Part1: Quest for DataScience 101
•
1 like•582 views

Probability refresher, Bayesian networks, Naive Bayes Classifier.

Recommended
More Related Content
What's hot
What's hot (20)
Similar to Part1: Quest for DataScience 101
Similar to Part1: Quest for DataScience 101 (20)
Recently uploaded
Recently uploaded (20)
Part1: Quest for DataScience 101
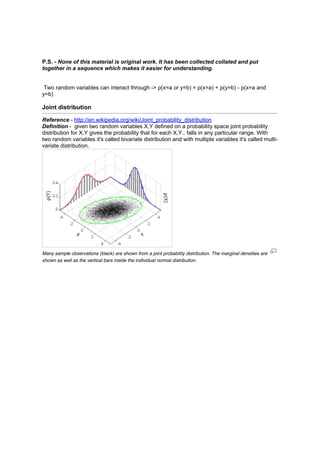
- 1. P.S. - None of this material is original work. It has been collected collated and put together in a sequence which makes it easier for understanding. Two random variables can interact through -> p(x=a or y=b) = p(x=a) + p(y=b) - p(x=a and y=b) Joint distribution Reference - http://en.wikipedia.org/wiki/Joint_probability_distribution Definition - given two random variables X,Y defined on a probability space joint probability distribution for X,Y gives the probability that for each X,Y.. falls in any particular range. With two random variables it's called bivariate distribution and with multiple variables it's called multi- variate distribution. Many sample observations (black) are shown from a joint probability distribution. The marginal densities are shown as well as the vertical bars inside the individual normal distribution.
- 2. three random variables I, D, G having 2,2 and 3 possible values respectively. The joint distribution is represented in the table and since this is a probability distribution it needs to sum unto 1. Joint distribution can be thought of as truth table of all possible combinations summing unto to 1. Let's say we are given g1 this results in removing all other other rows from the join probability distribution and overall reduces our probability distribution space to look at which is depicted in the table below.
- 3. the above itself is not a probability distribution in itself as it does sum to 1 so we need to normalize the distribution To normalize the distribution we sum up all the probabilities which come unto 0.447 then we divide the individual probabilities by 0.447 to get a conditional probability distribution of P(I, D| g1) i.e. probability of I, D given g1.
- 4. We have the joint probability distribution of I,D random variables however we are interested in looking at only a subset of random variables in this case let's say D then how we produce that is adding up all d0's and adding up all d1's. Formal definition of Marginal Distribution Reference - http://en.wikipedia.org/wiki/Marginal_density Definition - Distribution of a collection of subset of random variables. It provides various values for a variable in a subset without reference to the other variables. How it differs from Conditional Distribution - It gives the probabilities contingent upon the values of other variables. Details - Marginal variable refers to those variables which are being retained in the subset. Example - Two-variable case [edit] x1 x2 x3 x4 py(Y)↓ y1 4⁄32 2⁄32 1⁄32 1⁄32 8⁄32 y2 2⁄32 4⁄32 1⁄32 1⁄32 8⁄32 y3 2⁄32 2⁄32 2⁄32 2⁄32 8⁄32 y4 8⁄32 0 0 0 8⁄32 px(X) → 16⁄32 8⁄32 4⁄32 4⁄32 32⁄32 Joint and marginal distributions of a pair of discrete, random variables X,Y having nonzero mutual informationI(X; Y). The values of the joint distribution are in the 4×4 square, and the values of the marginal distributions are along the right and bottom margins.
- 5. Where is it used - Any data analysis involves a wider set of random variables but then the attention is being limited to a reduced number of those random variables. Several different analysis may be done each treating a different subset of variables as marginal variables. Notation - Given two random variables X, Y whose joint distribution is known the marginal distribution of X is simply the probability distribution of X averaging over the information of Y. This is typically calculated by summing or integrating the joint probability distribution over Y. Example illustrating Joint, Conditional & Marginal distribution talk above.
