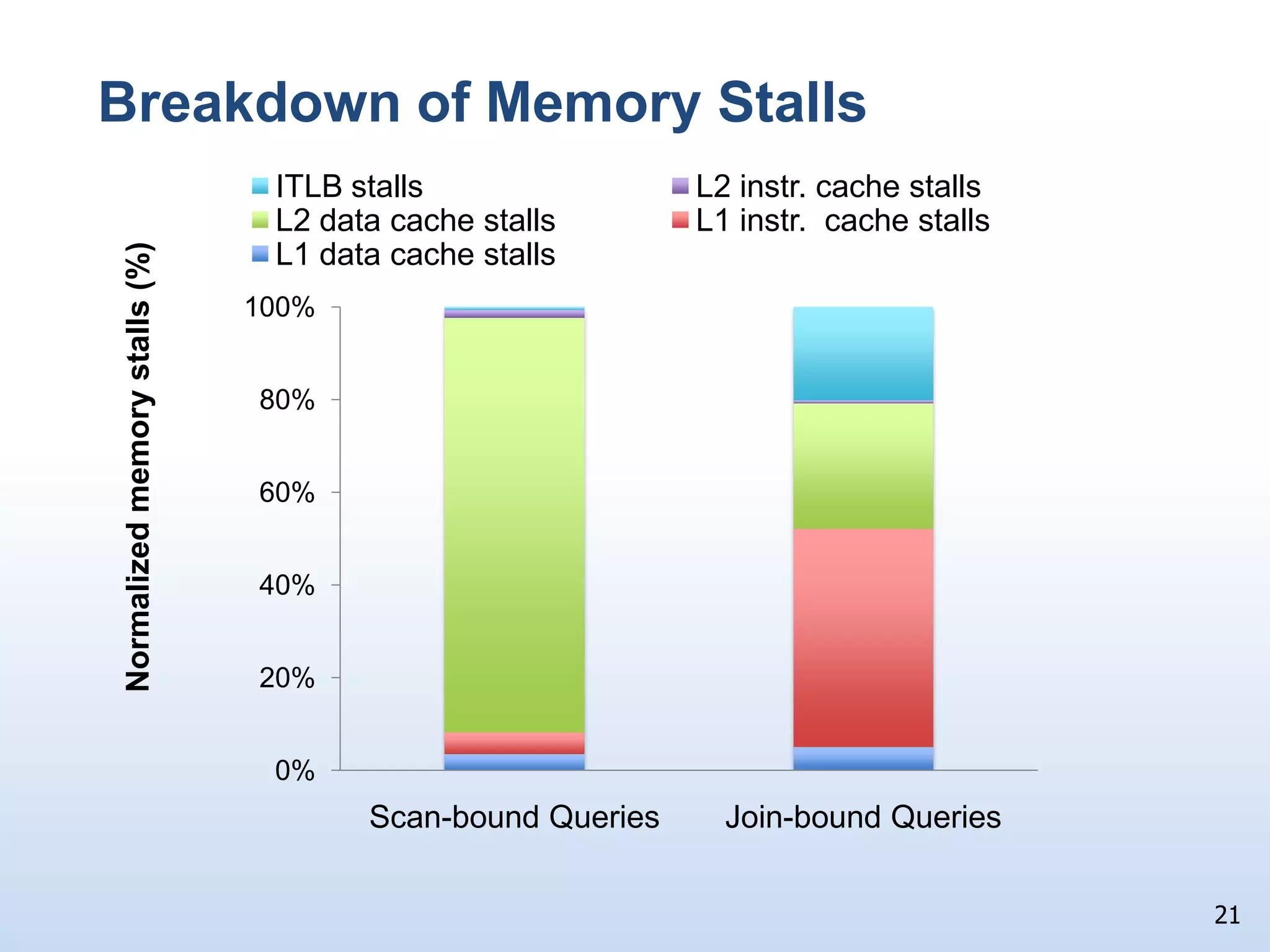

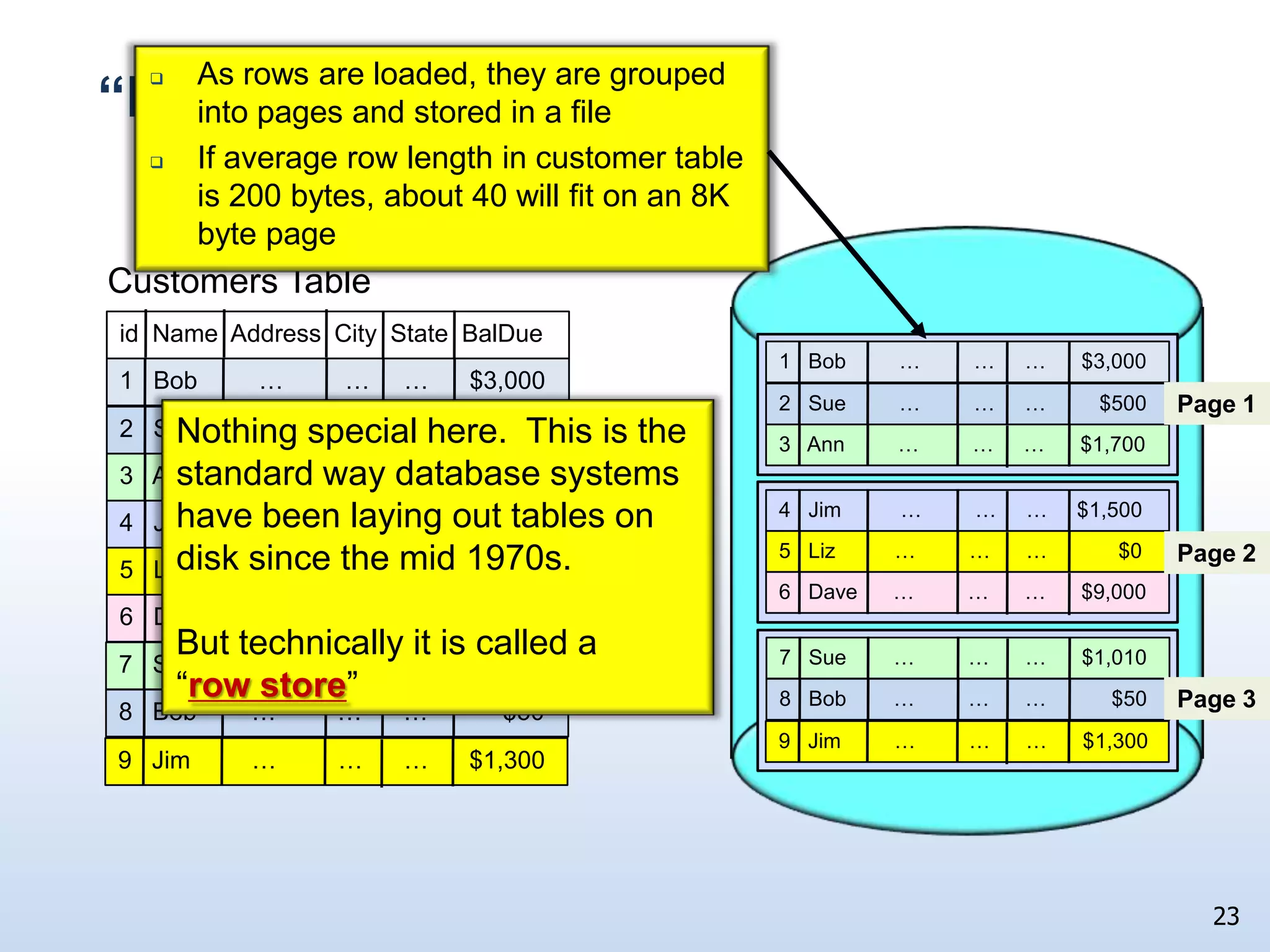
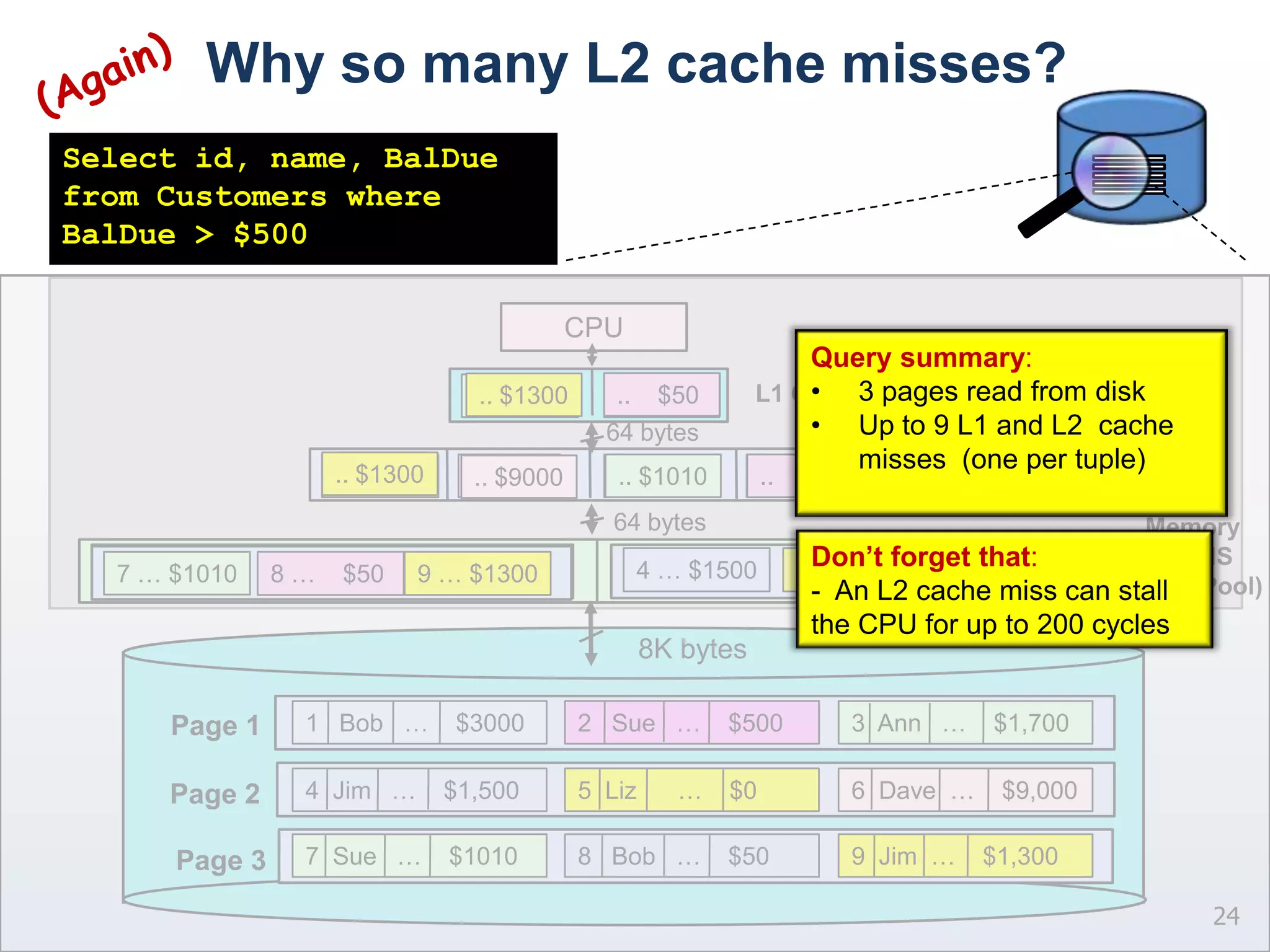

