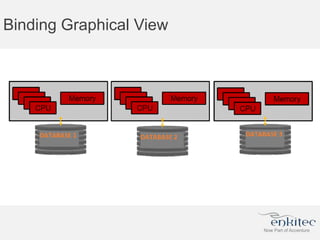
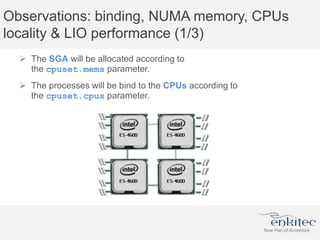
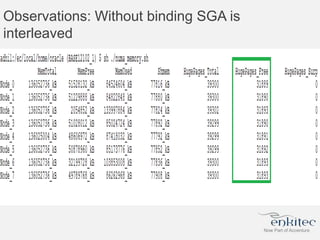
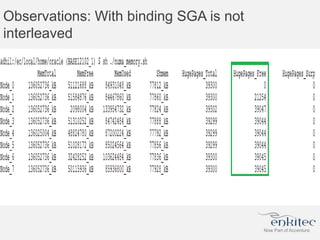
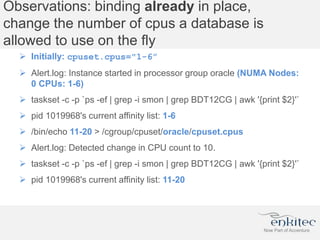
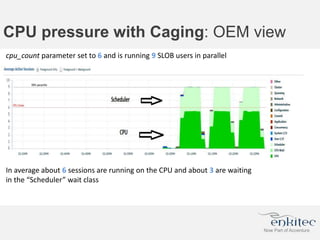
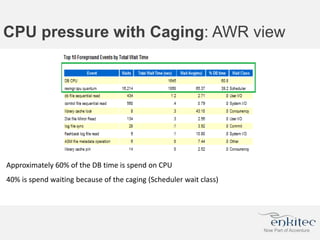
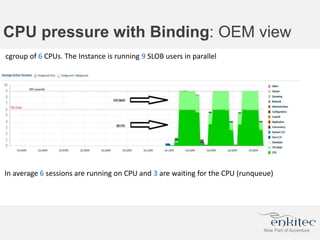
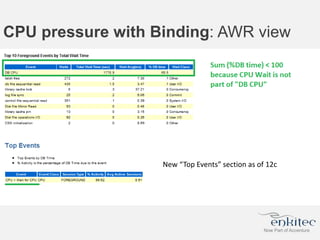
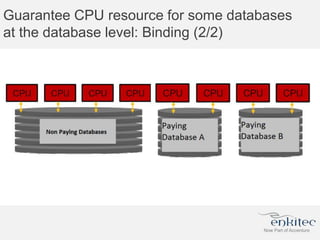
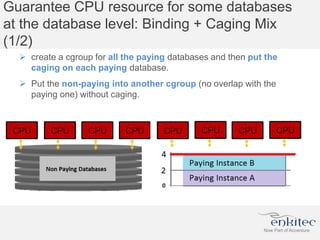
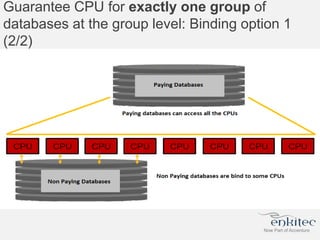
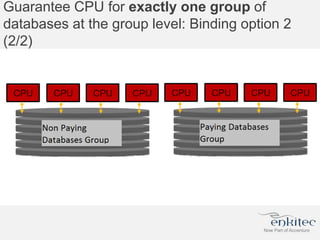
The document compares two methods for limiting CPU usage of databases on the same server: instance caging and processor_group_name binding. It provides facts about how each method works, observations on performance differences, and examples of customer cases where each method may be best. Instance caging allows limiting CPU count online but the SGA is interleaved, while binding groups databases to specific CPUs requiring a restart but keeps the SGA local. The best choice depends on factors like database count and whether guaranteed CPU resources are needed for some databases.