Download as PDF, PPTX

















![LUA scripting
SCRIPT LOAD "return {KEYS[1],KEYS[2]}"
"3905aac1828a8f75707b48e446988eaaeb173f13"
EVALSHA
3905aac1828a8f75707b48e446988eaaeb173f13 2 user:1
user:2
1) "user:1"
2) "user:2"](https://image.slidesharecdn.com/redistechmeetup-141031085727-conversion-gate01/75/Redis-for-duplicate-detection-on-real-time-stream-19-2048.jpg)





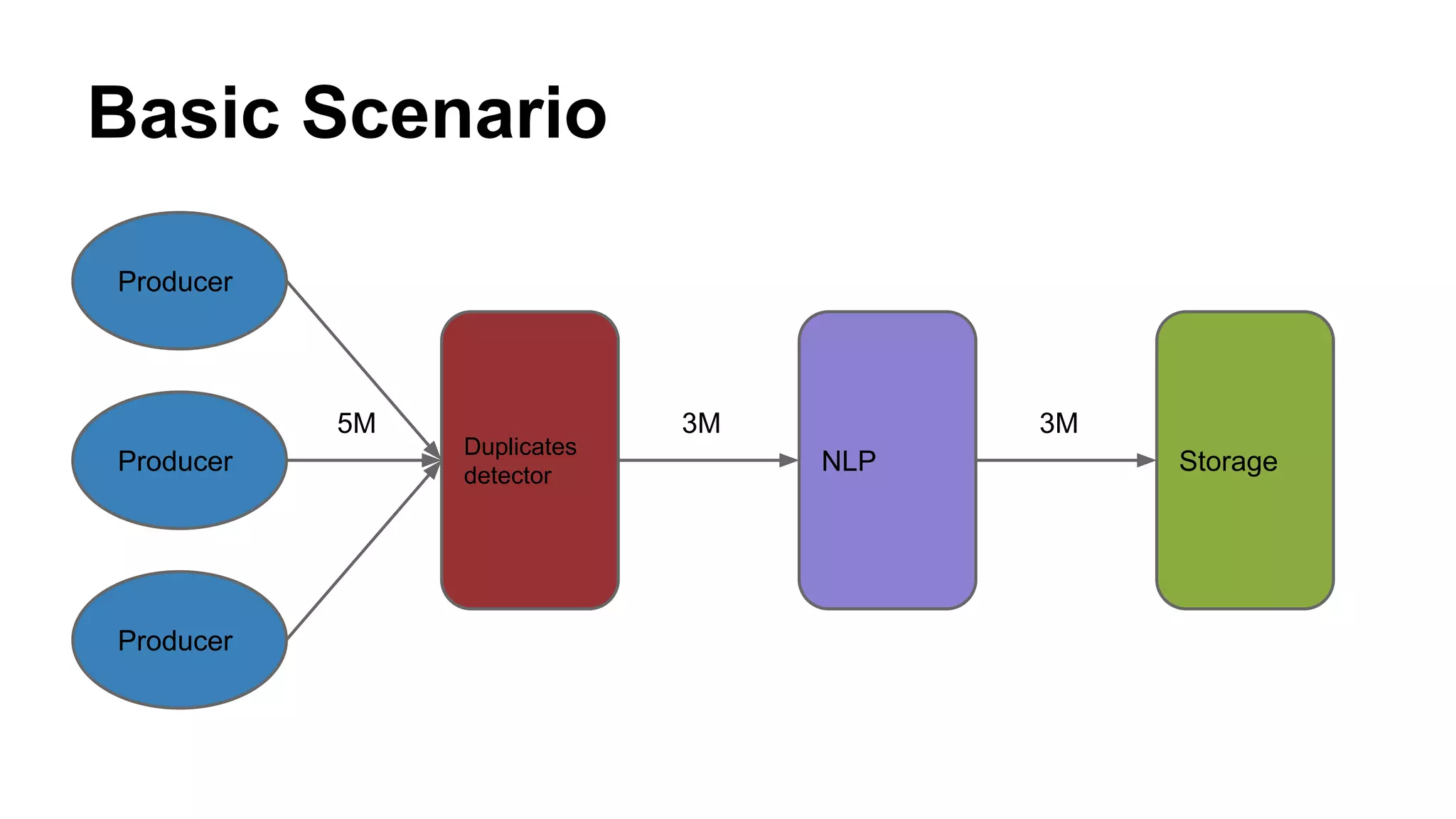



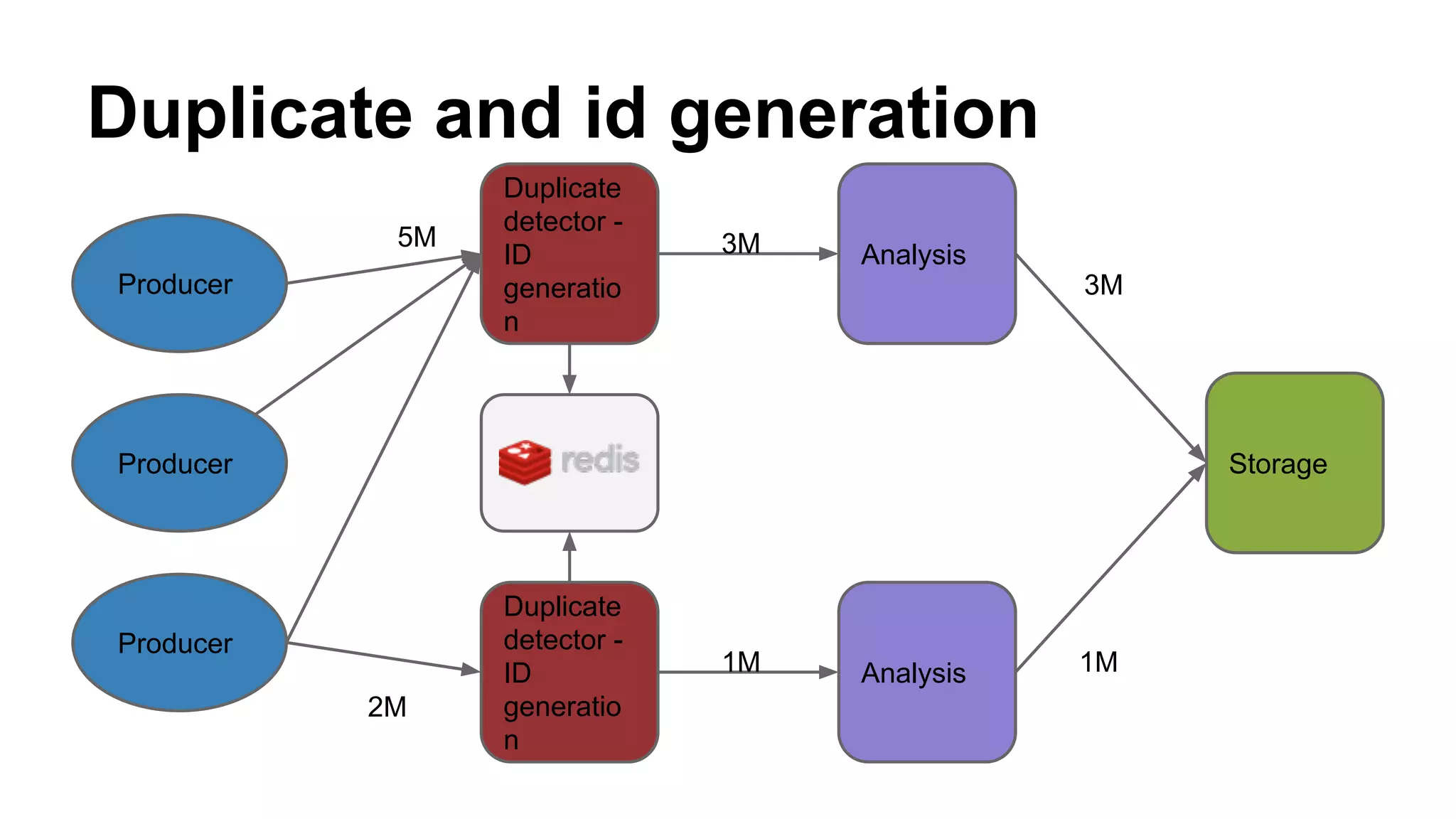