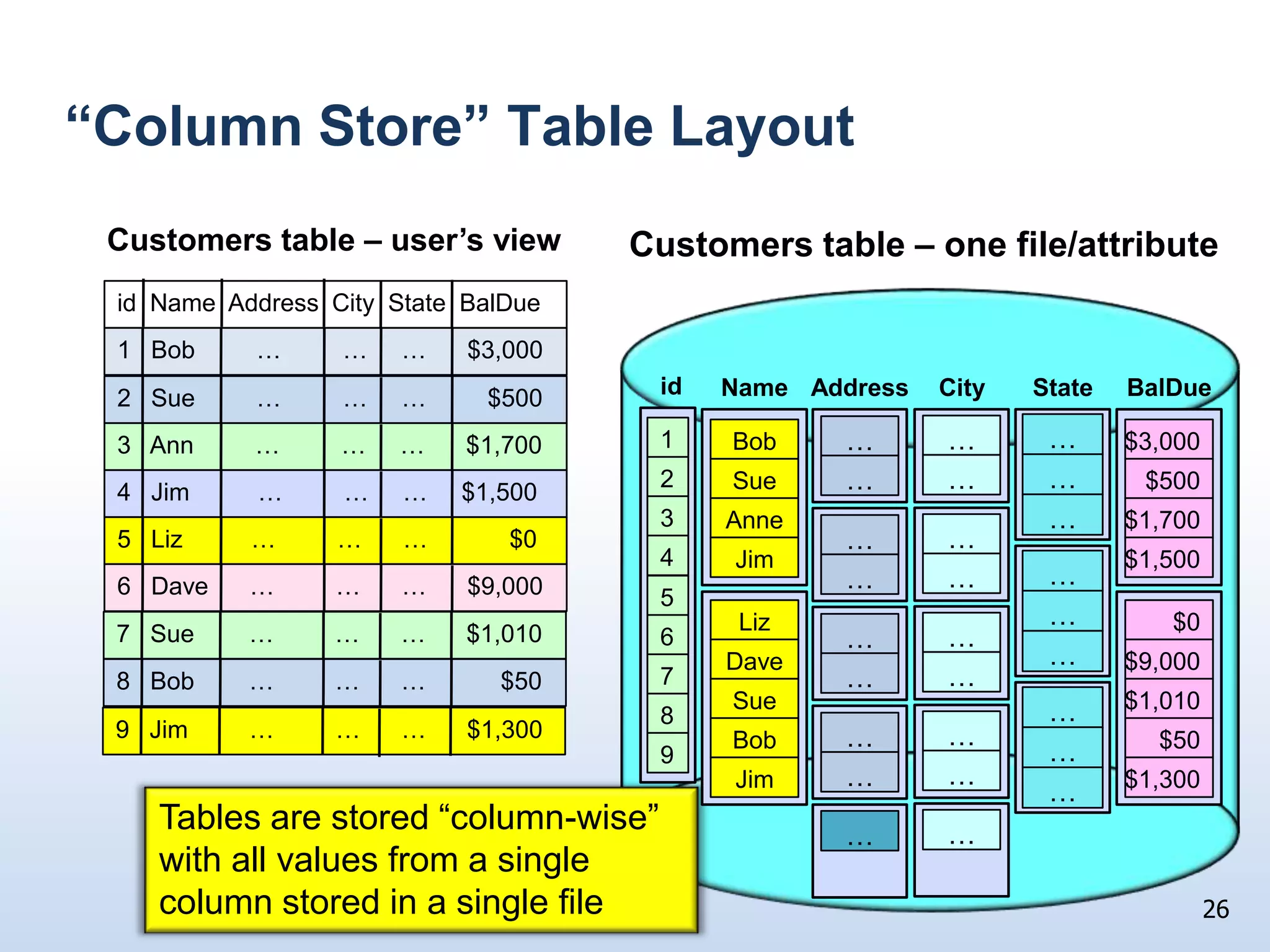
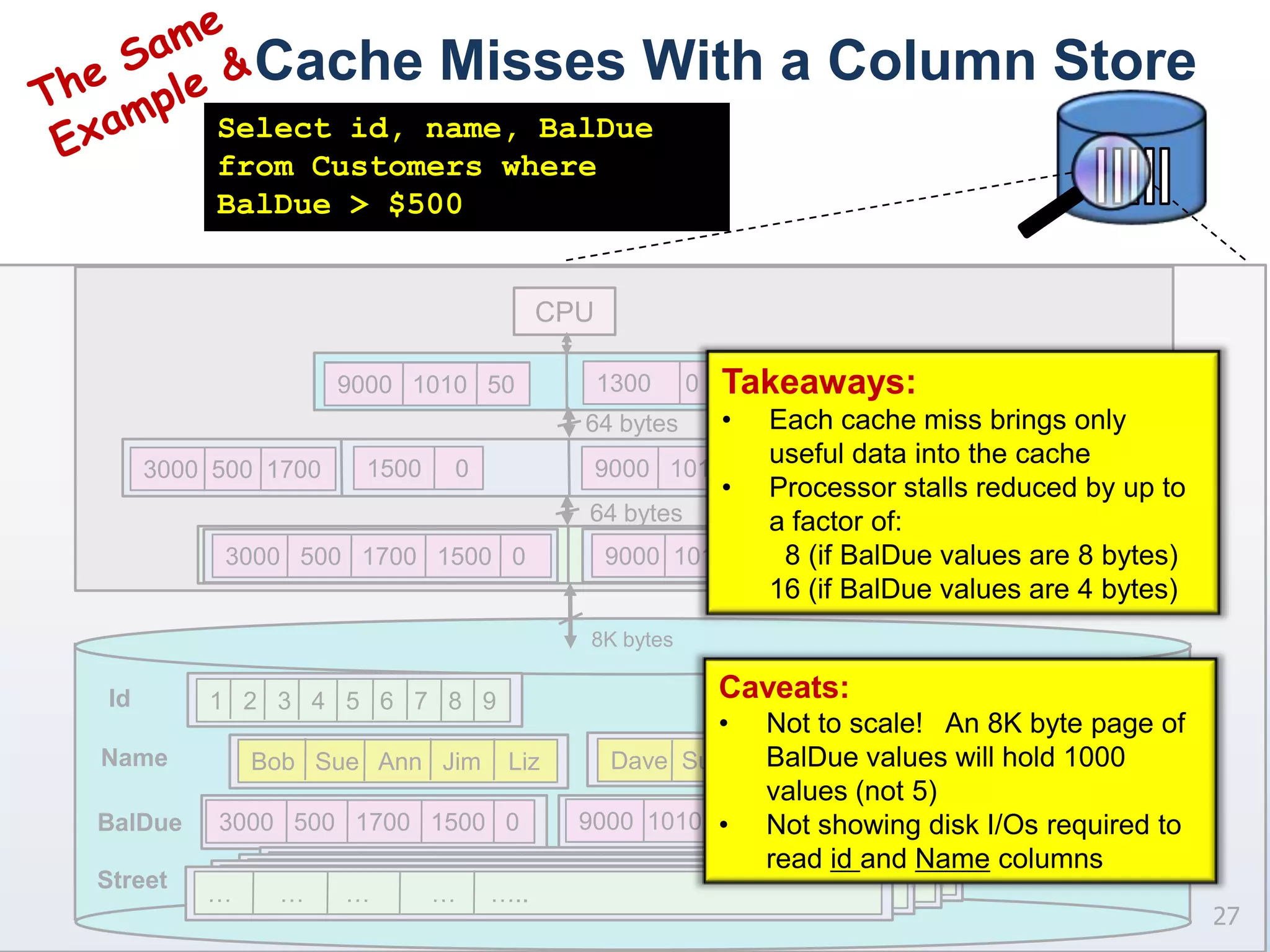




