Download as PDF, PPTX




































Bighead is Airbnb's machine learning infrastructure that was created to: 1) Standardize and simplify the ML development workflow; 2) Reduce the time and effort to build ML models from weeks/months to days/weeks; and 3) Enable more teams at Airbnb to utilize ML. It provides services for data management, model training/scoring, production deployment, and model management to make the ML process more efficient and consistent across teams. Bighead is built on open source technologies like Spark, TensorFlow, and Kubernetes but addresses gaps to fully support the end-to-end ML pipeline.
Overview of the presentation on Airbnb’s end-to-end machine learning infrastructure.
In 2016, challenges included slow model building and few models in production; ML was impactful yet underutilized in various areas.
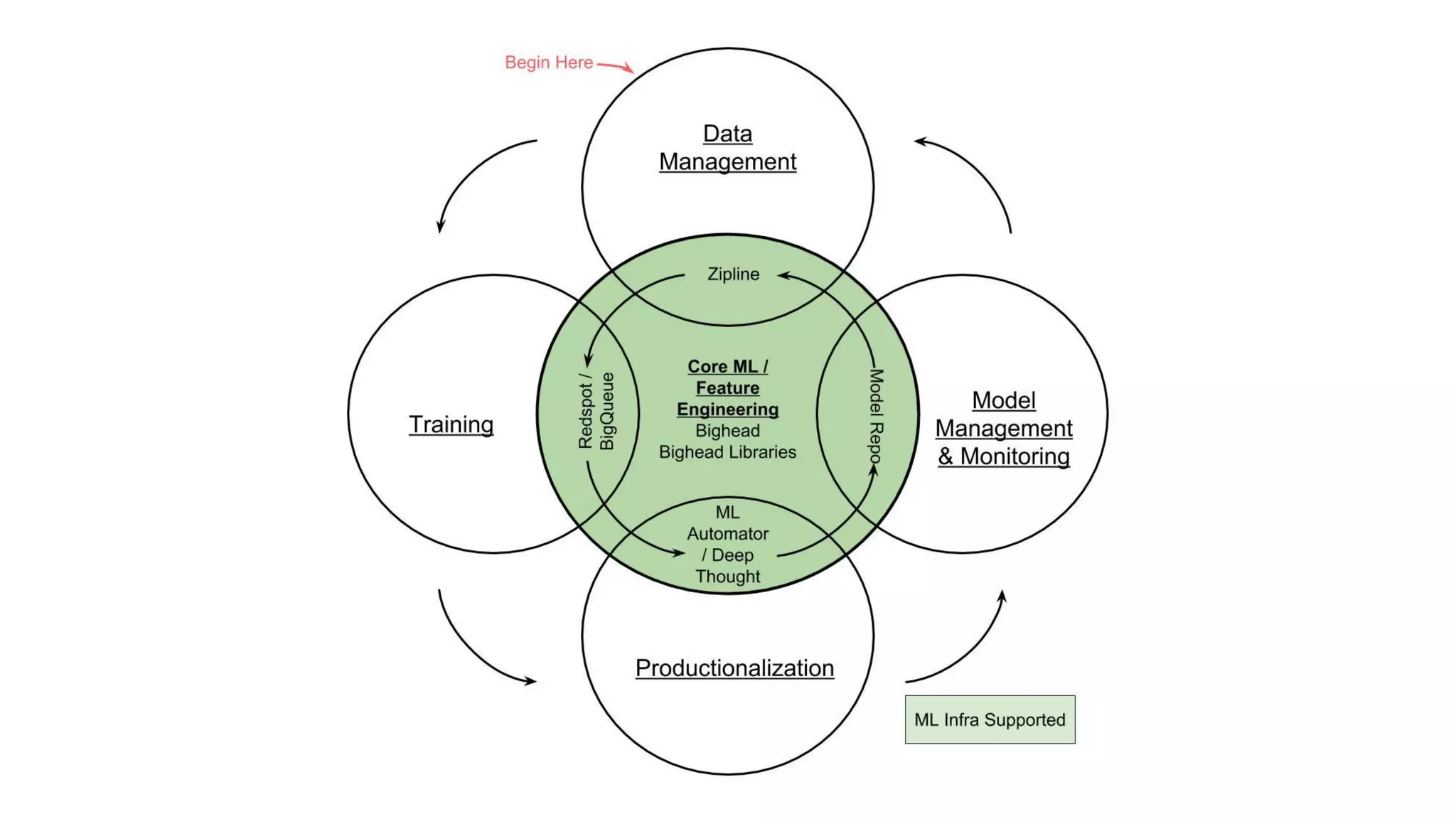
Vision: build ML apps with shared resources. Value: simplifies workflow, supports cross-company sharing, and reduces complexity.
