Downloaded 46 times






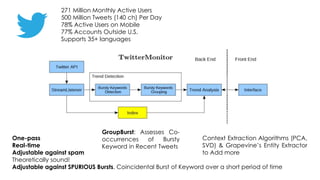


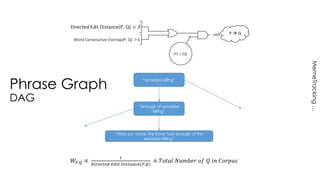
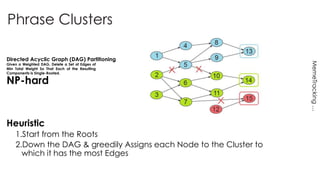

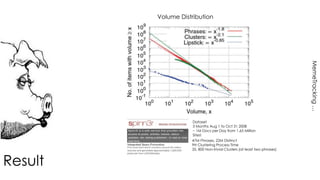
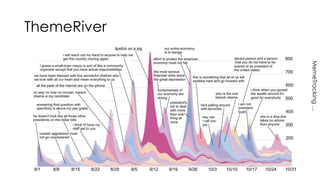



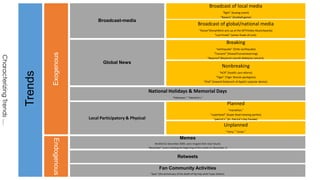



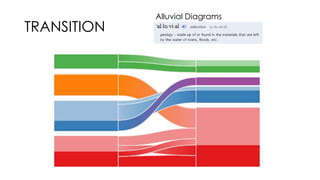


The document discusses methods for detecting, tracking, and characterizing trends on social networks. It describes approaches like TwitterMonitor and MemeTracker that are used to detect trends from Twitter data in real-time. It also discusses how memes and phrases spread and evolve over time through social networks and news media. The document proposes features for automatically characterizing trends as exogenous or endogenous based on their content, interactions, timing, participation and social network patterns.










































