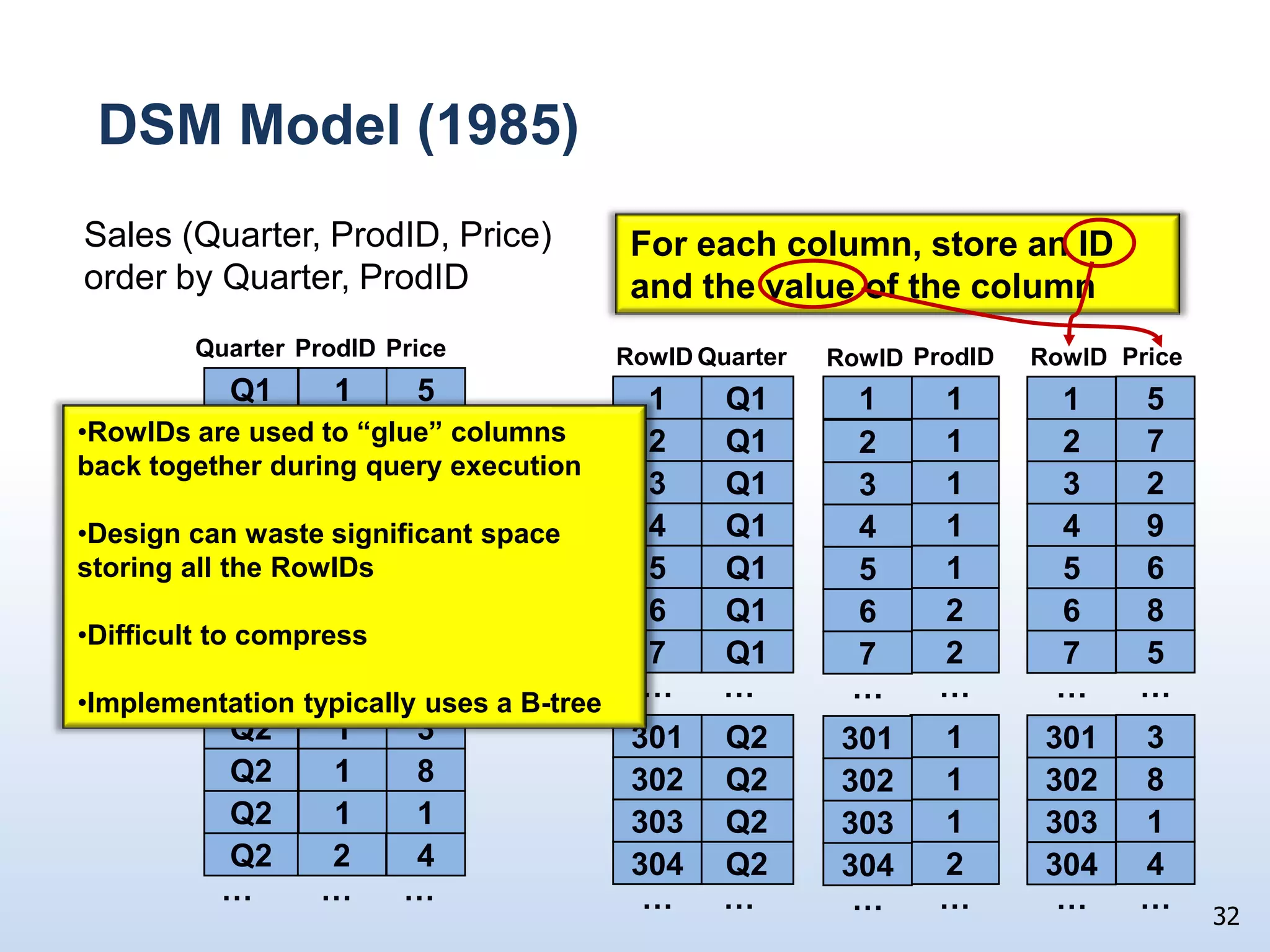




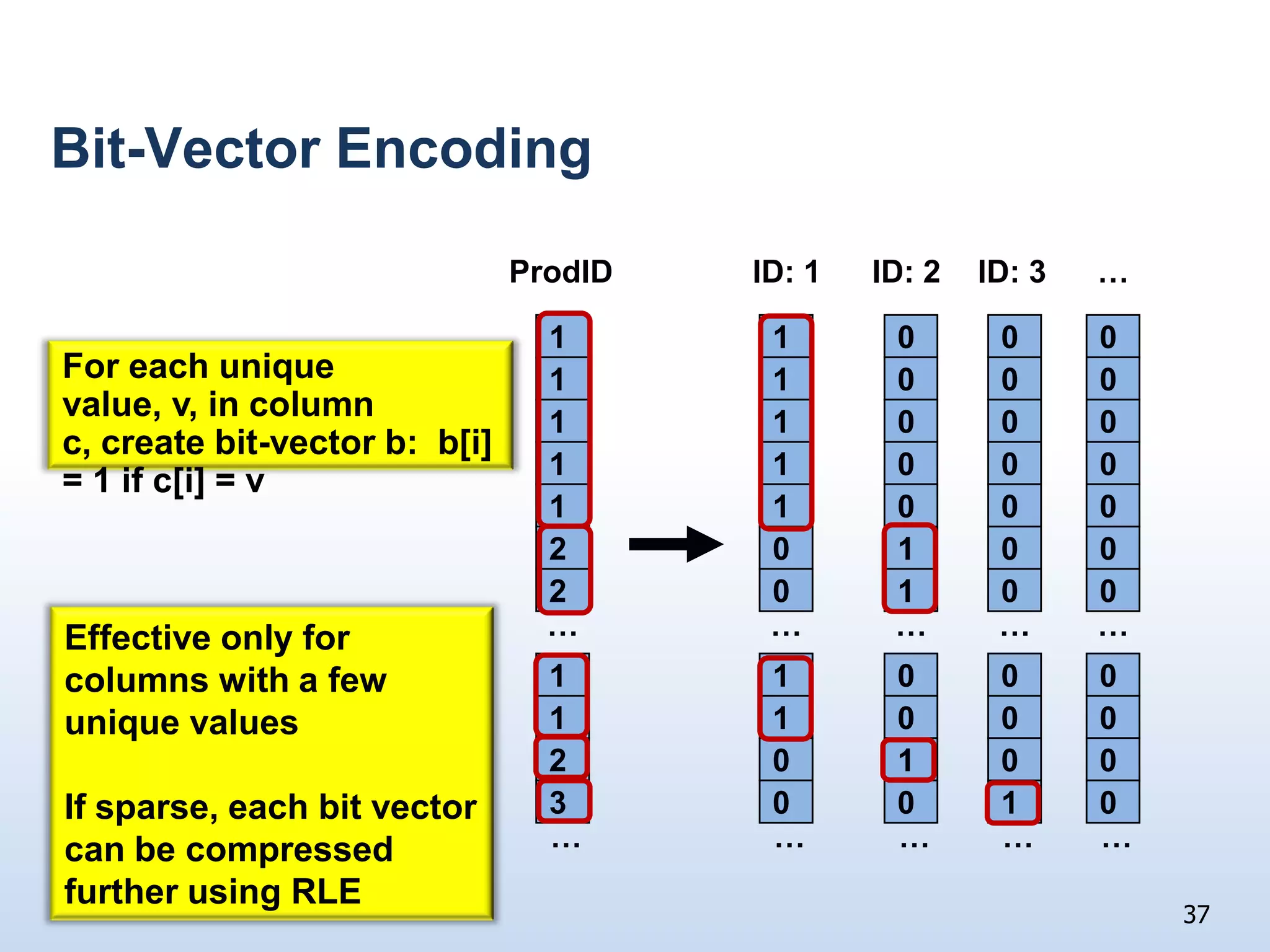
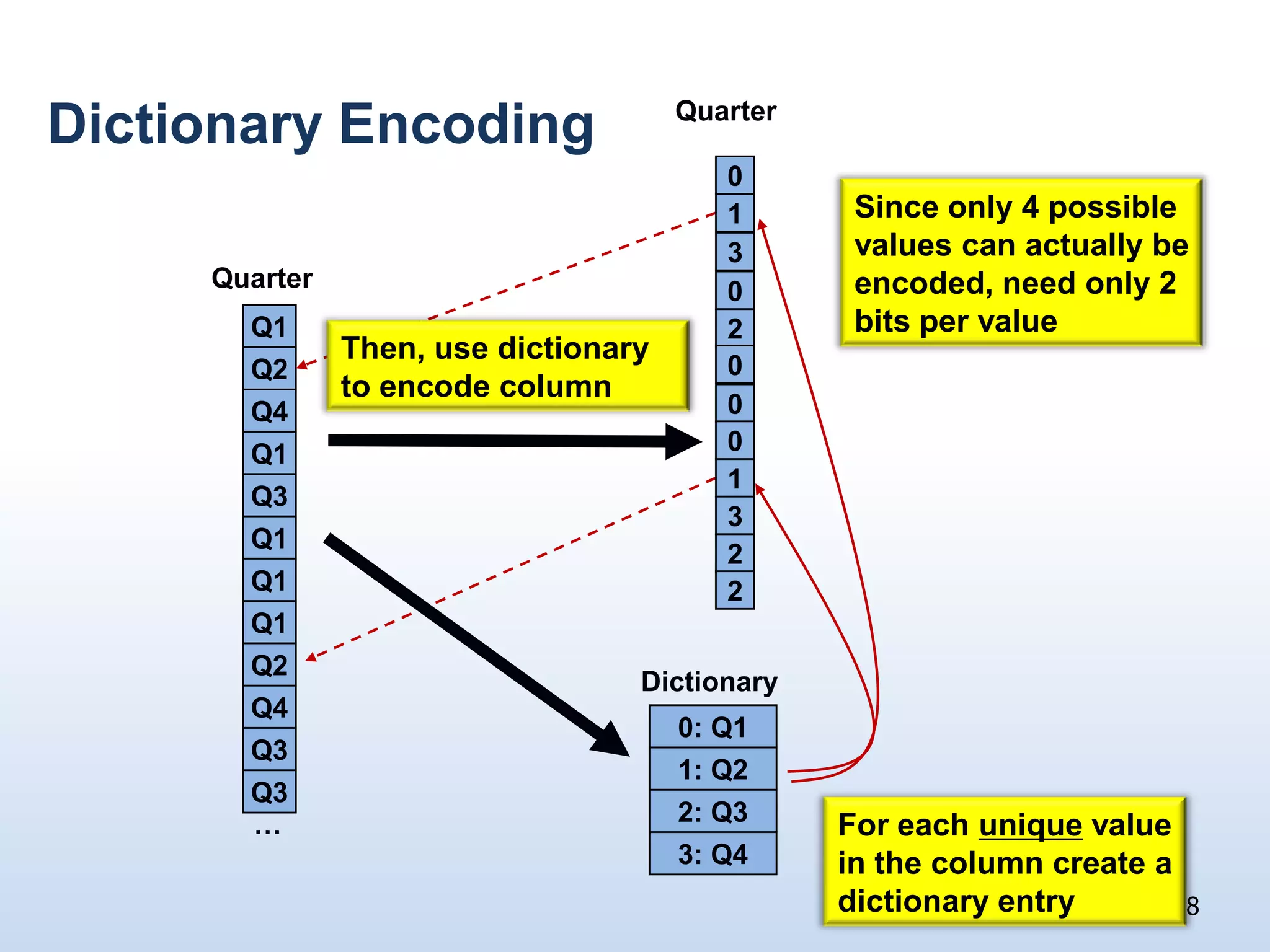

















The document presents a technical discussion led by David J. DeWitt on database system evolution influenced by advancements in CPU, memory, and disks over the past 30 years. It highlights the shift towards specialized database products as general-purpose systems evolve, particularly focusing on the inefficiencies of traditional row-store layouts versus newer column-store designs. DeWitt emphasizes how these trends necessitate changes in database management systems to improve performance and scalability for transaction processing and data warehousing workloads.