Motivations for developing Bighead included fragmentation in ML workflows and the challenge to initiate ML work.
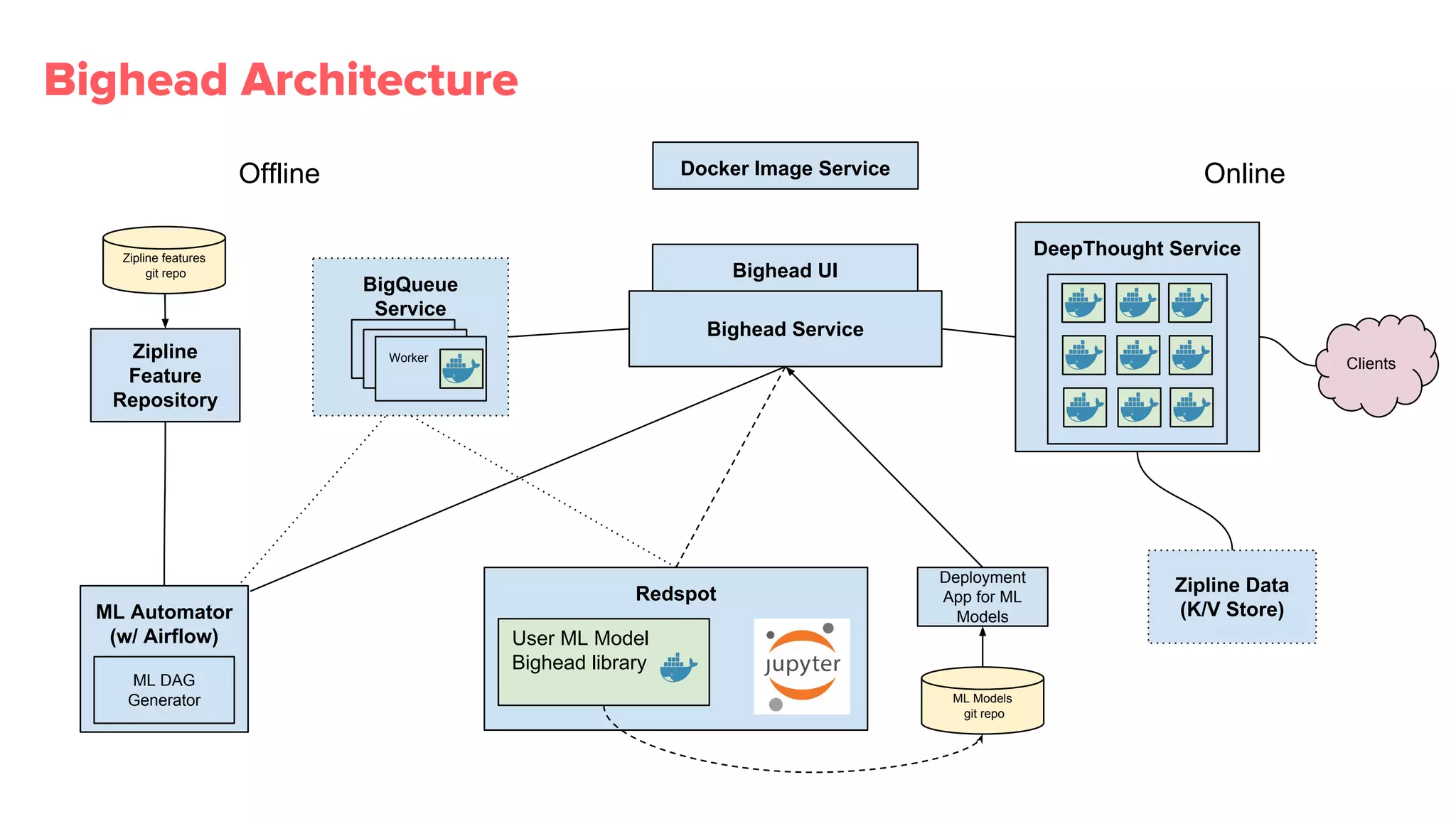
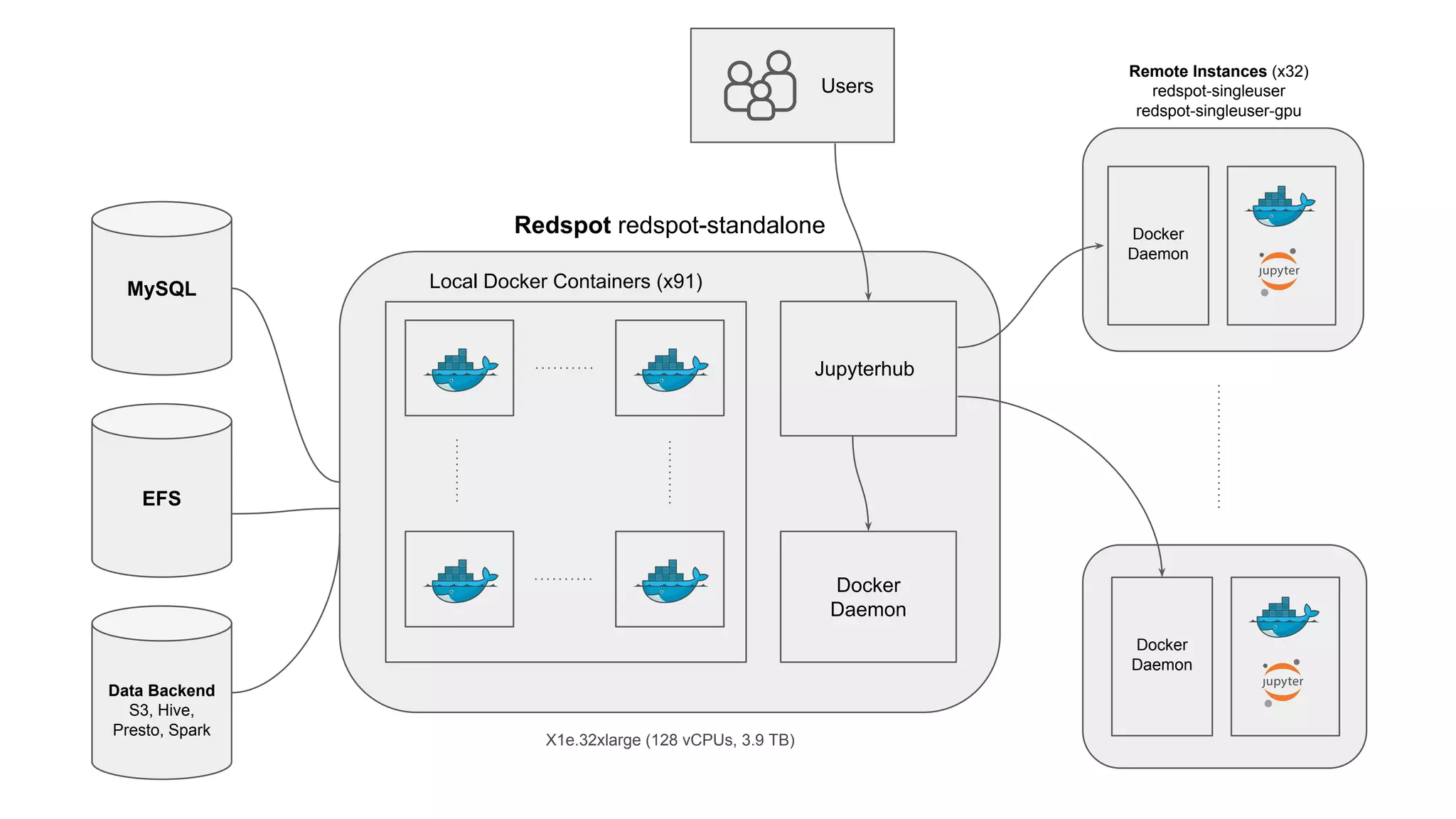
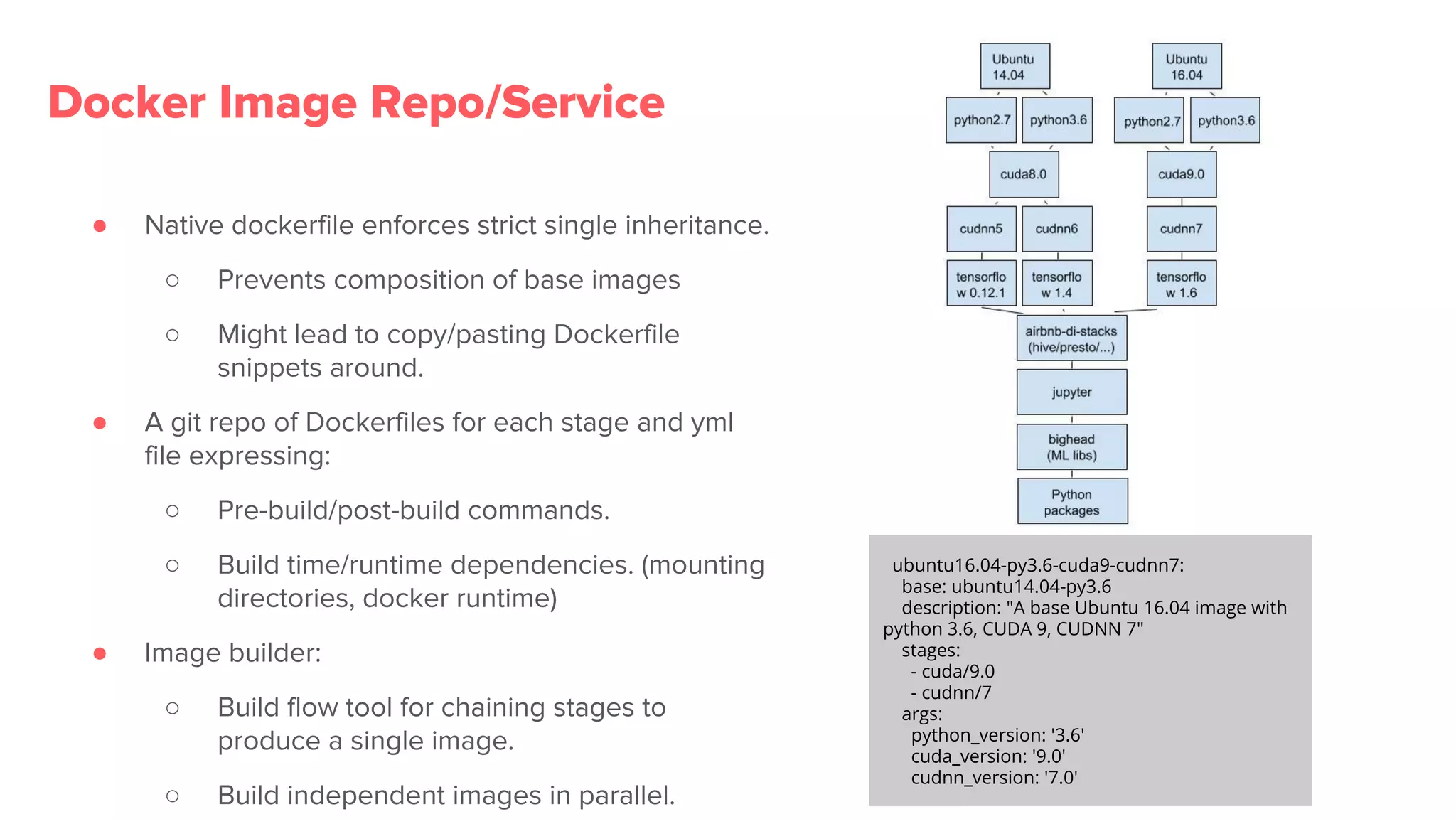
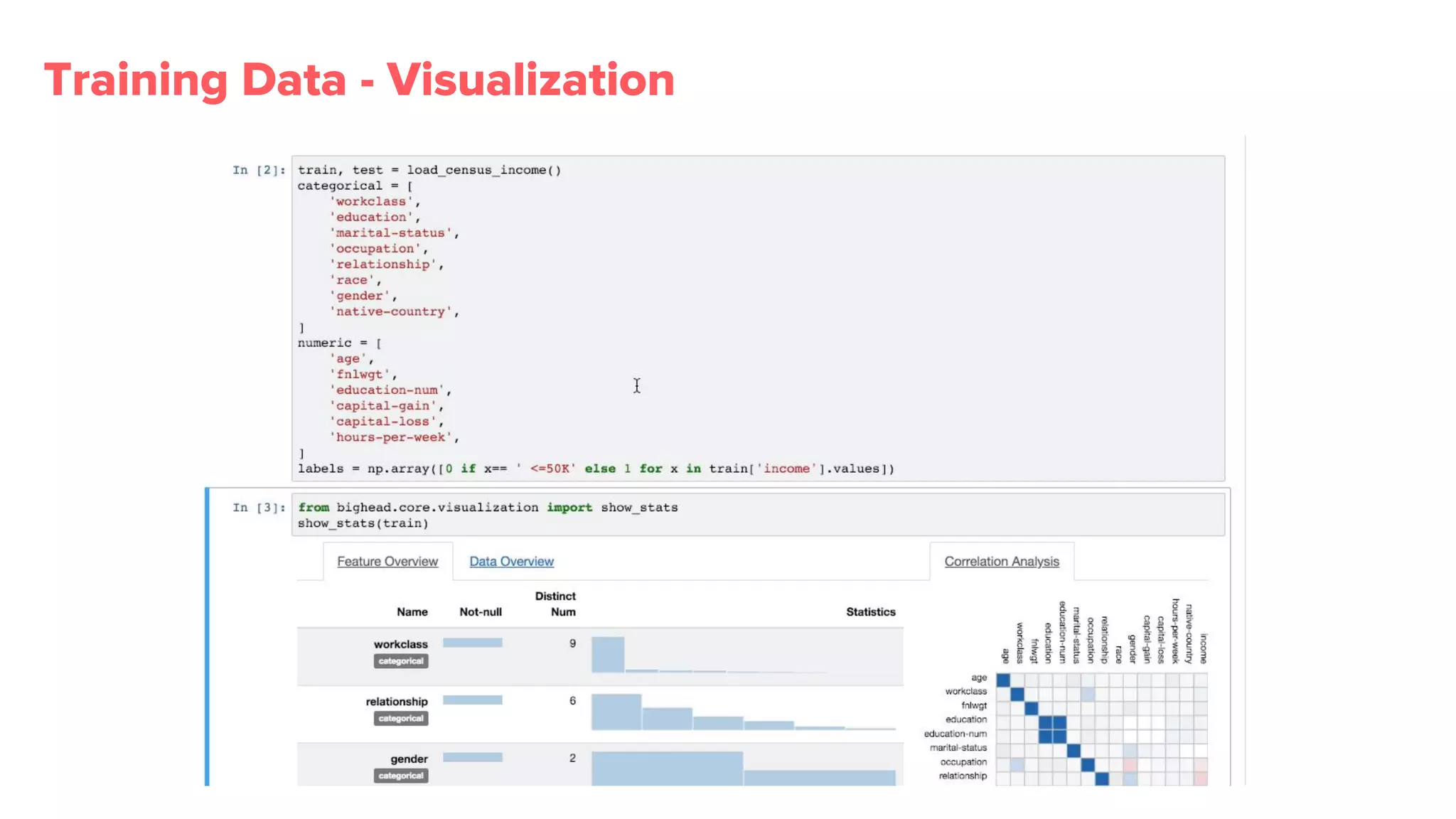
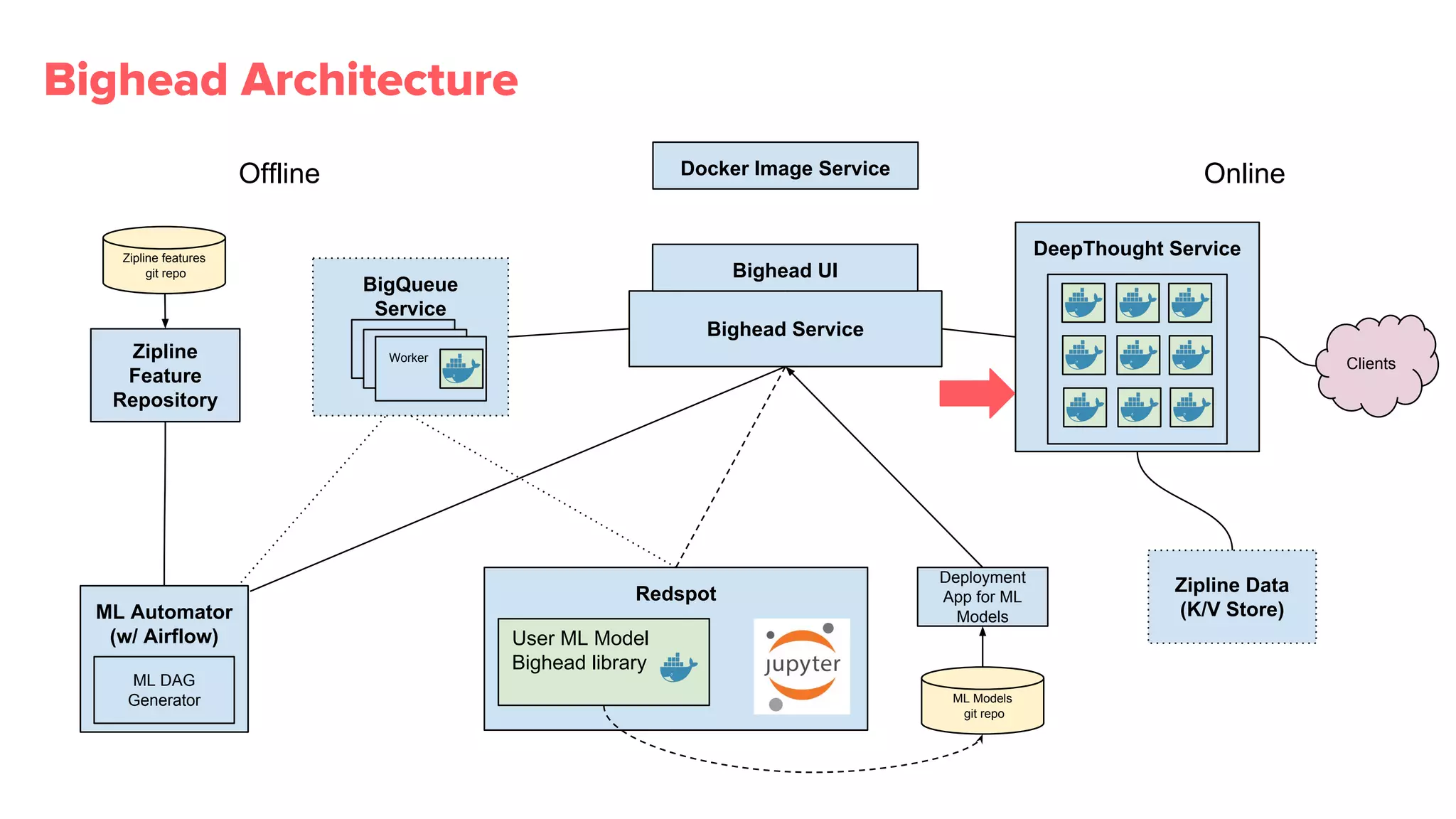
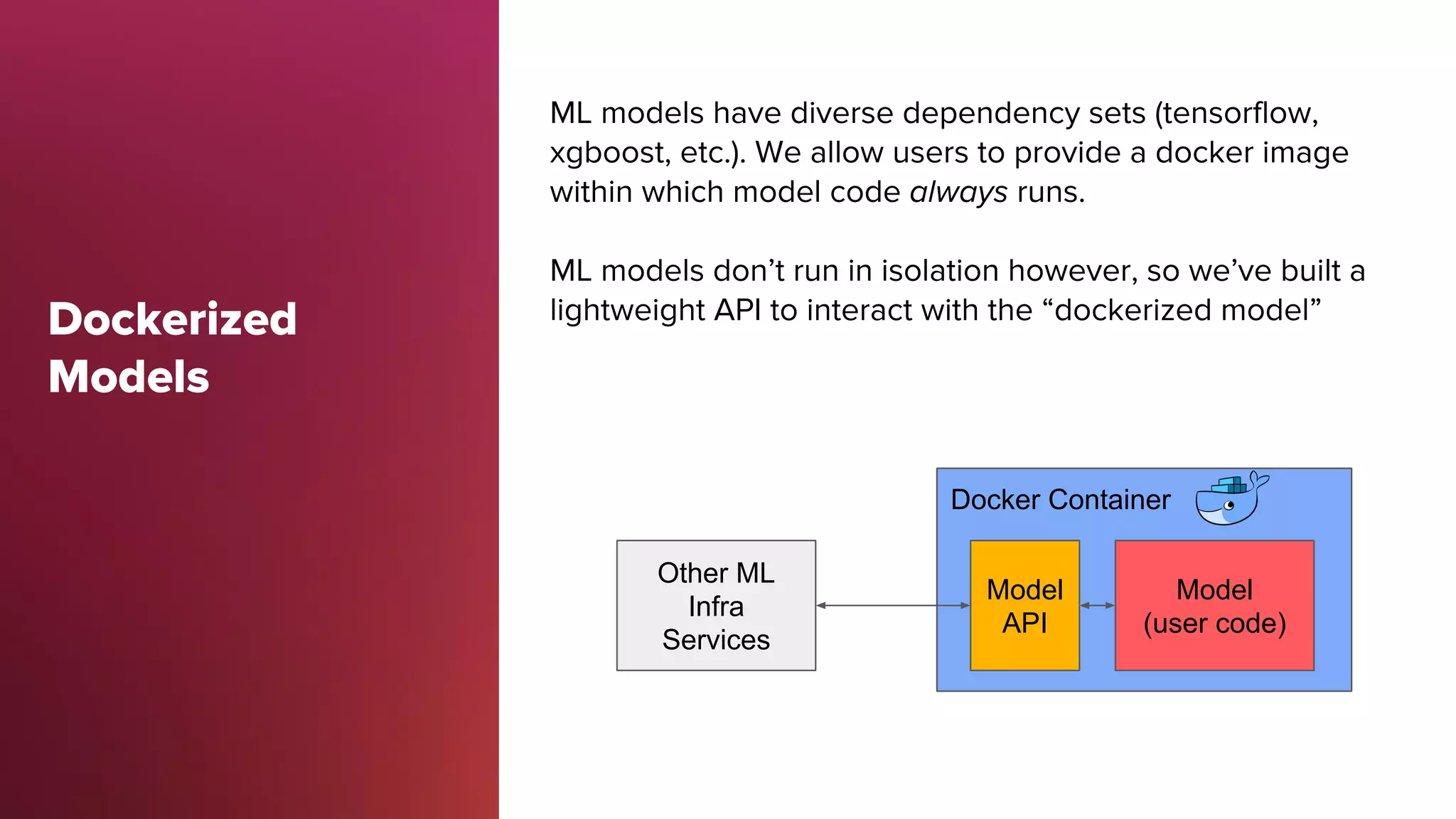
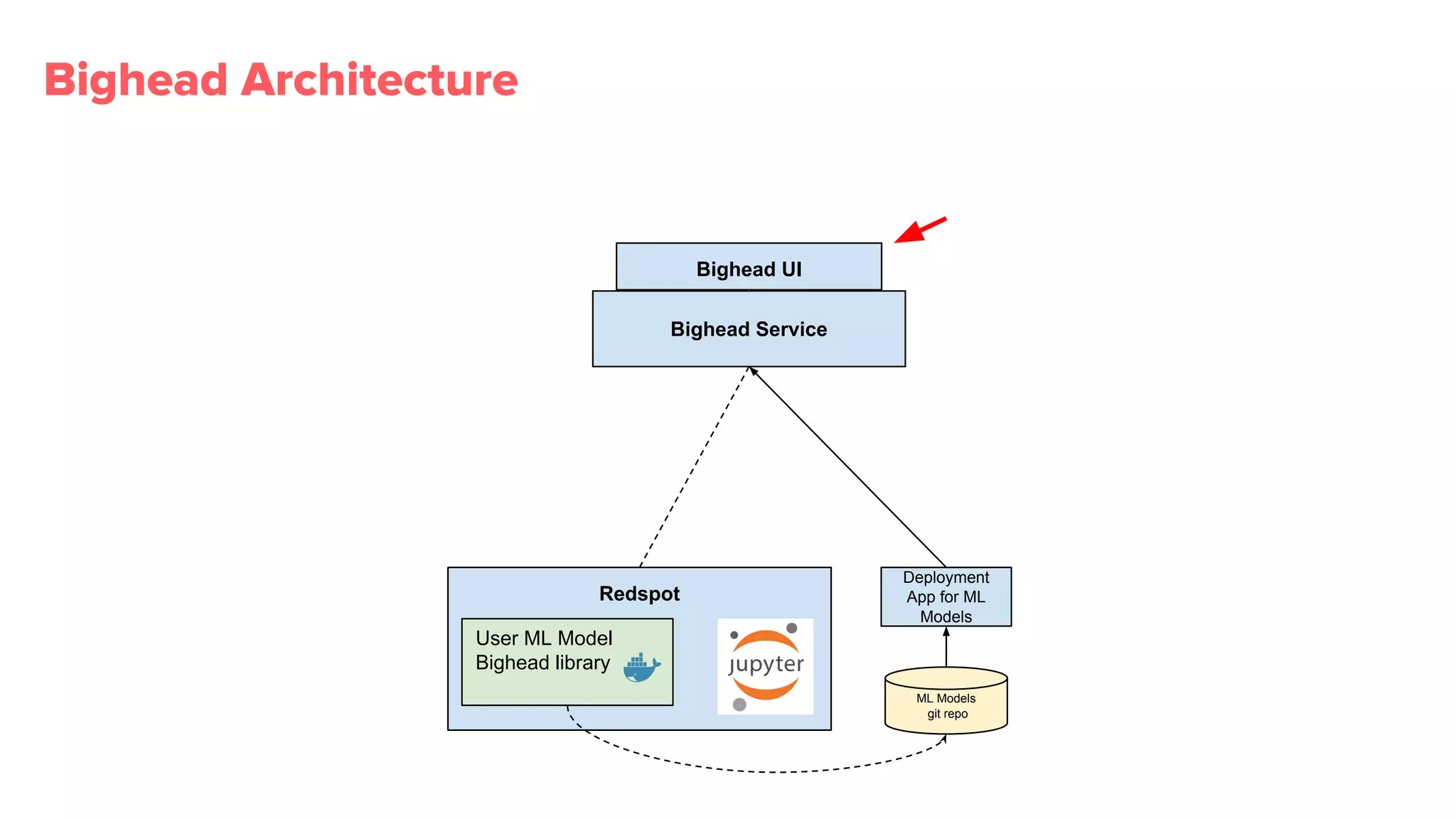
