Download as PDF, PPTX



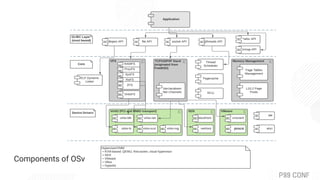











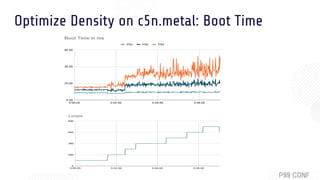
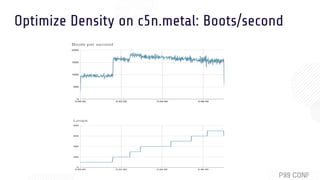
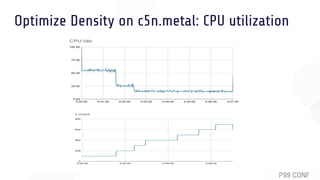









The document discusses OSv, an open-source unikernel designed to run single unmodified Linux applications securely as microVMs. It highlights its strengths for stateless and serverless workloads, including fast boot times, low memory usage, and optimized networking, along with techniques to minimize kernel size for improved performance. It also presents experimental results comparing OSv with traditional Linux VMs across various applications and workloads, demonstrating superior request handling and lower latencies.


![[OpenStack Days Korea 2016] Track1 - 카카오는 오픈스택 기반으로 어떻게 5000VM을 운영하고 있을까?](https://cdn.slidesharecdn.com/ss_thumbnails/16kakao-160226171853-thumbnail.jpg?width=640&height=640&fit=bounds)

![[KubeCon EU 2022] Running containerd and k3s on macOS](https://cdn.slidesharecdn.com/ss_thumbnails/lima-220519142933-3d747f68-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[Paris Container Day 2021] nerdctl: yet another Docker & Docker Compose imple...](https://cdn.slidesharecdn.com/ss_thumbnails/paris-210602095121-thumbnail.jpg?width=640&height=640&fit=bounds)





























































