Downloaded 13 times

































![MLflow and ONNX Keras Example
39
import mlflow.onnx
import onnxmltools
onnx_model = onnxmltools.convert_keras(model)
mlflow.onnx.log_model(onnx_model, "onnx-model")
Log Model
Read and Score Model
import onnxruntime
session = onnxruntime.InferenceSession(model.SerializeToString())
input_name = session.get_inputs()[0].name
predictions = session.run(None, {input_name:
data_np.astype(np.float32)})[0]](https://image.slidesharecdn.com/onnxandmlflow20200226-200227233920/85/ONNX-and-MLflow-39-320.jpg)


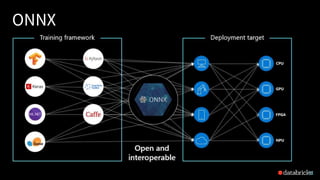
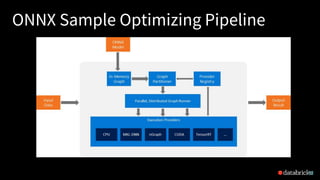
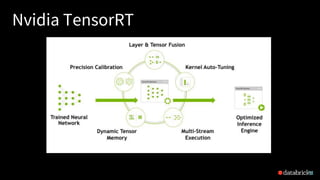
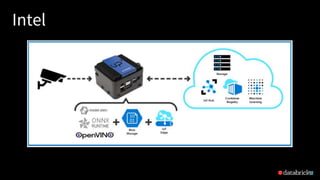
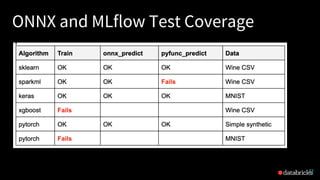
This document discusses ONNX (Open Neural Network Exchange) and its integration with MLflow for model portability and deployment. It provides an overview of ONNX, describing how it allows models to be trained in one framework and deployed in another. It then discusses several companies that support ONNX, including Microsoft's use of ONNX Runtime to accelerate models across various products, AWS and Nvidia's support, and Facebook and Intel's contributions. The document ends by explaining how MLflow recently added support for the ONNX format, allowing models to be exported to and loaded from ONNX.



















![[Machine Learning 15minutes! #61] Azure OpenAI Service](https://cdn.slidesharecdn.com/ss_thumbnails/20211127ml15minazureopenaiservice-211206154233-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[第35回 Machine Learning 15minutes!] Microsoft AI Updates](https://cdn.slidesharecdn.com/ss_thumbnails/20190427ml15minmicrosoftai-190427060706-thumbnail.jpg?width=640&height=640&fit=bounds)





