Overview of Bighead architecture including components like Docker, data management, and modular frameworks.Zipline addresses data quality checks and feature sharing, with inefficient existing processes in ML data management.
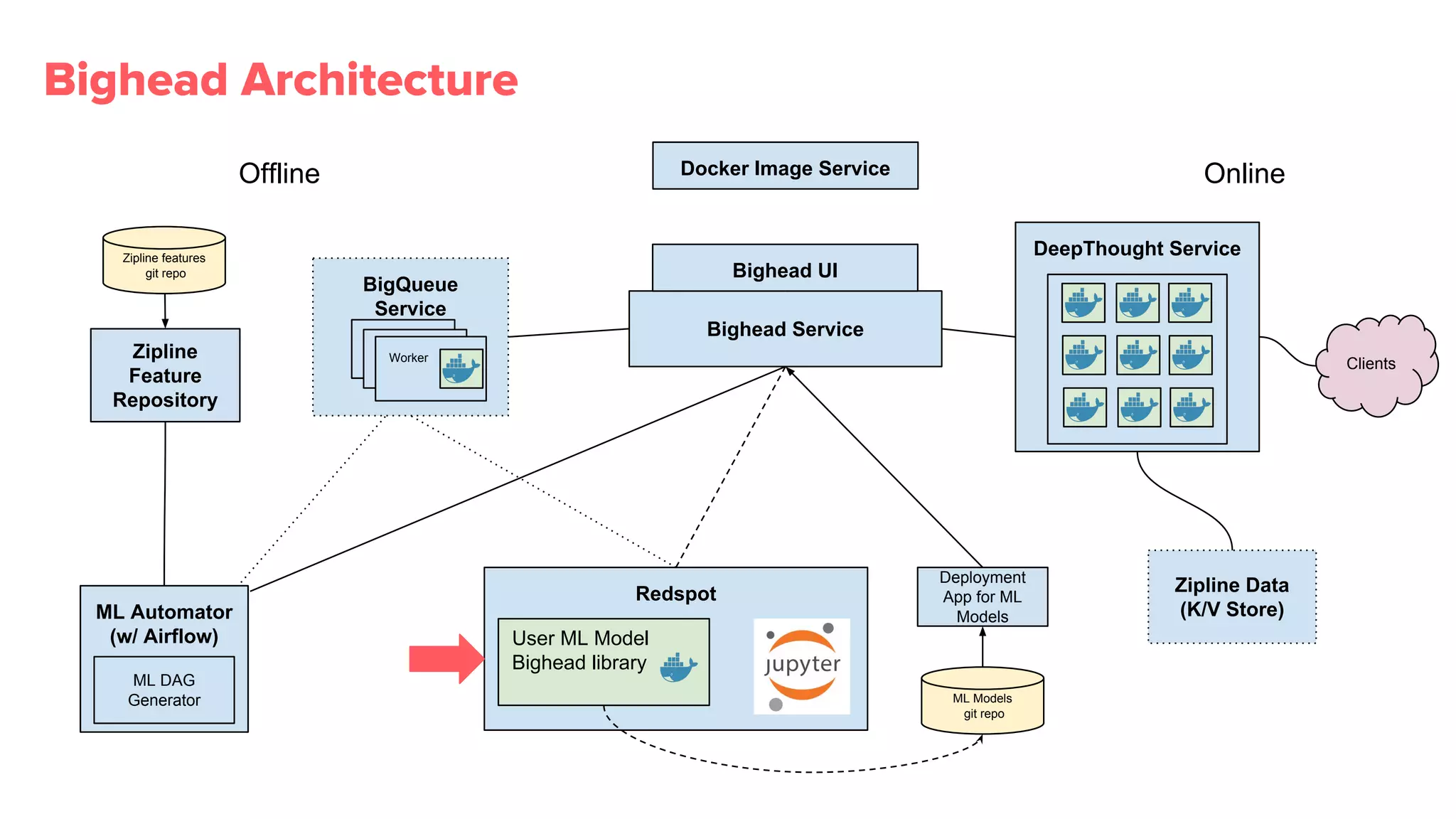
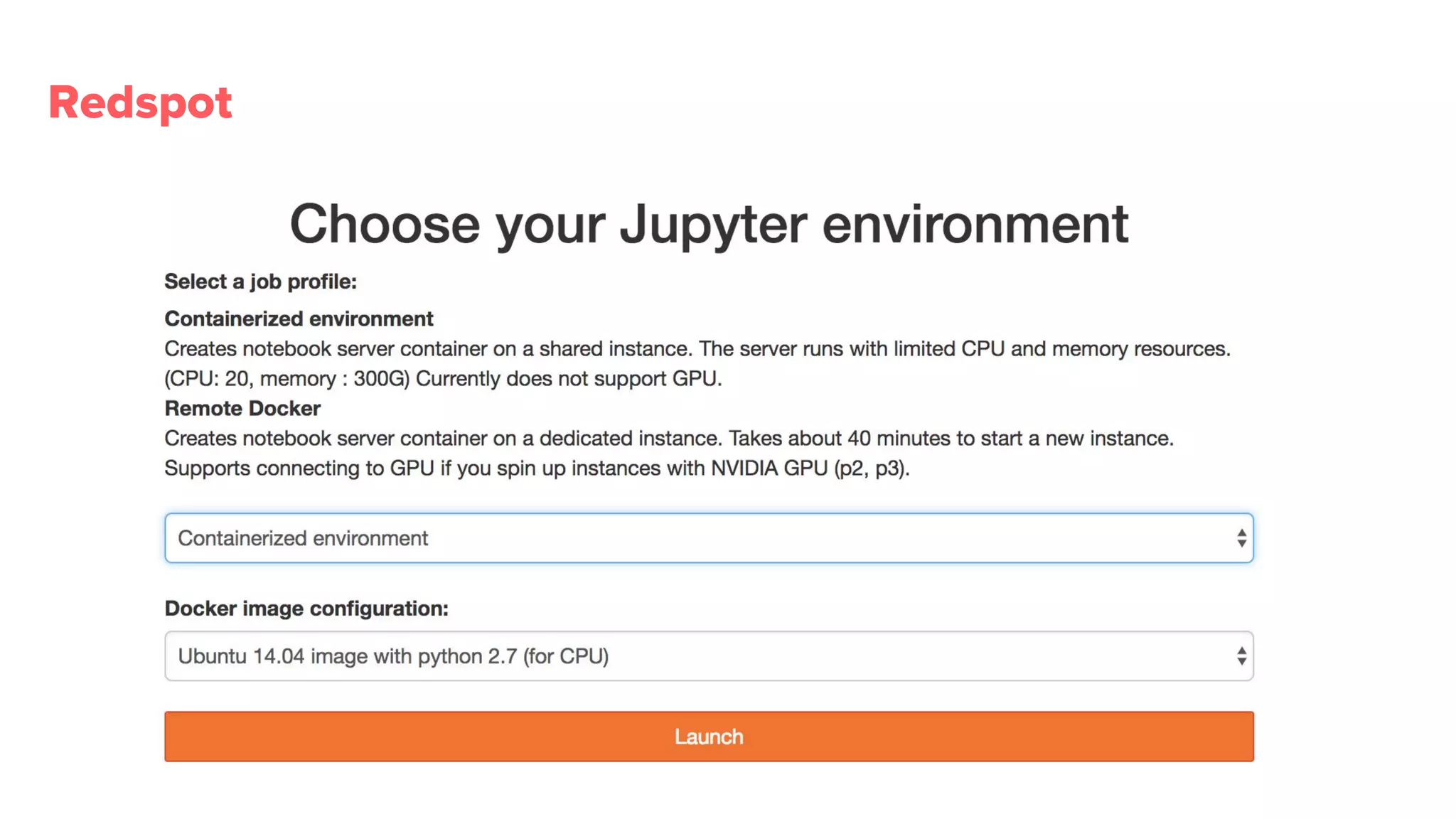
