Download as PDF, PPTX














![24 - 26 Sept. 2013
Maxence Dunnewind - OpenNebulaConf
16
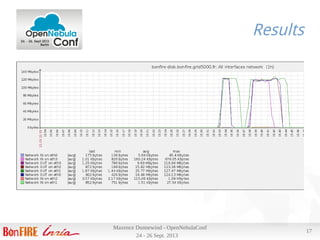
Results
Deploying a VM using our most commonly used image (700M) :
● Scheduler interval is 10s, and can deploy 30 VMs per run, 3 per host
● Takes ~ 13s from ACTIVE to RUNNING
● Image copy ~ 7s
Tue Sep 24 22:51:11 2013 [TM][I]: 734003200 bytes (734 MB) copied, 6.49748 s, 113 MB/s'
● 4 VMs on 4 nodes (one per node) from submission to RUNNING in 17
s , 12 VMs in 2 minutes 6s (+/- 10s)
● Transfer between 106 and 113 MB/s on the 4 nodes at same time
● Thanks to efficient 802.3ad bonding](https://image.slidesharecdn.com/openneublaconf2013-131007081809-phpapp02/85/How-can-OpenNebula-fit-your-needs-OpenNebulaConf-2013-16-320.jpg)



Maxence Dunnewind discusses the integration of OpenNebula within the Bonfire European project aimed at enhancing cloud research capabilities. He highlights the challenges of using SSH and NFS transfer methods for virtual machine deployment and proposes a customized transfer manager to improve performance. The optimizations yielded significant improvements in deployment speed, reduced CPU usage, and better utilization of network resources without requiring additional hardware investment.







































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)





