Download as PDF, PPTX











![#ESCBOS
Bit-‐banding on Cortex-‐M (3)
Bit-‐banding
memory
remap
structure:
• Words
(32bit)
in
the
alias
region
map
to
individual
bits
in
the
normal
SRAM
memory
• The
remapped
writes
are
guaranteed
atomic
ProgrammersModel
• The alias word at 0x2200001C maps to bit [7] of the bit-band byte at 0x20000000: 0x2200001C
= 0x22000000 + (0*32) + 7*4.
Figure 3-2 Bit-band mapping
0x23FFFFE4
0x22000004
0x23FFFFE00x23FFFFE80x23FFFFEC0x23FFFFF00x23FFFFF40x23FFFFF80x23FFFFFC
0x220000000x220000140x220000180x2200001C 0x220000080x22000010 0x2200000C
32MB alias region
0
7 0
07
0x200000000x200000010x200000020x20000003
6 5 4 3 2 1 07 6 5 4 3 2 1 7 6 5 4 3 2 1 07 6 5 4 3 2 1
07 6 5 4 3 2 1 6 5 4 3 2 107 6 5 4 3 2 1 07 6 5 4 3 2 1
0x200FFFFC0x200FFFFD0x200FFFFE0x200FFFFF
1MB SRAM bit-band region
source:
ARM
DDI
0439C,
page
3-‐20](https://image.slidesharecdn.com/9881ec9f-9a64-4068-a3d0-b45aa090b193-160416190942/85/ParallelLogicToEventDrivenFirmware_Doin-14-320.jpg)

![#ESCBOS
Event-‐driven scheduling (2)
typedef uint32_t * PFLAGS_T;
typedef volatile struct ipc_flags_t { // any object of this type is volatile qualified
PFLAGS_T pflags_bits; // Ptr to the 'bit bandable' word with 32 ipc bits
PFLAGS_T pflags_base; // Ptr to the base of the word alias array
} IPC_FLAGS_T;
// for the ipc macros, pass a IPC_FLAGS_T struct
#define get_bit(flags, bit) ((flags).pflags_base[(bit)])
#define set_bit(flags, bit) ((flags).pflags_base[(bit)] = 1)
#define clr_bit(flags, bit) ((flags).pflags_base[(bit)] = 0)
#define toggle(flags, bit) ((flags).pflags_base[(bit)] ^= 1)
#define event(flags, bit) (get_bit((flags), (bit)) ? ((clr_bit((flags), (bit))), 1) : 0)
#define clr_bits(flags) (*((flags).pflags_bits) = 0)
#define get_bits(flags, bitmask) (*((flags).pflags_bits) & (bitmask))
extern void init_ipc(void);
extern uint32_t request_ipc_word(IPC_FLAGS_T *pflags);](https://image.slidesharecdn.com/9881ec9f-9a64-4068-a3d0-b45aa090b193-160416190942/85/ParallelLogicToEventDrivenFirmware_Doin-16-320.jpg)
![#ESCBOS
Event-‐driven scheduling (3)
#define set_bit(flags, bit) ((flags).pflags_base[(bit)] = 1)
so:
set_bit(my_flags, 7);
translates to:
myflags.pflags_base[7] = 1;
where:
IPC_FLAGS_T myflags;
myflags.pflags_base = (PFLAGS_T) 0x22000000;
myflags.pflags_bits = (PFLAGS_T) 0x20000000;
...
0x00000001
bit-‐band
alias
area
0x22000000
0x22000080
bit-‐band
region
0x00000080
0x20000000](https://image.slidesharecdn.com/9881ec9f-9a64-4068-a3d0-b45aa090b193-160416190942/85/ParallelLogicToEventDrivenFirmware_Doin-17-320.jpg)
![#ESCBOS
Event-‐driven scheduling (4)
#define event(flags, bit) (get_bit((flags), (bit)) ? ((clr_bit((flags), (bit))), 1) : 0)
so:
if(event(my_flags, 7))
{
...
}
translates to:
if(((myflags.pflags_base[7] = 0), 1))
after evaluation of the side effect, becomes:
if((1))
comma
operator
side
effect
part
result](https://image.slidesharecdn.com/9881ec9f-9a64-4068-a3d0-b45aa090b193-160416190942/85/ParallelLogicToEventDrivenFirmware_Doin-18-320.jpg)



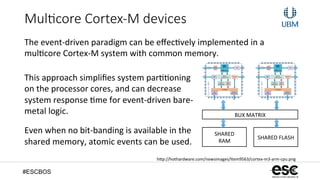



The document discusses parallel logic concepts from hardware design and how they can be applied to event-driven firmware development. It describes how VHDL uses process blocks with sensitivity lists to simulate parallel hardware logic. This allows describing sections of sequential logic that run concurrently. The document explains how similar concepts of process blocks and sensitivity lists can be implemented in firmware to achieve low-cost multitasking. It also discusses how ARM Cortex-M processors support efficient bit-banding memory remapping that is useful for inter-process communication.



























