Redspot provides a containerized Jupyter environment for better reproducibility, sharing, and management of ML experiments.
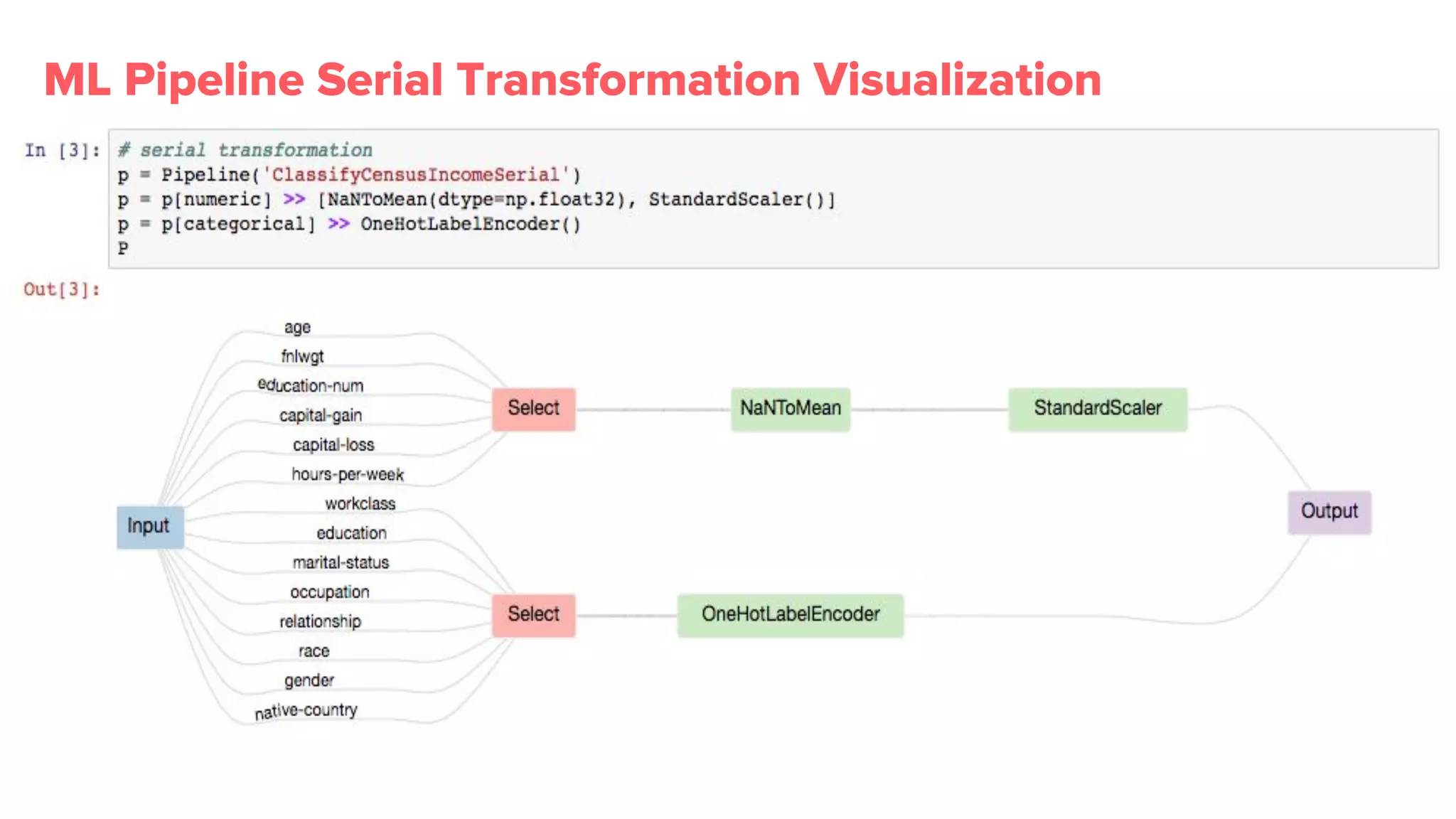
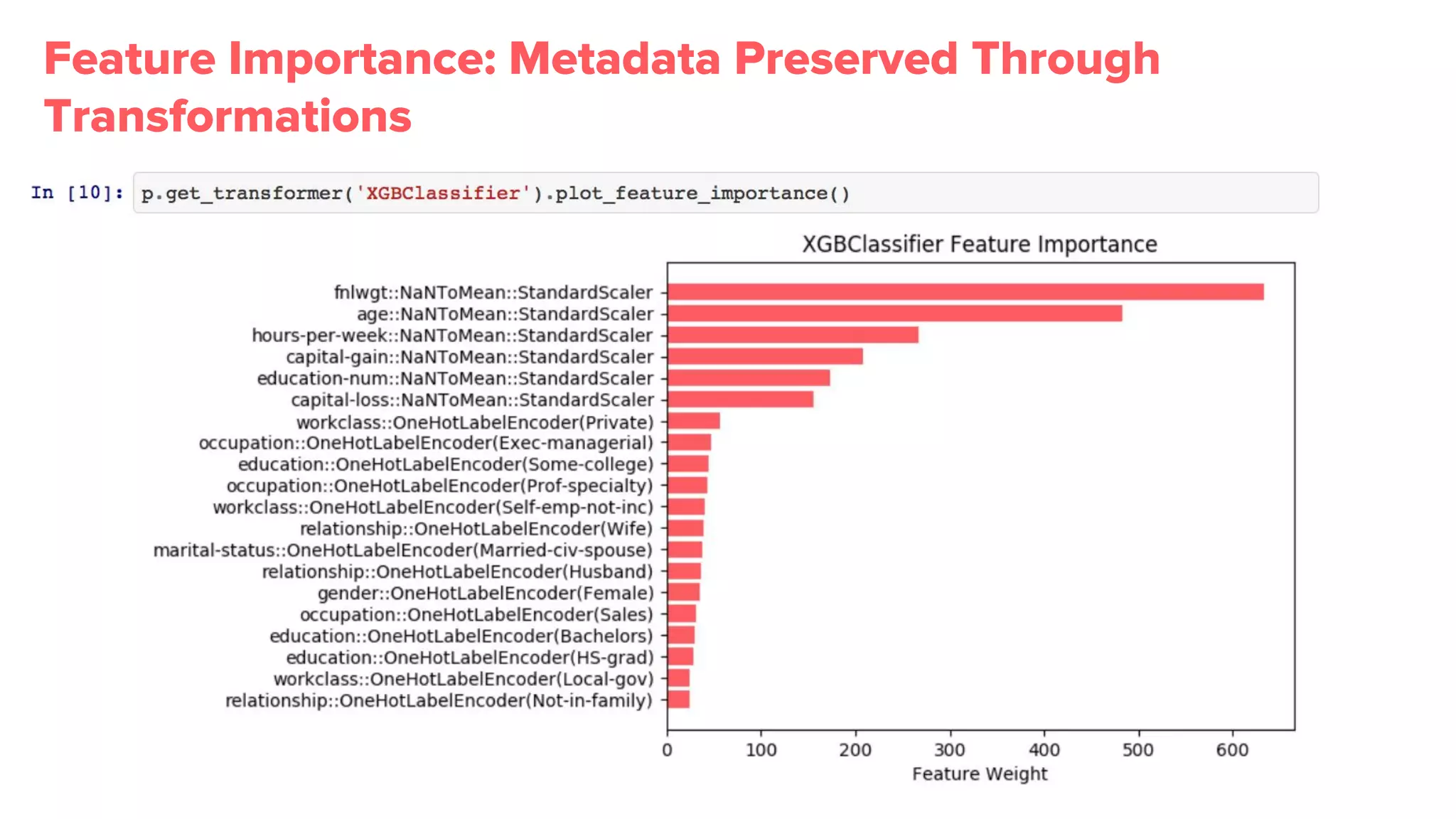
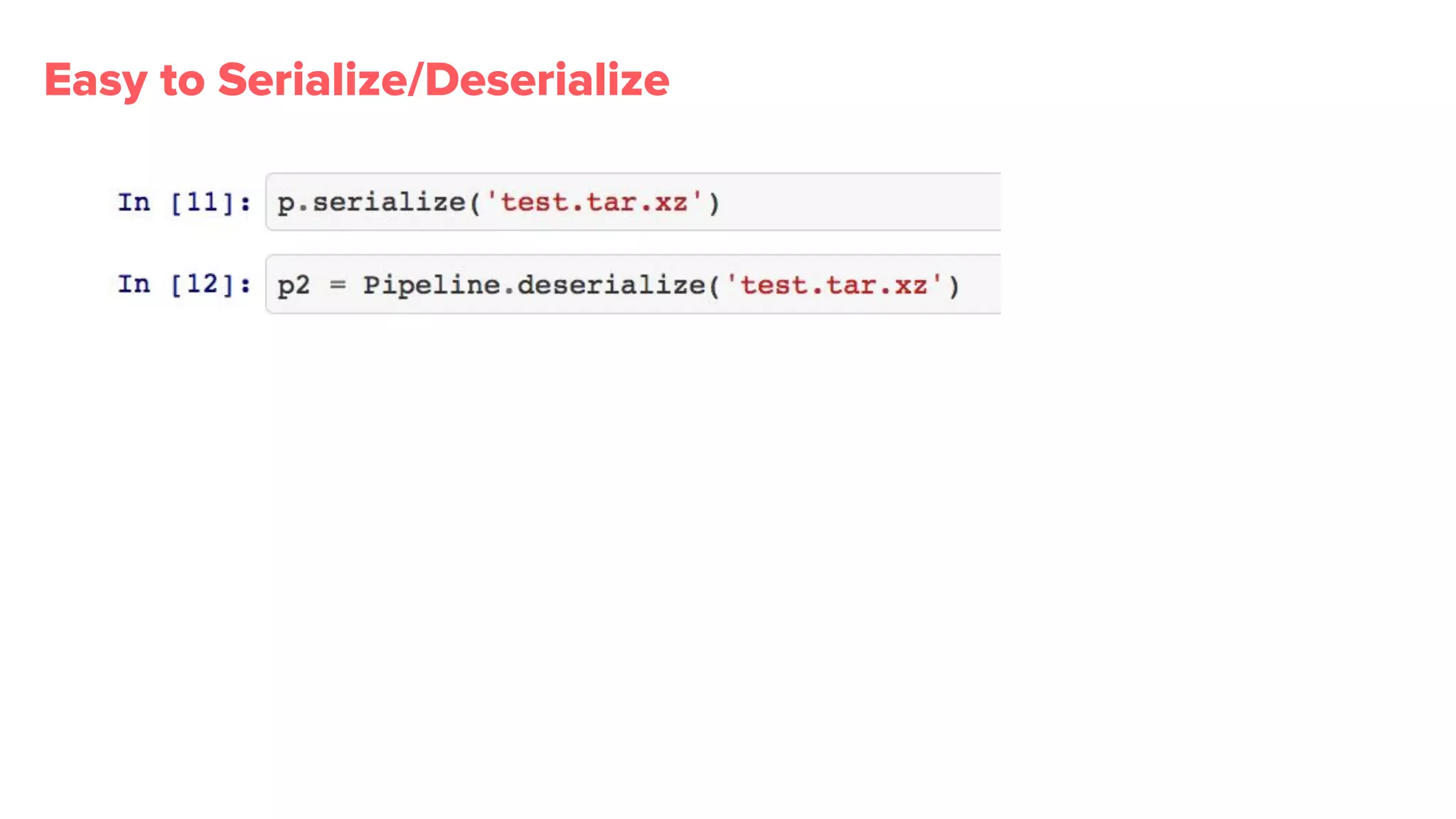
Bighead library provides more than 100 transformations, promotes metadata retention, and visualizations essential for effective pipeline management.