- 8. Reference Link for above example - http://ocw.metu.edu.tr/pluginfile.php/2277/mod_resource/content/0/ocw_iam530/2.Conditional %20Probability%20and%20Bayes%20Theorem.pdf Some talk about distributions Poisson distribution Discrete probability distribution that expresses the probability of a given number of events occurring in a fixed interval of time and space if these events occur with a known average rate and independently of time since the last occurred event. Example - someone typically gets 4 pieces of mail everyday, there will be however a certain spread sometimes little more, sometimes little less and sometimes nothing at all. Given an average rate for a certain period of observation (pieces of mail per day) and assuming the mix of process produces an event flow which is random, poisson distribution specifies how likely is it that the count will be 3 or 5 or 10 during one period of observation. It predicts the degree of spread around a known average rate of occurrence. Binomial distribution Discrete probability distribution of number of successes in a sequence of 'n' independent yes/no experiments each of which yields success with a probability p. Example problem - Suppose a biased coin comes up heads with probability 0.3 when tossed. What is the probability of achieving 0, 1,..., 6 heads after six tosses?
- 9. Bernoulli distribution discrete probability distribution, which takes value 1 with success probability and value 0 with failure probability . Special case of binomial distribution where n=1. Statical Modeling Constructing a stochastic model to predict behavior of a random process. First task is to determine a set of statistics which captures behavior of random process Given this stats second task is correlate these stats into an accurate model. It should be capable of predicting the output of the process. Bayesian Networks The above picture represents five random variables each of which can take multiple values and we have represented a dependency graph between the random variables. Constructing a conditional probability distribution in a bayseian network
- 10. P(D) - probability distribution of difficulty level has two values d0 and d1 P(I) - probability distribution of intelligence has two values i0 and i1 P(S| I) - conditional prob dist of S given I P(G | D, I) - conditional prob distribution of Grade given D & I P(L | G ) - CPD of L given G factor of all the given random variables some of them happen to represent a conditional probability distribution. This is the joint probability distribution of all the random variables i.e. like a truth table representing all possible combinations of the different values of random variables. Calculating the joint probability distribution in the above
- 11. example the above example demonstrates how we calculate the joint probability distribution for all the possible combinations. A bayesian network represents a joint distribution by multiplying the CPD for each random variable Xi in the DAG wherein some of the Xi's are CPD's themselves.
- 12. Once you have the joint probability distribution in a bayesian network using the chain rule mentioned above you do causal reasoning. Examples are -. P(L1) prob of getting letter this is the marginal distribution of L1 across the joint probability distribution and can be calculated by adding up all probabilities of L1 across all the possible combinations in the joint probability distribution as explained in the Marganizeld slide at the top. P(L1 | i0) = prob of letter when intelligence is low as highlighted by RED above this is the conditional prob of letter given low intelligence can be done by using the Conditioning Reduction on i0 and Conditioning Renormalizing the joint probability distribution. P(L1 | i0, d1) = prob of letter given low intelligence and difficult course again can be found out using the joint distribution and do Conditioning Reduction i.e. only consider rows with i0 and d1 and then renormalize the distribution. Independence Assumption reaching from Joint Distribution
- 13. first we marginalize the distribution to random variables P(I, D) which is simply done by adding up all the same values for I, D i.e. rows which have i0, d0 add up and so on. Then we marginalize the distribution to P (I) and P(D) respectively from P(I, D) by adding all rows of i0 and i1 respectively. Tools for simulating Bayesian Networks http://reasoning.cs.ucla.edu/sa Naive Bayes Classifier In simple terms, a naive Bayes classifier assumes that the presence or absence of a particular feature is unrelated to the presence or absence of any other feature, given the class variable. For example, a fruit may be considered to be an apple if it is red, round, and about 3" in diameter. A naive Bayes classifier considers each of these features to contribute independently to the probability that this fruit is an apple, regardless of the presence or absence of the other features. An advantage of Naive Bayes is that it only requires a small amount of training data to estimate the parameters (means and variances of the variables) necessary for classification. Because independent variables are assumed, only the variances of the variables for each class need to be determined and not the entire covariance matrix
- 14. .
- 21. P.S. - the challenge with the bag of words is that losses all the information related to the order of words in the document. Cmap - class whose probability is the greatest P.S. - we can drop the denominator as that is probability of a document which is independent of whether which class it belongs to and is a constant quantity.
- 24. computing weights of naive bayes Prior probability of class = how many documents of this class occur/total number of documents. Prob(w|c) is count of that word in that class i.e. joint probability of (word, class) normalized upon total number of words in that class in document. P.S. - there could be a word which does not occur in training set but occurs in test set so it's probability would be zero however we can't afford that since the equation in which we multiply all probabilities given xi will become zero.
- 25. P.S. - To avoid the above problem we add a smoothing of 1 to the numerator and a similarly the cardinality of the size of set to the denominator i.e. a 1 for each w E V P.S - prior probability of a class is total number of documents in that class normalized to total number of documents across classes. P(w|c) = number of w within the class normalized to number of total words in that class.