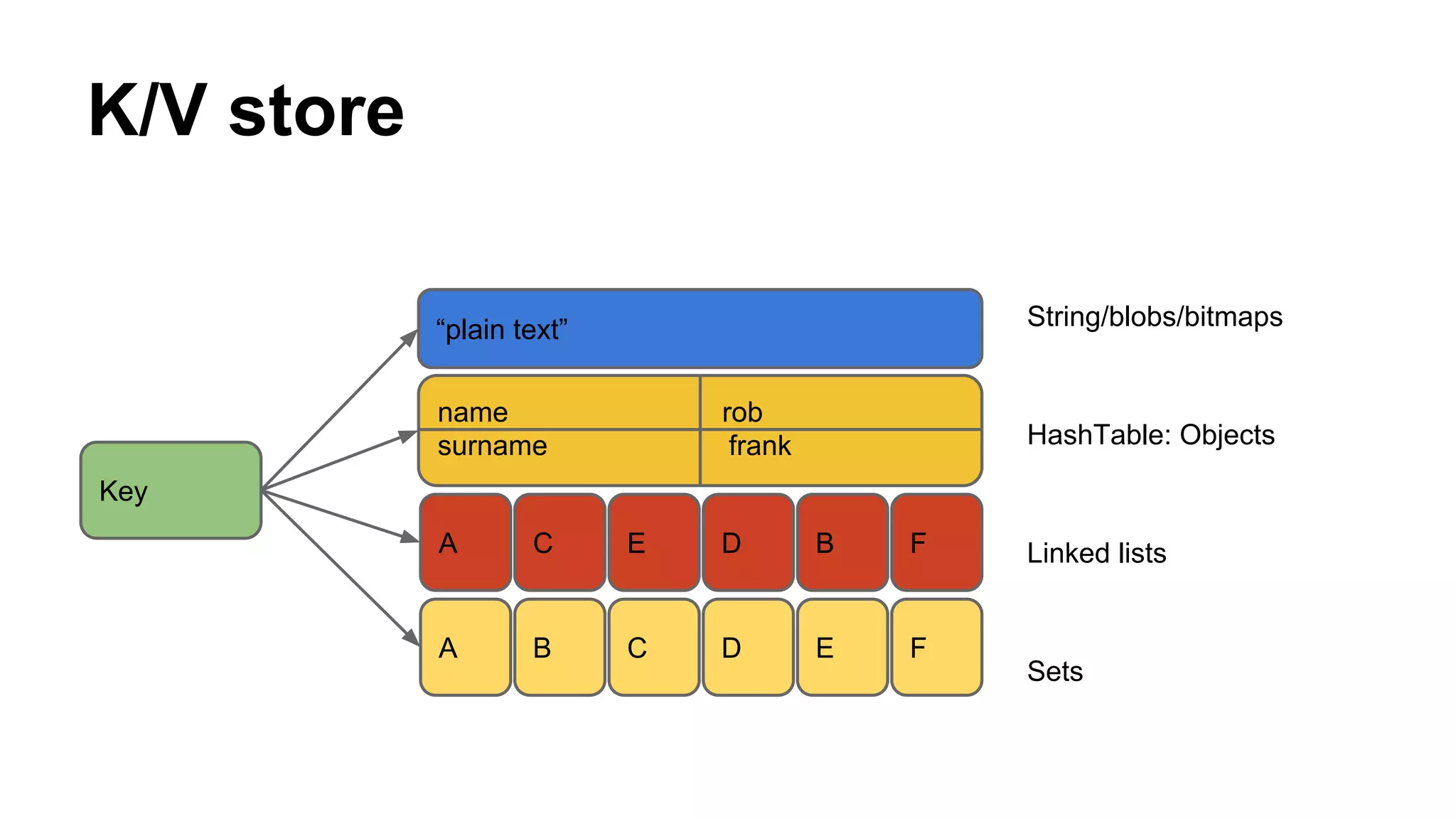
This document summarizes a presentation about using Redis for duplicate document detection in a real-time data stream. The key points covered include: - Redis is used to map external document IDs to internal IDs and cache these mappings to detect duplicates efficiently - Lua scripting is used to generate IDs and check for duplicates in an atomic way - Redis data structures like hashes and counters help count documents and store metadata efficiently - A production deployment involved a single Redis server handling 70M keys and 10GB of RAM, with replication for high availability








![[CNCF TAG-Runtime 2022-10-06] Lima](https://cdn.slidesharecdn.com/ss_thumbnails/cncftag-runtime2022-10-06lima-221007111035-3bb96dd9-thumbnail.jpg?width=640&height=640&fit=bounds)













































