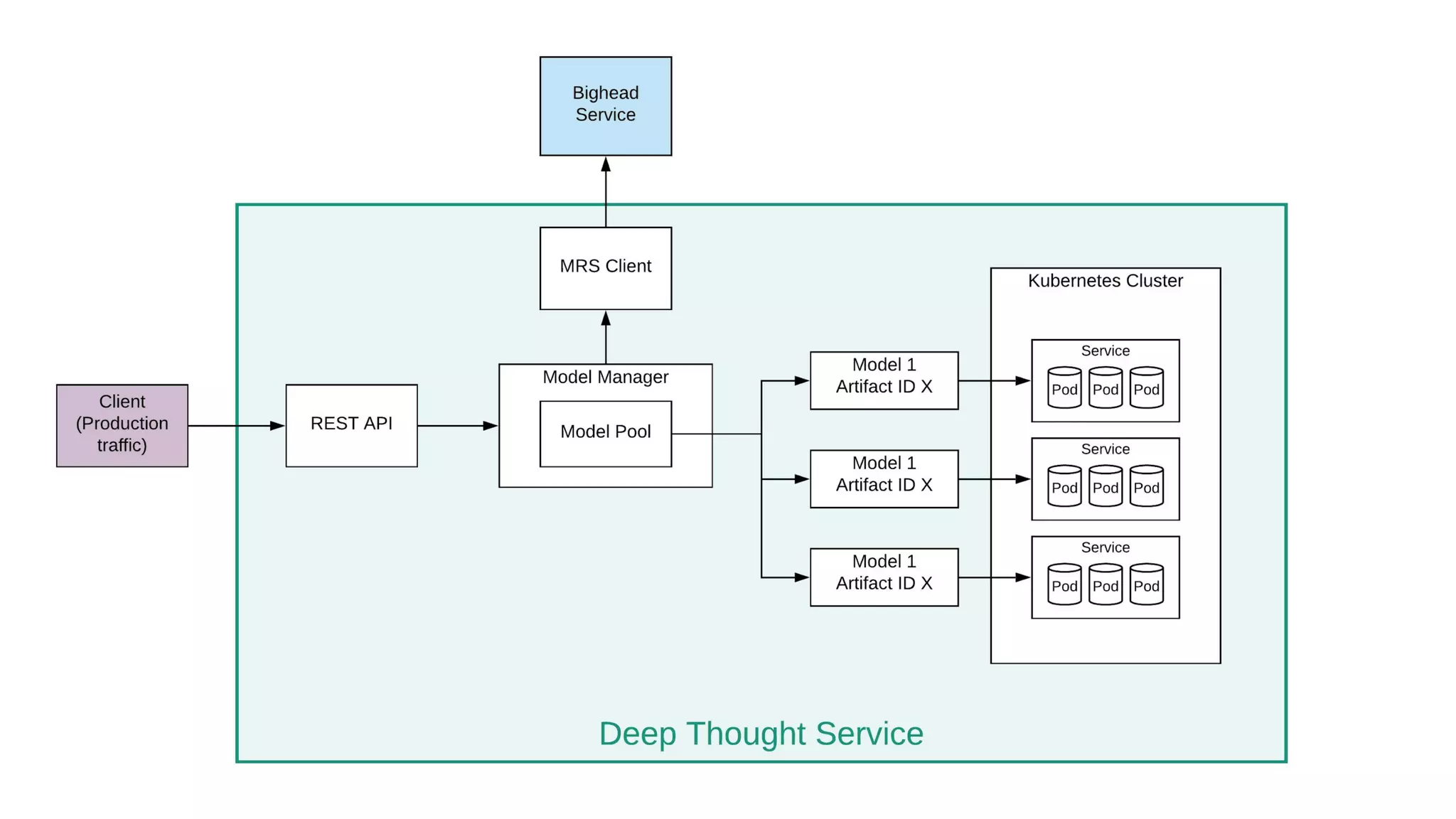
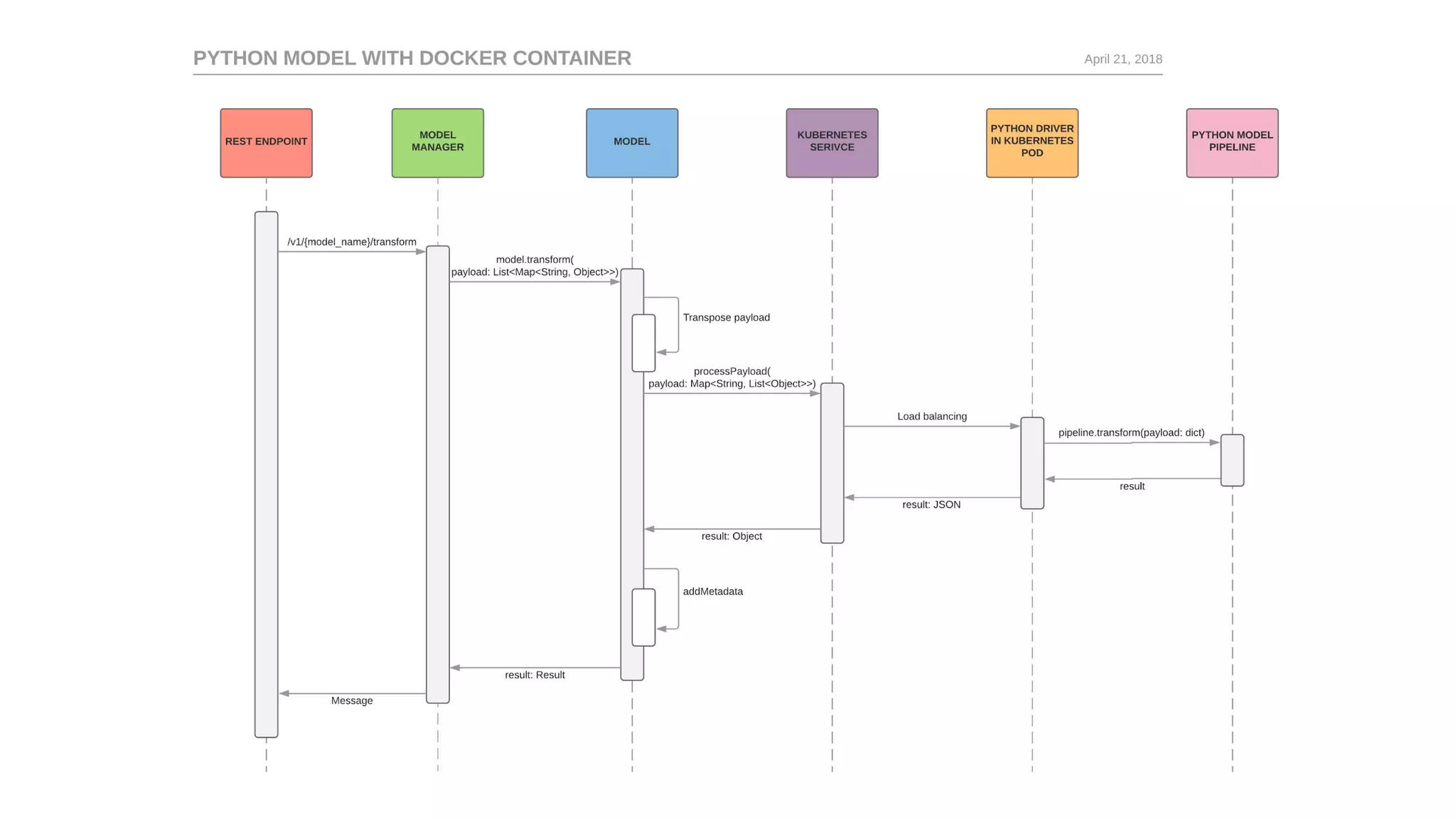
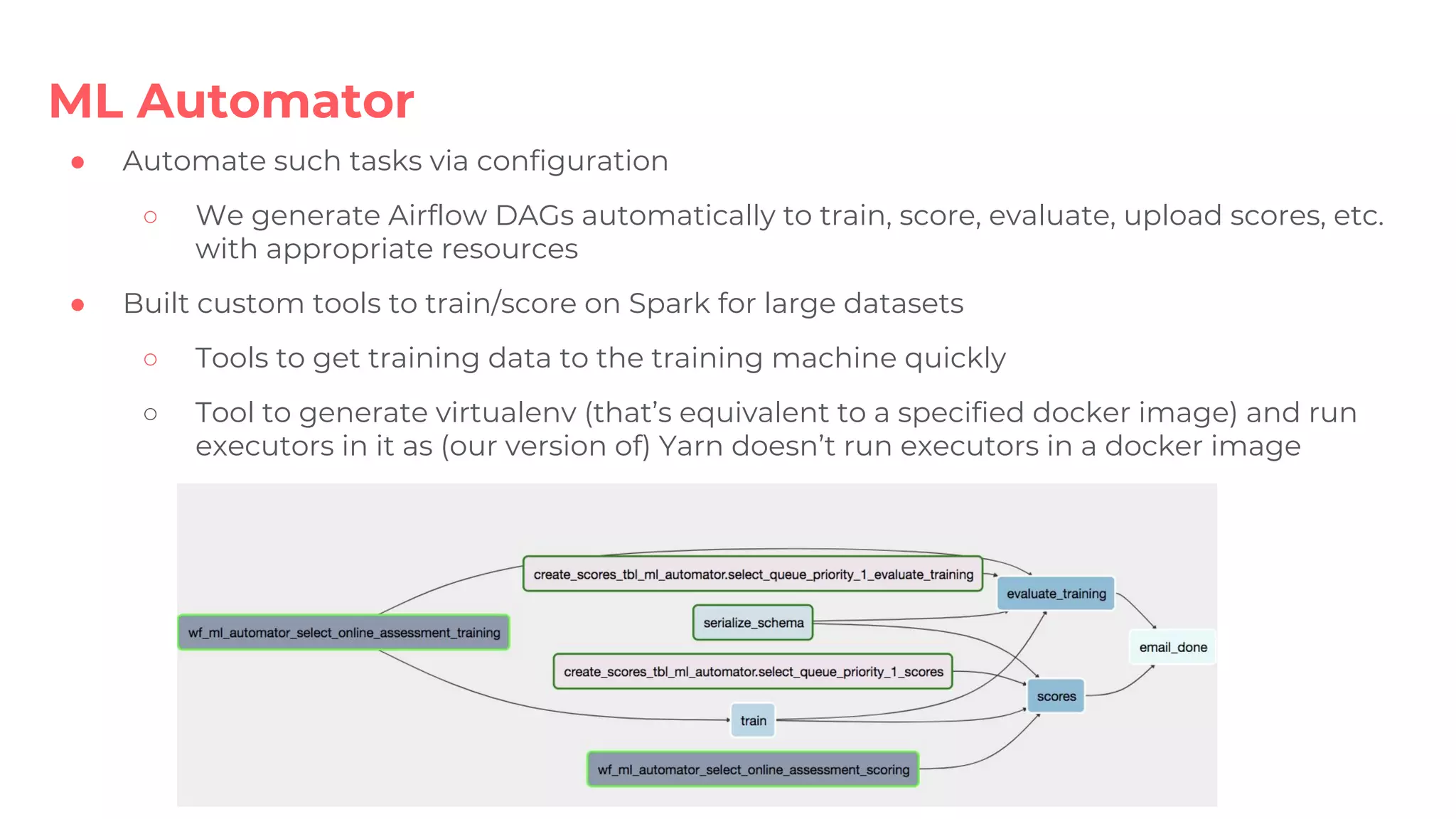
Deep Thought shared service aids online model inference; simplifies new model deployments and ensures consistency in model evaluation.ML Automator automates periodic training and assessment tasks seamlessly via Airflow for efficient resource management.