- 26. Unknown words - just add a 1 to numerator and also a one to the vocabulary size for each unknown word. Naive bayes is very close to language model wherein a sentence model is nothing but multiplication of unigram word models. If we write the above sentence "i love this fun film" and use the prior probabilities assigned by our model to words i.e. P(love | pos class) = 0.1 then using naive bayes we multiply these likelihoods and get a P( s | pos) which when multiplied with P(pos) will give us P(pos | s) as per the Bayes Rule.
- 27. Naive Bayes - A worked example Computing the prior probabilities
- 28. Vocabulary size is 6.
- 29. We calculate the likelihood for tokyo given chinese since tokyo does not occur anywhere in class chinese it's 0 + 1(smoothing)
- 30. Above example it's visible that the P (Cat | Finicial) << P (Cat | Pets) which is an indicative of the actual data. There are X random variables which represent each word in the dictionary and the value of these random variables is X=1 if the word appears in the document and X=0 if the word does not appear in the document with some probability for both cases. So CPD(conditional probability in this case) is the probability of word appears given a category label. This follows are Bernoulli distribution i.e. P(cat | Pets) = 0.3 and P(^cat | Pets) will be 1- p = 0.7. It's a bernoulli distribution since each of the random variables above X have a possible value of 0 or 1 and it's naive bayes since it's make independence assumption that prob of one word appearing given class is independent of probability of another word appearing given same class. Example - if we have two categories above Financial and Pets.
- 31. Use of Bayesian Networks in trouble shooting printer issues in Microsoft Windows operating system.
- 32. Answer probability questions about the system given observations.
- 33. 90 true wheat documents were classified into poultry. The diagonals of the confusion matrix give us the correct classification for each class. In true UK 95 were correctly classified as true UK Example of Recall for True Wheat = Total correctly classified as true wheat = 0 / ( sum of
- 34. element in the row for True Wheat) Example of Precssion for True Wheat = of the documents that we returned how many of them where about true wheat = (Documents about wheat = 0 ) / ( Sum of all the documents that we said about wheat i.e. sum of elements in the column about wheat). Accuracy = Sum of diagonal entries / sum of all the entries in the confusion matrix Advantage of having clean unseen test-set while developing features is to avoid over fitting..so you should work with a Development Test Set to develop features and finally use the test set for testing the classifier. Cross Validation allows to use pools of the training set as dev test set and training set and we choose a different pool each time for a different run to avoid over fitting and eventually we use the combined output of all cross validations..this gives us the advantage of keeping the test set separate from the Training/dev set.
- 35. Naive Bayes is a high bias algorithm i.e. it does over fit badly on a smaller training data set and can be trained very fast for large amount of data.
- 36. Naive Bayes : Using it. 1. Download mallet from http://mallet.cs.umass.edu/quick-start.php 2. Reference Commands to use -> http://www.cs.cmu.edu/afs/cs.cmu.edu/project/cmt- 40/Nice/Urdu-MT/code/Tools/POS/postagger/mallet_0.4/doc/command-line-classification.html 3. Using the classifier -> http://mallet.cs.umass.edu/classification.php Example : Classify between german and english documents Mallet comes with the sample data for this and we will use multi nominal distribution. Commands 1. Convert training data to feature vectors. Here english and german are two output classes and training data is available in individual files under the directory named "dn", "en" 2. ./bin/text2vectors -Xmx400m --input ./sample-data/web/* --output en-german.vectors [ Create feature vectors] 3. ./bin/vectors2info -Xmx400m --input en-german.vectors --print-labels [ Check the classes in the vectors] 3. ./bin/vectors2classify -Xmx400m --input en-german.vectors --trainer NaiveBayes -- training-portion 0.7 --num-trials 3 --output-classifier NB-en-de.model [ Train a classifier using 70% data for training and 30% for testing. Num Trails will do three attempts each with a random split of 70 % training data and 30% testing data 4. ./bin/mallet classify-dir --input tst --output - --classifier NB-en-de.model.trial2 [ Here you can use the one of the trained model. I have created a german document from Yahoo news and saved as tst.txt inside directory tst and here how the output looks like -> file:/Users/inderbir.singh/IdeaProjects/mallet-2.0.6/tst/tst.txt de 1.0 en 6.918971438888891E-39