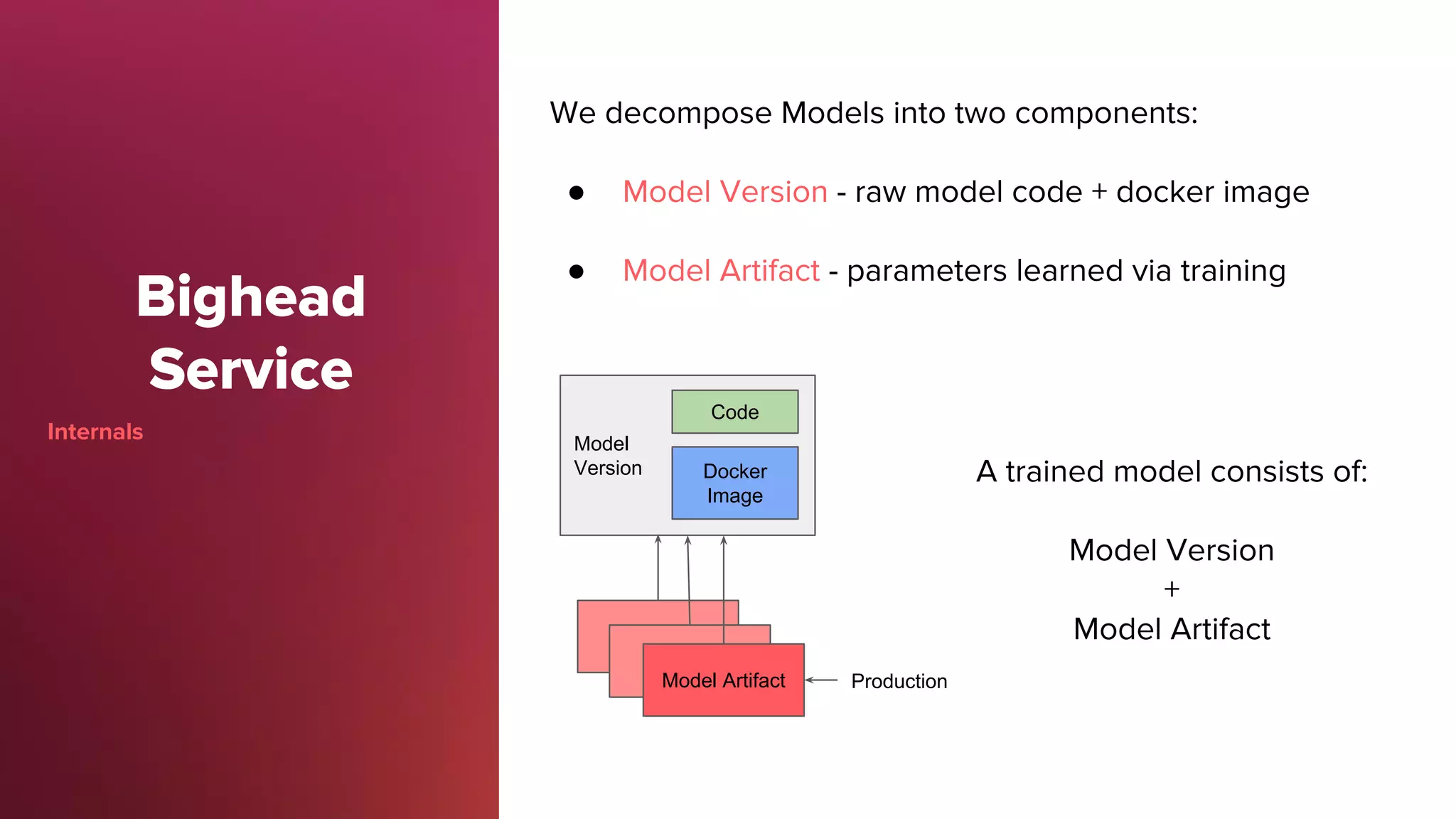
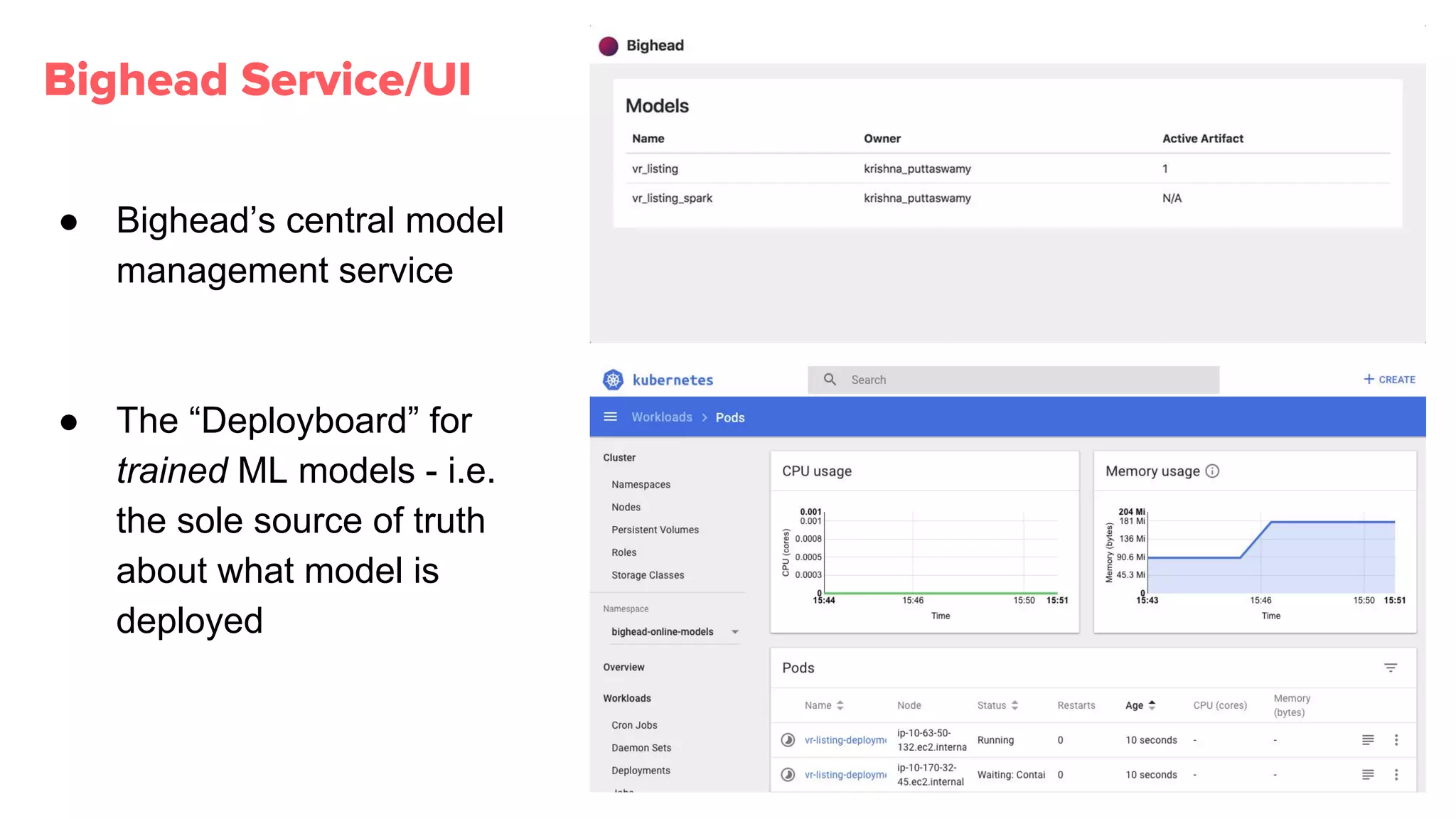
Bighead service manages ML models' life cycles, ensuring proper version control, reproducibility, and holistic health monitoring.
Summary of end-to-end ML model management platform and plans to open source the technology for broader collaboration.























































































